SAMPLE SURVEY DESIGN AND ANALYSIS:
A COMPREHENSIVE THREE-DAY COURSE
LECTURE NOTES
DAY ONE: BASIC CONCEPTS OF SAMPLE SURVEY
DAY TWO: HOW TO DESIGN SURVEYS AND ANALYZE SURVEY DATA
DAY THREE: SPECIAL TOPICS / PRACTICAL PROBLEMS IN SURVEY DESIGN
Joseph George Caldwell, PhD (Statistics)
1432 N Camino Mateo, Tucson, AZ 85745-3311 USA
Tel. (001)(520)222-3446, E-mail jcaldwell9@yahoo.com
Updated November 9, 2016
Copyright © 1980 - 2016 Joseph George Caldwell. All rights reserved.
*Contents
6. Resume of Course Developer 23
7. Day 1: Basic Concepts in Sample Survey. 28
7.1 Basic Concepts in Sample Survey. 30
7.2 Simple Random Sampling. 65
7.3 Stratified Random Sampling. 77
8. Day 2: How to Design Surveys and Analyze Survey Data. 106
8.2 General Procedure for Designing a Descriptive Sample Survey. 118
8.3 When and How to Use Simple Random Sampling. 126
8.4 When and How to Use Stratified Sampling. 128
8.5 When and How to Use Cluster Sampling. 139
8.6 When and How to Use Systematic Sampling. 146
8.7 When and How to use Multistage Sampling. 147
8.8 When and How to Use Double Sampling. 155
8.9 How to Resolve Conflicting Multiple Survey Design Objectives. 156
8.10 Review of Regression Analysis. 157
8.11 General Procedure for Designing an Analytical Survey. 164
8.12 Illustration of Methods for the Design of Analytical Surveys. 168
8.13 Standard Estimation Procedures for Descriptive Surveys. 176
8.14 Standard Estimation Procedures for Analytical Surveys. 184
8.15 Computer Programs for Analysis of Survey Data; Outline of Topics for Day 3. 186
9. Day 3: Special Topics / Practical Problems in Survey Design. 188
9.1 Survey Design for Monitoring and Evaluation. 190
9.2 Instrumentation, Data Collection, and Survey Field Procedures. 219
9.3 Preparation of OMB Clearance Forms, Confidentiality and Privacy Issues. 227
9.5 Sample Frame Problems. 235
9.6. Sampling for Rare Elements. 236
9.7 Treatment of Nonresponse. 237
9.10 Random Digit Dialing. 241
9.11 Major National and International Surveys. 242
9.12 Statistical Software. 245
9.13 Survey Documentation. 246
1. Introduction
This document presents notes for the course, Sample Survey Design and Analysis: A Comprehensive Three-Day Course, by Joseph George Caldwell. This course presents material on descriptive, or design-based, sample survey, not on analytical, or model-based, sample survey. Descriptive sample survey is appropriate for applications such as monitoring, in which it is desired to construct a description of a population of interest. Analytical sample survey is appropriate for applications such as program evaluation, where it is desired to estimate the causal effect of a program intervention (e.g., the economic impact of an economic development program, or the effectiveness of a public-health campaign). Analytical sample survey design and analysis is discussed briefly in this presentation, but is addressed in detail in a separate presentation.
These notes are intended to accompany a lecture, using a board or projector to augment the oral presentation. They have been prepared so that the student may listen to the presentation without having to take notes.
The lecture is accompanied by examples and handouts, which are not included in these notes.
The course also includes in-class student exercises.
The complete course may be covered in three six-hour days (three hours in morning, three hours in afternoon), or in five half days (three and one-half hours per day). The split-up sessions are intended to accommodate clients whose employees would find it inconvenient or impractical to allocate an entire day, or three days in sequence, to a course. Concise versions of the course are available (fewer days or fewer hours per day).
The course is intended for any class size, but a smaller class size (e.g., 10-30 students) is better for interactive discussion (responses to student questions, clarifications, additional examples).
The topics covered in the three-day course are:
Day 1: Basic concepts of sample survey
Day 2: How to design surveys and analyze survey data
Day 3: Special topics; practical problems in survey design
In Day 1, basic principles of statistics and sampling theory are presented and the major types of sample design are described, and the rationales for selecting each type of design are discussed. Day 2 is concerned with the problem of constructing a design of each major type (i.e., determining sample sizes and sample selection methods). Day 3 is concerned with introduction to a number of special topics.
The level and scope of the course; managing expectations
This course is an introductory course on the design and analysis of descriptive sample surveys. It assumes that the student has taken a prerequisite course in “college math,” but it does not require prior knowledge of calculus. For students having knowledge of calculus (or some background in probability and statistics, say from an elementary course in statistics), some additional information is presented. This additional material is marked with the notation optional. These optional sections (few in number) are omitted from the course presentation.
Attendees should be somewhat familiar with basic statistical concepts, such as probability, the mean and variance of a distribution, the normal distribution, the binomial distribution, estimation and hypothesis testing, confidence intervals, and regression and correlation. Needed material from these topics is reviewed, but this review is not sufficient background for a person having no previous knowledge of probability or statistics. Ideally, a person attending this course would have previously taken an elementary course in statistics. A person with no previous training in statistics could follow much of the lecture, but it would be expecting a lot to absorb the basic concepts of statistics “on the fly,” in addition to the material specific to sample survey.
This course is intended to cover a broad range of topics in descriptive sample survey design. To do so, it does not cover each topic in great detail. The concern is with known results and how to apply them, not in proving them.
The course is introductory and elementary, but relatively comprehensive, and certainly intensive. At the end of the course, a person with some mathematical ability should be able to recognize which basic type of sampling is appropriate in a given situation, be able to estimate the sample size required to produce a specified level of precision, and be able to conduct standard analyses of the collected sample data.
There is no way, however, that a three-day course will make an “instant survey statistician” out of anyone. In a survey design situation that is complex or that will involve large amounts of time, effort, or money, the advice of an expert sample survey statistician should be sought.
The course is basically conceptual, with some time spent on working through detailed examples, including numerical calculation of formulas. Someone wishing to construct an actual survey design and analyze the survey data would likely want to consult a reference text to review detailed examples and gain expertise by working through exercises.
This course is an ideal introduction for a project director or government technical (project) officer who wishes to understand the basic concepts of sample survey in order to effectively manage or monitor a project involving sample survey. With the background of this course, the project manager should be able to sense what type of survey design is appropriate in a given situation, and be able to converse meaningfully with a consulting survey statistician on a project involving a sample survey.
The course has been presented a number of times, both on an “advertised” basis at commercial hotels, and on an “in-house” basis at the US Bureau of Labor Statistics. Overall, the evaluation sheets returned by course attendees have been very favorable, but in a few instances it was attended by persons with limited mathematical background and in those cases the material was considered too complicated. While it is possible to present a course on sample survey with virtually no reference to mathematical symbology, such a course would not be of use to a person who actually wanted to design a survey and analyze survey data. This course is not a “no-math” course. While it is elementary and introductory and does not require knowledge of calculus, it does require some familiarity with mathematics at the “college math” level. Persons with little mathematical background could attend the course and understand much of the lecture material, but they would be unable to follow the mathematical formulas and work out numerical examples.
No one likes unpleasant surprises. One of the purposes for publishing these notes on the Internet is so that prospective students may quickly peruse them and assess whether the material is too advanced for them, given their present background in mathematics.
The course covers a lot of material in a short time. These notes will enable the student to pay attention to the lecture without having to take notes. It is not expected that everything will “sink in” in a three-day course, and it is recommended that the student who wishes to apply the techniques in practice acquire a reference text for study, or attend a formal course in which many homework exercises will “fix” the concepts.
Each attendee to the course is asked to complete a course evaluation. One of the questions asked is whether the course should spend less time on many topics (as it does), or concentrate on a small number of designs. The overwhelming response from attendees is that they liked the course as it is – a broad overview of many topics, with less time spent on any particular design or topic.
The course is comprehensive, but it is certainly not exhaustive. It provides an introduction to the major aspects of descriptive sample survey design and analysis. There are many specialized topics that it does not cover, and it does not address every possible combination of survey design elements. For example, it includes stratified sampling and ratio estimation, but does not include stratified sampling with ratio estimation – the student is referred to a reference text for the information on that particular combination. Also, the course includes cluster sampling and stratified sampling, but it skips discussion of stratified cluster sampling.
These notes are available for review by anyone considering enrolling in the course. The notes do not contain all of the exercises, examples, and handouts that are included in the presentation.
It is not expected for the student to memorize the various formulas presented, but it is expected that some of the major ones would be familiar and recognized, by the end of the course (e.g., the formulas for a mean, a variance, a weighted average, and a confidence interval). A certain amount of course material (e.g., examples, supplementary material, details) is included as “background,” to place the essential concepts in context. It is not expected that the student remember all of the material presented, and the really important concepts will be identified and stressed.
In a usual academic course, the material covered here would be written out by the professor, over the course of 16 one-hour class sessions. If all of the material covered here were written out, it would not be possible to cover it in a three-day course. Hence, in addition to obviating the need for taking notes, the course notes enable much more material to be covered than would be possible in a usual course. It is recognized that there is a learning advantage to the student’s writing his own notes, but this benefit has been sacrificed in order to cover much material in a short time. The material presented in the notes is available in a variety of reference texts on sample survey. The essential feature of the course is the lecture and in-class interaction, not the notes. The notes are made available simply to enable the student to take full advantage of these aspects.
The course lasts 16-18 hours (Day 3 is usually cut a little short, to accommodate travel arrangements). This is about 1/3 of the class time of a “three-unit” college semester (three hours per week for 16 weeks, or 48 hours). The college course, however, would include substantial amounts of homework, which this course does not include.
Sample survey involves a lot of formulas. There are a number of different designs and estimation techniques, and each of them involves its own formulas (or procedures, such as resampling) for calculating estimates and errors of estimation. These course notes include many formulas, for reference, but not a lot of class time is spent in working with the formulas. They are too many and too complicated to learn well in a three-day course. Most of the class time is spent in discussing concepts, examples, and approaches, not with working through complicated estimation formulas. A few detailed numerical examples will be worked out in the early part of the course, so that the student may become familiar with the computational requirements of the estimation formulas. After that, formulas will be shown in order to illustrate concepts and general forms, but no further calculations will be made using them.
Most persons performing statistical computations would use one of the many available statistical program packages, such as SPSS, SAS, or Stata, and would not perform any computations manually. A number of program packages are identified in the course, but they are not described or discussed in detail. The reason for this is that some of these systems are very expensive, and most firms prefer (for reasons of efficiency and control of quality and cost) for staff to use a single system, not multiple systems. As a result, many course attendees have interest in a single system, and are not interested in examples constructed using other systems.
Note on course content. If presented on an advertised basis (individual enrollments), the course follows these notes closely. If presented for a single client, the content may be modified somewhat to suit the client’s interests or time constraints. For example, an overseas client may have no interest in information about the process for obtaining OMB approval for a questionnaire to be used in a survey funded by the US government, and may wish for more time to be spent on examples.
The pace of the course, the selection of topics, and the time spent on various topics may be adjusted a little by the instructor, in order to address specific concerns or interests of the students.
While these notes parallel the lecture, not every item included in the notes is necessarily included in the lecture, and not every item included in the lecture is included in the notes. The notes are intended to reduce the requirement for the student to take copious notes during the lecture. They are not intended to be a detailed recording of the lecture. For additional detail and examples, the student should consult a sample survey reference textbook and documentation of a statistical program package. A very basic book on descriptive sample survey is Elementary Survey Sampling, 7th edition, by Richard L. Scheaffer, William Mendenhall, R. Lyman Ott and Kenneth G. Gerow (Cengage Learning, 2011). A more advanced book is Sampling: Design and Analysis, 2nd edition, by Sharon L. Lohr (Cengage Learning, 2009). The latest editions of these books are expensive, but earlier editions, which would be fine as complements to this course, are generally available at reasonable cost.
This course focuses mainly on estimation (point and interval estimation), not on hypothesis testing. The reason for this focus is that in sampling from finite populations, subpopulations almost always have different parameters, and so the test of the hypothesis of equality of parameters is irrelevant. We do consider hypothesis testing in applications of sample survey to evaluation, where the assumption of a conceptually infinite population (which produced the particular finite population) is reasonable. An introduction of sample survey in monitoring and evaluation is addressed in Day 3 of the course. Detailed discussion of analytical (model-based) design and analysis (for impact evaluation) is presented in a separate course.
(A similar situation (regarding finite and infinite populations) occurs in the field of statistical quality control. On the one hand, we may be interested in estimating the percentage of defectives in a particular lot of goods, to decide whether to accept the lot. In this case (acceptance sampling), we are interested in estimating the characteristics of a particular finite population (i.e., the lot). On the other hand, a quality control manager will view this lot as a single sample from the process that generated it and many other lots. In this case, the lot is viewed as a single sample from a conceptually infinite population of lots, and we are interested in estimating the characteristics of this conceptually infinite population.)
In the past, the course was presented by Dr. Caldwell and his colleague, Dhirendra N. Ghosh.
Course Pricing
The course is not longer given on an advertised basis at a commercial facility, but only “in-house” at a client’s facility. The price is negotiated. The estimated price for the course, if conducted over a three-day period at a client’s facility, is USD15,000 plus travel and lodging expense for two people. If the course is conducted over more than three days, the price is estimated at USD 5,000 per day plus travel and lodging expenses..
This price is an all-inclusive price, subject to the following limitations. Half payment is requested in advance, and half payment upon completion. Travel and per diem (meals, lodging and incidental) expense for two course staff are charged in accordance with US Government maximum travel per diem allowances (or international-organization allowances) for the travel (from presenter’s home base to client’s location, time spent at the client’s location, and return to the presenter’s home base).
It is agreed that the client will download the course notes from the Internet website http://www.foundationwebsite.org , and print sufficient copies for all attendees. Note: The Internet version of the course notes does not include all handouts. These supplementary items (as computer files) will be e-mailed to the client prior to the course. If the client does not print the course notes or the supplementary items, the course will be presented without course notes. This is not the intended format, or the format that has been used successfully in the past. As discussed, much material is presented, and it is not possible to write out this material during a three-day course. At the same time, restricting the course to a lecture, without benefit of the notes, would lose much. The course is intended to be a lecture supplemented with the Course Notes.
The client is expected to provide a comfortable environment conducive to learning. If the client does not have suitable accommodations at its own facility, it is recommended that facilities be procured at a local commercial hotel, many of which have excellent facilities for seminars. It is requested that the client provide a computer (with a Microsoft operating system), computer-driven projector and projection screen, for displaying the Course Notes. It is also requested that a medium be provided for ad-hoc classroom presentation by the lecturer. For small groups, this may be a wall board (with chalk or markers) or “flip-chart-and-easel” (with marking pen). For larger groups it is recommended that a “view-graph” projector be available (for displaying writing using markers on clear acetate sheets).
It is requested that the client provide snacks and drinks for the breaks. The client is encouraged to provide lunch to presenters and attendees for full-day sessions, but this is at the client’s discretion. (This was the practice when the course was presented on an advertised basis at a commercial hotel, and it works well (it keeps the class together, and avoids late returns to class after lunch).)
2. Course Schedule
Sample Survey Design and Analysis:
A Comprehensive Three-Day Course
by Joseph George Caldwell, PhD
Course Schedule
Day 1: Basic Concepts of Sample Survey
9:00 - 9:20 Introduction; Course Objectives and Outline; Overview of First Day's Course Content
9:20 -10:00 Review of Basic Statistical Concepts
10:00 -10:30 Simple Random Sampling
10:30 -10:40 Break
10:40 -11:00 Concept of Sample Design
11:00 -11:30 Stratified Sampling
11:30 -12:00 Stratified Sampling
12:00 - 1:00 Lunch
1:00 - 1:30 Cluster Sampling
1:30 - 2:00 Systematic Sampling
2:00 - 2:30 Multistage Sampling
2:30 - 2:40 Break
2:40 - 3:10 Multistage Sampling
3:10 - 3:40 Double Sampling
3:40 - 4:00 Survey of References; Outline of Topics for Second and
Third Days; Questions and Answers
Day 2: How to Design Surveys and Analyze Survey Data Part One: How to Design Descriptive Surveys
9:00 - 9:15 Overview of Second Day's Course Content; The Elements
of Survey Design; Distinctions between Descriptive and
Analytical Surveys
9:15 - 9:30 General Procedure for Designing a Descriptive Sample Survey
9:30 - 9:40 When and How to Use Simple Random Sampling
9:40 - 9:50 When and How to Use Systematic Sampling
9:50 -10:30 When and How to Use Stratification
10:30 -10:40 Break
10:40 -10:50 When and how to Use a Clustered Design
10:50 -11:30 When and How to Use a Multistage Design
11:30 -11:40 When and flow to Use Double Sampling
11:40 -12:00 How to Resolve Conflicting/Multiple Survey Design Objectives
12:00 - 1:00 Lunch
Part Two: How to Design Analytical Surveys
1:00 - 1:30 Review of Regression Analysis
1:30 - 1:45 General Procedure for Designing an Analytical Survey
1:45 - 2:00 How to Use Multiple Stratification for an Analytical Design
2:00 - 2:30 How to Use Controlled Selection for an Analytical Design
2:30 - 2:40 Break
Part Three: How to Analyze Survey Data.
2:40 - 3:20 Standard Estimation Procedures for Descriptive Surveys
3:20 - 3:40 Standard Estimation Procedures for Analytical Surveys
3:40 - 4:00 Computer Programs for Analysis of Survey Data; Outline of
Topics for Third Day
Day 3: Special Topics/Practical Problems in Survey Design
9:00 - 10:00 Survey Design for Monitoring and Evaluation
10:00 - 10:30 Instrumentation, Data Collection, and Survey Field
Procedures
10:30 - 10:40 Break
10:40 - 11:00 Preparation of OMB Clearance Forms
11:00 - 11:15 Longitudinal Surveys
11:15 - 12:00 Sample Frame Problems
12:00 - 1:00 Lunch
1:00 - 1:15 Sampling for Rare Elements
1:15 - 2:00 Treatment of Nonresponse
2:00 - 2:30 Nonsampling Errors
2:30 - 2:40 Break
2:40- 3:00 Randomized Responses
3:00 - 3:15 Random Digit Dialing
3:15 - 3:45 Major National Surveys
3:45 - 4:00 Questions and Answers
3. Course Syllabus
Sample Survey Design and Analysis:
A Comprehensive Three-Day Course
by Joseph George Caldwell, PhD
Course Syllabus
Day 1: Basic Concepts of Sample Survey
1. Introduction
· Course Objectives and Outline
· Overview of First Day's Course Content
2. Concepts of a statistical distribution (mean, variance, percentiles; examples: normal, binomial)
3. Types of sampling
· Purposive (judgment)
· Haphazard
· Quota
· Probability Sampling
4. Concepts of statistical inference from samples
· Sample
· Estimators of population parameters (measures of central tendency; other parameters (e.g., p))
· Properties of estimators: variance, bias; precision vs. trueness; accuracy (mse)
· Central limit theorem
· Sample moments vs. population moments
· Distribution of sample statistic vs. population distribution
5. Simple random sampling
· When to use
· Now to select a sample
o Target population, sampling population, sampling frame
o Random numbers -- how to use, generated vs. tabled
o Systematic Sampling (from randomly ordered files)
o Sampling with and without replacement
· Types of Estimators
o Simple
o Ratio
o Regression
o Bayes (mention)
o Resampling (Jackknife, Bootstrap) (mention)
· Variance formulas
· Variance estimates
o Formulas
o Resampling (mention)
· Sampling for means vs. sampling for proportions
· Confidence intervals
· Determining sample sizes
6. The concept of sample design
· Precision/cost ratio; design effect
· Ways of departing from simple random sampling
o Variations in the probability of selection
o Dropping the independence assumption (systematic, cluster, replacement, controlled selection, matching)
· Optimal design
· Auxiliary variables
o Correlated with variables of interest
o Cost information
7. Stratified sampling
· Description
· When to use
· How to select sample
· Estimation formulas
· Self-weighting case
· Variance formulas
· Variance estimates
· Construction of strata
· Multiple stratification
· Stratification to the limit
· Cross-stratification
· Certainty stratum
· Optimal allocation
· Determination of sample size
· Stratification when the variable of stratification is inaccurate
· Post-stratification
8. Cluster sampling
· Description
· When to use
· Intracluster correlation coefficient
9. Systematic random sampling
· Description
· When to use
· How to select sample (integer sampling interval, noninteger sampling interval; random start; random starts)
· Estimation formulas
· Variance formulas
· Variance estimation (paired selections, successive differences)
· Replicated subsamples
10. Multistage sampling
· Description
· When to use
· Intracluster correlation coefficient
· Estimation formulas
· Self-weighting sample
· Methods of sample selection
o 1st stage: PPS, PPMS, equal probs., w/rep, wo/rep
o 2nd stage: fixed sample size, variable sample size
o self-weighting
§ 1st -- PPS, 2nd -- equal probs. (advantages/disad.)
§ 1st -- equal, 2nd -- proportional (adv./disadv.)
· Impact of ICC on selection method
o If rho fixed (e.g., equal-sized units)
o If rho variable (e. g., variable-sized units)
· PPS selection
· Certainty stratum
· Variance formulas
· Variance estimation
· Systematic selection ok for 2nd stage units under certain circumstances
· RHC method for sampling wo replacement
· Determination of sample size (design)
o First stage
o Second stage
· Need frame only for lst stage units and selected 2nd stage units
· Generalized variances (mention)
· PPMS
11. Two-phase (double) sampling
· Description
· When to use
· Estimation formulas
· How to select sample
· Variance formulas
· Estimation of variance
· Determination of sample size (1st and 2nd phases)
12. Survey of References; Outline of Topics for 2nd and 3rd Days; Questions and Answers
Day 2: How to Design Surveys and Analyze Survey Data
Part One: How to Design Descriptive Surveys
1. Introduction
· Overview of Second Day's Course Content
· The Elements of Survey Design
· Distinctions between Descriptive and Analytical Surveys
2. General Procedures for Designing a Descriptive Survey
· Specify population of interest
· Define estimates of interest
· Specify precision objectives of survey; resource constraints
· Specify other variables of interest
· Develop instrumentation
· Develop sample design
· Determine sample size and allocation
· Specify sample selection procedures
· Specify field procedures
· Specify data processing procedures
· Develop data analysis plan
· Outline report
3. When and How to Use Simple Random Sampling
· Nature of situation which warrants use of simple random sample
· How to select a simple random sample
· Sampling without replacement
· How to select a simple random sample without replacement
4. When and How to Use Systematic. Sampling
· Reasons for using systematic sampling
· Nature of situation which warrants use of systematic sampling
· How to select a systematic sample
5. When and How to Use Stratification
· Nature of situation which warrants use of stratified sampling
· The use of a certainty stratum
· How to determine the number of strata, and the stratum boundaries
· Stratification to the limit
· Collapsed strata
· Post-stratification
· Errors in classification
· Multiple stratification: cross stratification
· Multiple stratification: nested stratification
· How to allocate sample sizes to strata, when costs and variances are known
· How to allocate sample sizes to strata, when costs and variances are unknown
· Self-weighting design
· General recommendations regarding stratification
6. When and How to Use Cluster Sampling
· Nature of situations which warrants use of cluster sampling
· The "cluster" effect
· Determining sample size in cluster sampling (equal-size clusters)
· Variable-size clusters: sampling with probabilities proportional to size (PPS)
· Variable-size clusters: sampling with probabilities proportional to a measure of size (PPMS)
· Stratification of clusters; the use of a certainty stratum of clusters
· Construction of clusters
· Variable-size clusters; determination of sample size
· Replacement vs. non-replacement sampling of clusters
· Situations in which clustering improves precision
· Self-weighting design
· Sample frame considerations
· General recommendations regarding cluster sampling
7. When and how to Use Multistage Sampling (Two-Stage)
· Nature of situation which warrants use of a multistage design
· Determining sample sizes in two-stage sample (equal-sized primary units)
· The use of nonreplacement sampling (equal-size primary units)
· The use of systematic sampling for selection of second-stage units
· Determining sample sizes in two-stage sampling (unequal size primary units, selection with equal probabilities)
· PPS sampling of primary units (unequal-size primary units)
· Determining sample size in PPS sampling
· The use of nonreplacement sampling (unequal-size primary units)
· Stratification of primary units; the use of a certainty stratum
· Self-weighting design
· Sample frame considerations
· General recommendations regarding two-stage designs
8. When and How to Use Double Sampling
· Nature of situation which warrants the use of double sampling
· Determination of sample size in double sampling
9. How to Resolve Conflicting / Multiple Survey Design Objectives
Part Two: How to Design Analytical Surveys
1. Review of Regression Analysis
2. General Procedures for Designing an Analytical Survey
· Sample survey design for analysis
· Essential problems in design of an analytical survey
· Two conceptual approaches to design of analytical surveys
· Methods for the design of analytical surveys
3. Illustration of Methods for the Design of Analytical Surveys
Part Three: How to Analyze Survey Data
1. Standard Estimation Procedures for Descriptive Surveys
· Preliminary analysis
· Planned analysis
· Special analysis
2. Standard Estimation Procedures for Analytical Surveys
· Preliminary analysis
· Planned analysis
· Tests of model adequacy/model revision
3. Computer Programs for Analysis of Survey Data; Outline of Topics for Third Day
Day 3: Special Topics/Practical Problems in Survey Design
1. Survey Design for Monitoring and Evaluation
2. Instrumentation, Data Collection, and Survey Field Procedures
· Selection of Data Collection Procedures
· Questionnaire Development
· Development of Field Procedures (Treatment of Nonresponse, Inplace Interviews vs. Travelling Team, Incentive Payments)
· Pretesting and Pilot Testing
· Editing, Coding, Data Base Design and Development
3. Preparation of OMB Clearance Forms
4. Longitudinal Surveys
5. Sample Frame Problems
6. Sampling for Rare Elements
7. Treatment of Nonresponse
8. Nonsampling Errors
9. Randomized Responses
10. Random Digit Dialing
11. Major National Surveys
12. Questions and Answers
4. Course Critique Form
Sample Survey Design and Analysis:
A Comprehensive Three-Day Course
by Joseph George Caldwell, PhD
Course Critique Form
Dear Participant:
We appreciate your attendance and are interested in your comments in order to improve our course. Please answer the following questions, adding additional comments as necessary, and send the form back in the attached envelope. Thank you.
Date of course_________________ Location of course_______________________________
Course Content
1. How useful do you consider the information?_______________________________
2. Was the material presented in sufficient detail?_____________________________
3. Were there some topics you would have preferred more discussion on? Yes__ No___
If so, which ones?_________________________________________________________
Course Delivery
1. Were the presentations effective?____________________________________________
2. Were the visual aids helpful?___________________________________________
3. Were the course notes sufficiently detailed?________________________________
Facilities
1. Was the seating arrangement satisfactory?_____________________________________
2. Were the meals satisfactory?_________________________________________________
3. Was parking adequate?______________________________________________________
4. Is the location convenient?__________________________________________________
General
1. How did you find out about this course?____________________________________
Brochure in mail_________________
Organizational channels___________
Associate_______________________
Internet_________________________
Other (specify)___________________
2. Did you have sufficient registration time?___________________
3. Did you feel the course was as you expected it to be, from the flyer?
____________________________________________________________________
4. Did you feel the course was as you expected it to be, from the Course Notes (if examined on the Internet)?______________________________________________
5. If from out of town: Did you stay at the hotel where the course was presented? _____
6. This course was presented to provide a broad overview of Sample Survey
Design Techniques. Would you have preferred to concentrate on a few
specific designs?__________________________________________________________
7. Have you ever attended a course on sampling before?
Yes_____ No_____
8. Would you prefer a more detailed course of 5 days,_____
or a less detailed course of 2 days?_____
9. Would you prefer a more advanced course,_____
or a less advanced course?_____
10. Compared to other short courses of which you are familiar, was the cost of this course:
About right______________
Rather high______________
Lower than expected______
11. What additional seminars might you be interested in?
Time Series Analysis, Forecasting and Control________
Biostatistics_______________
Experimental Design________
Quality Control_____________
Evaluation Research________
Introduction to Statistics and Data Analysis____________
Simulation and Modeling______________
Optimization_______________
Other (specify)______________
Additional Comments:_____________________________________________________________
Name (optional)______________________________________________________________
Organization (optional)__________________________________________________________
5. References
Reference List
Sample Survey Design and Analysis
There are thousands of textbooks on statistics, and many on sample survey. Below are some from my personal library. They are somewhat old, but the basic theory has not changed. For recent texts, check a university bookstore or Internet book vendors (Amazon, Barnes & Noble).
Of the following list, I would recommend Mood’s book for an introduction to mathematical statistics, almost any introductory book for an elementary introduction to statistics, Scheaffer’s book for an elementary introduction to sample survey, Lohr's book for a more advanced presentation, Cochran’s book for a detailed mathematical discussion of sample survey, and Kish’s and Des Raj’s books for a somewhat less mathematical discussion.
General statistics (undergraduate-level mathematical statistics)
Mood, Alexander M., Franklin Graybill and Duane C. Boes, Introduction to the Theory of Statistics, 3rd edition, McGraw Hill, 1974
Snedecor, George W. and William G. Cochran, Statistical Methods, 8th edition, Iowa State University Press, 1989
General statistics (less mathematical)
Crow, Edwin L., Frances A. Davis and Margaret W. Maxfield, Statistics Manual: With Examples Taken from Ordnance Development, Dover Publications, 1960
Downie, N. M. and R. W. Heath, Basic Statistical Methods, 4th edition, Harper & Row, 1974
Survey sampling, less mathematical
Scheaffer, Richard L., William Mendenhall, R. Lyman Ott and Kenneth G. Gerow, Elementary Survey Sampling, 7th edition, Cengage Learning, 2011.
Des Raj, The Design of Sample Surveys, McGraw-Hill, Inc., 1972
Kish, Leslie, Survey Sampling, John Wiley & Sons, 1965
Survey sampling, mathematical
Cochran, William G., Sampling Techniques, 3rd edition, John Wiley & Sons, Inc., 1977
Des Raj, Sampling Theory, McGraw-Hill, Inc., 1968
Hansen, Morris H., William N. Hurwitz and William G. Madow, Sample Survey Methods and Theory, volumes 1 and 2, John Wiley & Sons, Inc., 1953
Survey sampling, additional references (mix of mathematical and less mathematical)
Deming, William Edwards, Some Theory of Sampling, Dover Publications, 1950
Deming, W. Edwards, Sample Design in Business Research, John Wiley & Sons, 1960
Sukhatme, P.V., and Sukhatme, B.V., Sampling Theory of Surveys with Applications, P.V. Sukhatme and B.V. Sukhatme, 1970
Williams, Bill, A Sampler on Sampling, John Wiley & Sons, 1978
Rubin, Donald B., Multiple Imputation for Nonresponse in Surveys, John Wiley & Sons, 1987
Little, Roderick J. A. and Donald B. Rubin, Statistical Analysis with Missing Data, 2nd ed., John Wiley & Sons, 2002
Groves, Robert M., Paul P. Biemer, Lars E. Lyberg, James T. Massey, William L. Nicholls II, Joseph Waksberg (editiors), Telephone Survey Methodology, John Wiley & Sons, 1988
Ghosh, M. and G. Meeden, Bayesian Methods for Finite Population Sampling, Chapman & Hall, 1997
References that discuss techniques for analytical surveys (model-based approach) and resampling
Lohr, Sharon, Sampling: Design and Analysis, 2nd ed., Cengage Learning, 2009
Kott, Phillip S., Sample Survey Theory and Methods: A Correspondence Course, Sept. 12, 2006. May be downloaded free from http://www.nass.usda.gov/research/reports/course%20notes%200906.pdf This course has the prerequisite of one preious college-level course in statistics. It uses Sharon Lohr’s Sampling: Design and Analysis as a required text.
Rao, J. N. K. and D. R. Bellhouse, “History and Development of the Theoretical Foundations of Survey Based Estimation and Analysis,” Survey Methodology, June 1990, Statistics Canada
Risto Lehtonen and Erikki Pahkinen, Practical Methods for Design and Analysis of Complex Surveys, 2nd edition, Wiley, 2004
Thompson, Steven K., Sampling, 3nd edition, Wiley, 2012
Valliant, Richard, Alan H. Dorfman and Richard M. Royall, Finite Population Sampling and Inference: A Prediction Approach, Wiley, 2000
Valliant, Richard, Jill A. Dever and Frauke Kreuter, Practical Tools for Designing and Weighting Survey Samples, Springer, 2013
Särndal, Carl-Erik, Bengt Swensson and Jan Wretman, Model Assisted Survey Sampling, Springer, 1992
Shao, Jun and Dongsheng Tu, The Jackknife and Bootstrap, Springer, 1995
Efron, B. and R. J. Tibshirani, An Introduction to the Bootstrap, Chapman and Hall, 1993
Wolter, Kirk M., Introduction to Variance Estimation, 2nd ed., Springer, 2007
Cohen, Jacob, Statistical Power Analysis for the Behavioral Sciences, 2nd ed., Lawrence Erlbaum, 1988, also Academic Press, 2011. (Discusses the determination of sample size by specification of the power of tests of hypothesis, rather than the precision of estimates.)
References on Experimental Design and Quasi-experimental Design
Kuehl, Robert O., Design of Experiments: Statistical Principles of Research Design and Analysis, Duxbury, Brooks/Cole, Cengage Learning, 2000
Cochran, William G. and Gertrude M. Cox, Experimental Designs, 2nd edition, Wiley, 1950, 1957
Campbell, Donald T. and Julian C. Stanley, Experimental and Quasi-Experimental Designs for Research, Rand McNally, 1966. Reprinted from Handbook of Research on Teaching, N. L. Gage (editor), Rand Mcnally, 1963.
Cook, Thomas D. and Donald T. Campbell, Quasi-Experimentation: Design and Analysis Issues for Field Settings Houghton Mifflin, 1979
Shadish, William R., Thomas D. Cook and Donald T. Campbell, Experimental and Quasi-Experimental Designs for Generalized Causal Inference, Wasworth Cengage Learning, 2002
Rosenbaum, Paul R., Observational Studies, 2nd ed., Springer, 2002
Murray, David M., Design and Analysis of Group-Randomized Trials, Oxford University Press, 1998
Additional Material on Sample Survey Design for Evaluation
Caldwell, Joseph George, “Sample Survey Design for Evaluation,” posted at http://www.foundationwebsite.org/SampleSureyDesignForEvaluation.pdf .
6. Resume of Course Developer
Résumé of Course Developer: Joseph George Caldwell, Ph.D.
Consultant in Statistics, Economics, Operations Research and Computer Science
Education...
Ph.D., Statistics, University of North Carolina at Chapel Hill, 1966
B.S., Mathematics, Carnegie Mellon University, 1962
Consultant...
to US government agencies, state governments, corporations, and foreign governments
Director/Supervisor of projects in the areas of...
o sample survey design of major national surveys and statistical reporting systems
o statistical experimental design and data analysis (SPSS, SAS, Stata)
o computer models and information systems design (C, Xbase, Oracle SQL, MS Access)
o expert systems / geographic information systems (ArcView)
o systems and software engineering (C, Visual Basic, FORTRAN, DOD-STD-2167A, ISO12207, Carnegie Mellon University Software Engineering Institute Capability Maturity Model (CMM))
o operations research / management science and statistics in industrial and defense applications
o monitoring and evaluation, planning and policy analysis of government programs in health, education, human services, urban problems, rural development, agriculture, tax policy analysis, and public finance
o game theory (zero-sum and non-zero-sum, constrained games, ill-conditioned problems; computer solutions of complex games)
o international development in the Philippines, Haiti, Egypt, Bangladesh, Ghana, Malawi, Botswana, Zambia, Timor-Leste, Honduras, Guinea, and Liberia.
Manager of contract research firm (seven years); successful bidder on numerous technical contracts, including four Small Business Innovation Research (SBIR) contracts. Director of more than twenty projects for US government and other clients.
Adjunct Professor of Statistics at the University of Arizona, Tucson, Arizona
Developer of technical seminars and computer program packages in sample survey design, forecasting, demographic projection, and geographic information systems
Languages: Native in English; working knowledge of Spanish, French; limited Portuguese, German, Arabic
Summary of Experience. Dr. Caldwell's professional career in research and research management has centered on the use of modern analysis techniques to solve practical problems in government, commercial, industrial, and military applications. He has directed major technical projects; developed technical training seminars; accomplished significant research results in statistics; developed statistical, demographic, and geographic-information-system computer program packages; designed statistical reporting and management information systems; and served as professor of statistics, consultant, and manager of a contract research firm.
Contact information:
Permanent address: 1432 N Camino Mateo, Tucson, AZ 85745-3311 USA. Tel. 1-(520)222-3446, e-mail jcaldwell9@yahoo.com
CAPABILITIES AND EXPERIENCE IN STATISTICS
Education. Dr. Caldwell holds a PhD degree in mathematical statistics from the University of North Carolina at Chapel Hill. In his graduate studies, he specialized in the theory of experimental design and algebraic coding theory. His doctoral dissertation advisor was Prof. R. C. Bose, regarded as the "father" of the mathematical theory of experimental design, and developer of the Bose-Chaudhuri-Hocquenghem (BCH) codes, the best known class of codes for correcting random errors in noisy communication channels. In his doctoral dissertation, Dr. Caldwell developed the best-known class of codes for correcting additive and synchronization errors in noisy communication channels.
Experience. Dr. Caldwell has over thirty years' experience as a consultant and teacher of statistics. He has provided statistical consultation in a wide variety of fields, including sample survey design and analysis; statistical analysis of data; time series analysis and forecasting; simulation and modeling of industrial and military systems; test and evaluation of communications systems; industrial quality control; process control and product improvement; and planning, policy analysis, and program evaluation in health, education, social services, and economic development.
Experience in Monitoring and Evaluation. An area of specialization in which he has applied statistical methodology is monitoring and evaluation. He developed survey designs for a number of monitoring systems and program evaluation studies in the US and foreign countries. In the US, he directed a number of national projects in program monitoring and evaluation, including the Vocational Rehabilitation Evaluation Standards Study for the US Rehabilitation Services Administration; Social Services Effectiveness Evaluation for West Virginia; the Day Care Cost Benefit Study for the US Department of Health and Human Services; Cost-Benefit Analysis of National Institute for Alcohol Abuse and AlcoholismTreatment Centers; Medicaid Standards Impact Assessment. He developed the sampling plans for several national state/federal social and economic programs, including the Sampling Manual for Utilization Review of Medicaid; the Sampling Manual for Social Services (Title XX) Reporting Requirements; and the Sampling Manual for Office of Child Support Enforcement Reporting Requirements. He developed the survey design for the Department of Housing and Urban Development Housing Market Practices Survey; the Research Design for the Urban Arterials Section of the Highway Capacity Manual; and the survey design for the Elementary and Secondary School Civil Rights Survey.
Overseas, he served as Project Director and Chief of Party for the Economic and Social Impact Analysis / Women in Development Project in the Philippines. This project provided consulting in research design (experimental design, quasi-experimental design, survey design, survey instrument design) for a broad range of development projects (health, nutrition, and family planning; education; integrated agricultural production and marketing, aquaculture production, and agro-reforestation; integrated area development; feeder roads; ports; local water systems; electrification; small-scale industries, and tourism). He served as Manager of Monitoring and Evaluation for the Local Development II – Provincial Project in Egypt. This project was the largest USAID-funded local-level rural development project in the world. On this project, which involved the funding of 16,000 local-level projects, a sample survey design was constructed to enable assessment of program impact based on a sample of about 800 projects. The projects included potable water, waste water, roads, buildings, rolling stock, environment, and information systems.
Teaching. Dr. Caldwell served as an adjunct professor of statistics at the University of Arizona. He taught the graduate course, Sampling Theory and Methods, and the undergraduate course, Statistical Methods in Management (for all students of business, public administration, and management information systems).
Technical Training. Dr. Caldwell developed and marketed the technical seminar, Sample Survey Design and Analysis. This popular three-day course has been given on an advertised basis, and also on an in-house basis at the US Bureau of Labor Statistics. More recently (2014), he presented the course Small Area Statistics to the Bahamas Department of Statistics (sponsored by Inter-American Development Bank).
Research in Statistical Methodology. Dr. Caldwell served as a consultant to the US Department of Education's National Center for Education Statistics, on the Statistical Analysis Group in Education (SAGE) program. In this work, he developed a new approach to the treatment of nonresponse in longitudinal surveys. For the US Office of Naval Research, he directed the project, "Fast Algorithms for Estimation, Prediction and Control." This project was concerned with the development of an estimation methodology that could be used as an alternative to the conventional least-squares procedure, in ill-conditioned estimation problems (singularity, missing values).
Statistical Software Development / Time Series Analysis. Dr. Caldwell developed the first commercially available computer program package for implementation of the Box-Jenkins time series methodology. The Box-Jenkins (autoregressive integrated moving average) models are useful in system identification problems, such as forecasting, control, and linear predictive coding of speech.
Sample Survey Design. Dr. Caldwell developed the design for many important national sample surveys and statistical reporting systems. He specializes in the development of analytical survey designs to collect data for model development, and has developed new techniques for handling nonresponse in longitudinal surveys. Surveys he designed include the following (sponsor and dates listed for more recent projects):
o Jamaica Impact Evaluation of the Programme of Advancement through Health and Education (PATH) (Government of Jamaica, 2012)
o Agriculture Data Collection in the Sourou Valley and Comoé Valley, Burkina Faso (Millennium Challenge Account, 2012)
o Community-Based Rangeland and Livestock Management Household Income and Expenditure Survey, Namibia (Millennium Challenge Account, 2010-2011)
o Conservancy Support and Indigenous Natural Products Household and Organisational Survey, Namibia (Millennium Challenge Account, 2010-2012)
o Impact Evaluation of Water Supply Activity, Ghana (Millennium Development Authority, 2010)
o Monitoring and Evaluation of the Competitive African Cashew Value Chains for Pro-Poor Growth Program, various African countries (GTZ, 2009-2010)
o Impact Evaluation of Feeder Roads Activity, Ghana
o Impact Evaluation of Transportation Project and Farmer Training and Development Activity, Honduras (Millennium Development Authority, 2007-2013)
o Monitoring and Evaluation of the Competitive African Cotton for Pro-Poor Growth Program (COMPACI), various African countries (DEG, 2009-2013)
o Ghana Trade and Investment Program Survey (Millennium Development Authority, 2009-2011)
o Malawi Annual Primary School Enrollment Survey
o National survey of local development projects in Egypt
o National Center for Health Services Research (NCHSR) Hospital Cost Data Study
o Professional Standards Review Organization (PSRO) Data Base Development Study
o Study of the Impact of National Health Insurance on Bureau of Community Health Service Users
o 1976 Survey of Institutionalized Persons
o Housing and Urban Development (HUD) Housing Market Practices Survey
o Research Design for the Urban Arterials Section of the Highway Capacity Manual
o Elementary and Secondary School Civil Rights Survey
Statistical Program Monitoring Systems. He developed the sampling manuals for the following state-federal reporting systems:
o Sampling Manual for Utilization Review of Medicaid
o Sampling Manual for Social Services Reporting Requirements (Title XX)
o Sampling Manual for Office of Child Support Enforcement Reporting Requirements
Management Information Systems. He developed the Personnel Management Information System (PMIS) for the civil service of the Government of Malawi and the Education Management Information System (EMIS) for the Government of Zambia.
Experimental Design and Quality Control. He developed statistical experimental designs for test and evaluation, simulation model run‑sets, chemical and physical experimentation, and industrial quality control applications.
Data Analysis. He has applied statistical software to analyze sample survey data, including the Urban Institute's Study of Salaries in Academia, surveys to collect price data for commodities in Haiti, and surveys of the implementation, operational, and service-delivery status of local development projects in Egypt. He is an expert in the analysis of time series data, and has analyzed data collected in accordance with statistical experimental designs. He has applied the full range of statistical analysis procedures, including time series analysis, multiple regression analysis, multivariate analysis of variance, components-of-variance analysis, factor analysis, and nonparametric analysis.
He is expert in the use of modern commercial statistical analysis software (e.g., SPSS, SAS) and the use of related microcomputer software (e.g., Microsoft Access database management system).
Positions.
Consultant, 1974-present (various organizations, including the National Opinion Research Center of the University of Chicago (NORC), Inter-American Development Bank, United Nations Development Program, Academy for Educational Development, Canada Trust Bank, First Union National Bank, Chemonics International, Bank of Botswana)
President and Manager, Vista Research Corporation, Tucson and Sierra Vista, AZ, 1988-91
Professor of Statistics, University of Arizona, Tucson, AZ, 1982-86
Director of Research and Development and Principal Scientist of US Army Electronic Proving Ground's Electromagnetic Environmental Test Facility, Bell Technical Operations, Tucson and Sierra Vista, AZ, 1982-86, 1986-88
Principal Engineer, SINGER Systems and Software Engineering, Tucson, AZ, 1986
President and Manager, Vista Research Corporation, Alexandria, VA, and Tucson, AZ, 1977-81
Vice President, JWK International Corporation, Annandale, VA, 1974-76
Principal, Planning Research Corporation, McLean, VA, 1972-74
Member of the Technical Staff, Lambda Corporation / General Research Corporation, McLean, VA, 1967-72
Senior Operations Research Analyst, Deering Milliken Research Corporation, Spartanburg, SC, 1966-67
Operations Research Analyst, Research Triangle Institute, Research Triangle Park, NC, 1964-66
jgcsamp20161105.doc
7. Day 1: Basic Concepts in Sample Survey
SAMPLE SURVEY DESIGN AND ANALYSIS:
A COMPREHENSIVE THREE-DAY COURSE
LECTURE NOTES
DAY ONE: BASIC CONCEPTS OF SAMPLE SURVEY
Joseph George Caldwell, PhD (Statistics)
1432 N Camino Mateo, Tucson, AZ 85745-3311 USA
Tel. (001)(520)222-3446, E-mail jcaldwell9@yahoo.com
Updated November 9, 2016
Copyright © 1980 - 2016 Joseph George Caldwell. All rights reserved.
DAY 1: BASIC CONCEPTS IN SAMPLE SURVEY
INTRODUCTION; COURSE OBJECTIVES AND OUTLINE; OVERVIEW OF FIRST DAY’S COURSE CONTENT
- BASIC STATISTICAL CONCEPTS
- SIMPLE RANDOM SAMPLING
- CONCEPT OF SAMPLE DESIGN
- STRATIFIED SAMPLING
- CLUSTER SAMPLING
- SYSTEMATIC SAMPLING
- MULTISTAGE SAMPLING
- DOUBLE SAMPLING
- SURVEY OF REFERENCES; OUTLINE OF TOPICS FOR SECOND AND THIRD DAYS; QUESTIONS AND ANSWERS
7.1 Basic Concepts in Sample Survey
BASIC CONCEPTS IN SAMPLE SURVEY
POPULATION: THE POPULATION IS A WELL-DEFINED COLLECTION OF ELEMENTS (MEMBERS, ITEMS, OBJECTS), a1, a2, …,aN (POPULATION SIZE = N).
IN MOST OF THIS COURSE, THE POPULATIONS WILL BE FINITE. AT ONE POINT (DEALING WITH EVALUATION RESEARCH) WE WILL CONSIDER CONCEPTUALLY INFINITE POPULATIONS.
EXAMPLES:
- ALL RESIDENTS OF A SPECIFIED COUNTRY (THE USUAL “POPULATION”)
- ALL SCHOOLS IN THE COUNTRY
- ALL TEACHERS IN THE COUNTRY
- ALL PUPILS IN THE COUNTRY
- ALL HOSPITALS IN A REGION OF THE COUNTRY
- ALL PERSONS INFECTED WITH HIV IN THE COUNTRY
- ALL EXPORTERS OF NONTRADITIONAL COMMODITIES
- ALL ELEPHANTS
THE POPULATION IS DEFINED BY FOUR QUANTITIES: CONTENT, UNITS, EXTENT AND TIME (E.G., THE INCOME, OF US CITIZENS, RESIDING OVERSEAS, IN THE PAST YEAR).
WE ARE INTERESTED IN DESCRIBING CERTAIN CHARACTERISTICS (ATTRIBUTES, FEATURES, PROPERTIES) OF THE POPULATION. LET Xi DENOTE AN ARBITRARY NUMERICAL ATTRIBUTE THAT CAN BE DETERMINED FOR A POPULATION ELEMENT (SUCH AS GENDER, AGE, INCOME, HIV STATUS, SCHOOL SIZE, HOSPITAL OWNERSHIP).
FOR EXAMPLE, IN EXAMPLE (1), WE MAY WISH TO DESCRIBE THE PREVIOUS YEAR’S EARNINGS AND CURRENT EMPLOYMENT STATUS OF ALL RESIDENTS (ON JULY 1), BY AGE CATEGORY, GENDER, AND MARITAL STATUS.
THE PROBLEM OF SAMPLE SURVEY (“SAMPLING”) IS TO ESTIMATE THE VALUE OF POPULATION CHARACTERISTICS (E.G., A MEAN, PROPORTION OR TOTAL) FROM A SUBSET (PART, PORTION, “SAMPLE”) OF THE POPULATION.
WHY A SUBSET?
- PRACTICAL ADVANTAGES
- IMPOSSIBILITY OF A CENSUS IN SOME CASES
- THE EXACT VALUE IS SELDOM NECESSARY
- CERTAIN AMOUNT OF ERROR IS TOLERATED
- EVEN A COMPLETE ENUMERATION (CENSUS) WILL NOT PRODUCE THE EXACT VALUE
- CAN EXAMINE A SUBSET MORE CAREFULLY THAN THE ENTIRE POPULATION
THE POPULATION TO BE SAMPLED (THE SAMPLED POPULATION) MAY DIFFER FROM THE POPULATION OF INTEREST (THE TARGET POPULATION), FOR PRACTICAL REASONS.
BEFORE SELECTING A SUBSET, THE SAMPLED POPULATION IS DIVIDED INTO SAMPLING UNITS (NONOVERLAPPING, EXHAUSTIVE). A LIST OF ALL OF THE SAMPLING UNITS IS CALLED A FRAME (OR SAMPLE FRAME OR SAMPLING FRAME). A SAMPLE (TECHNICAL DEFINITION) IS A COLLECTION OF SAMPLING UNITS DRAWN FROM A FRAME.
EXAMPLE: WANT A SAMPLE OF PUBLIC-SCHOOL STUDENTS. ALL STUDENTS ARE IN SCHOOLS, SO WE MAY DEFINE THE SAMPLING UNIT AS A SCHOOL, AND SELECT A SAMPLE OF SCHOOLS TO OBTAIN A SAMPLE OF STUDENTS. WE ARE MUCH MORE LIKELY TO BE ABLE TO OBTAIN A LIST OF SCHOOLS (SCHOOL FRAME) THAN A LIST OF STUDENTS (STUDENT FRAME).
AFTER SELECTION OF THE SAMPLE, MEASUREMENTS ARE MADE ON THE SAMPLE ELEMENTS (AND ALSO PERHAPS ON THE SAMPLING UNITS) (E.G., A STUDENT’S AGE; A TEACHER’S LEVEL OF EDUCATION; A SCHOOL’S TYPE OF OWNERSHIP; A HOSPITAL’S ANNUAL INCOME).
TWO MAJOR TYPES OF MEASUREMENT SCALES (“VARIABLES”): DISCRETE AND CONTINUOUS.
DISCRETE (NOMINAL/CATEGORICAL, ORDINAL/RANKING): CAN BE COUNTED (E.G., INTEGERS). EXAMPLES: GENDER (M OR F); EMPLOYMENT STATUS (EMPLOYED OR UNEMPLOYED); FAMILY SIZE; EDUCATIONAL LEVEL.
SPECIAL CASE: FOR A BINARY VARIABLE THE Xi’s ARE 0 OR 1 (E.G., MALE=0, FEMALE=1; ABSENCE OF SOME CONDITION = 0, PRESENCE OF THE CONDITION = 1).
CONTINUOUS (INTERVAL, RATIO): DISTANCES / DIFFERENCES CAN BE MEASURED ON AN INTERVAL SCALE (REAL NUMBERS); EXAMPLES: AGE, HEIGHT, TEMPERATURE, BLOOD COUNT, INCOME
STATISTICAL THEORY GUIDES US IN SUMMARIZING AND ANALYING THE SAMPLE, TO MAKE INFERENCES ABOUT THE POPULATION. IT ALSO GUIDES US IN THE DESIGN OF THE SURVEY, THE SAMPLE SELECTION PROCEDURES, AND THE SURVEY INSTRUMENTS (QUESTIONNAIRES, DATA COLLECTION FORMS).
THE ELEMENTS OF SURVEY DESIGN
1. SPECIFY POPULATION OF INTEREST
2. SPECIFY UNITS OF ANALYSIS AND ESTIMATES OF INTEREST
3. SPECIFY PRECISION OBJECTIVES OF THE SURVEY; RESOURCE CONSTRAINTS; POLITICAL CONSTRAINTS
4. SPECIFY OTHER VARIABLES OF INTEREST (EXPLANATORY VARIABLES, STRATIFICATION VARIABLES)
5. REVIEW POPULATION CHARACTERISTICS (DISTRIBUTIONAL, COST)
6. DEVELOP INSTRUMENTATION (DEVELOPMENT, PRETEST, PILOT TEST, RELIABILITY AND VALIDITY ANALYSIS)
7. DEVELOP SAMPLE DESIGN
8. DETERMINE SAMPLE SIZE AND ALLOCATION
9. SPECIFY SAMPLE SELECTION PROCEDURE
10. SPECIFY FIELD PROCEDURES
11. DETERMINE DATA PROCESSING PROCEDURES
12. DEVELOP DATA ANALYSIS PLAN
13. OUTLINE FINAL REPORT
(FROM “VISTA’S APPROACH TO SAMPLE SURVEY DESIGN,” AT http://www.foundationwebiste.org/ApproachToSampleSurveyDesign.htm .)
DESCRIPTION (CHARACTERISTICS) OF A FINITE POPULATION OF SIZE N
LET X DENOTE A (NUMERICAL-VALUED) CHARACTERISTIC, SUCH AS AGE OR INCOME (X IS A “CONCEPT”). LET x DENOTE A PARTICULAR VALUE OF X (SUCH AS AN AGE OF 43).
- MEAN (ARITHMETIC AVERAGE) =
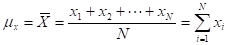
(FOR BINARY DATA,![]() , WHERE
, WHERE ![]() DENOTES
THE PROPORTION OF 1’s)
DENOTES
THE PROPORTION OF 1’s)
- MEDIAN: THE MIDDLE VALUE WHEN THE xi’s ARE ARRANGED IN ORDER.
- PERCENTILES, E.G., THE 95-TH PERCENTILE, p95 FOR INCOME IS THE INCOME SUCH THAT 95 PERCENT OF THE POPULATION HAS INCOME LESS THAN OR EQUAL TO p95
- VARIANCE =
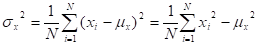 (THE
“COMPUTATIONAL” FORM)
(THE
“COMPUTATIONAL” FORM)
ALSO ![]()
- STANDARD DEVIATION: SQUARE ROOT OF VARIANCE = σx
- COEFFICIENT OF VARIATION: σx/μx
- TOTAL =
 = X
= N μx
= X
= N μx
THE MEAN AND MEDIAN ARE MEASURES OF LOCATION, OR CENTRAL TENDENCY; THE VARIANCE AND STANDARD DEVIATION ARE MEASURES OF SPREAD, VARIATION, OR DISPERSION.
THE PRECEDING QUANTITIES ARE SINGLE-VALUED ATTRIBUTES (CHARACTERISTICS, “PARAMETERS”) THAT SUMMARIZE THE LOCATION AND SPREAD OF THE ATTRIBUTE. IN ADDITION, WE CAN SUMMARIZE THE POPULATION USING MORE COMPLEX REPRESENTATIONS, SUCH AS FREQUENCY DISTRIBUTIONS, CROSSTABULATIONS, AND TABLES OF MEANS.
POPULATION PARAMETERS ARE USUALLY DENOTED BY LOWER-CASE
GREEK LETTERS (E.G., ![]() ) OR BY
UPPER-CASE LATIN LETTERS (E.G.,
) OR BY
UPPER-CASE LATIN LETTERS (E.G., ![]() ). USE
OF AN UPPER-CASE LATIN LETTER FOR THE POPULATION TOTAL (X) MAY BE
CONFUSING, HOWEVER, SINCE THAT IS THE SAME SYMBOL USED TO DENOTE THE UNDERLYING
RANDOM VARIABLE (ALSO X). WE WILL USUALLY USE GREEK LETTERS TO DENOTE
PARAMETERS, BUT NOT ALWAYS, IN ORDER TO FAMILIARIZE THE STUDENT WITH
ALTERNATIVE NOTATION THAT IS IN COMMON USE.
). USE
OF AN UPPER-CASE LATIN LETTER FOR THE POPULATION TOTAL (X) MAY BE
CONFUSING, HOWEVER, SINCE THAT IS THE SAME SYMBOL USED TO DENOTE THE UNDERLYING
RANDOM VARIABLE (ALSO X). WE WILL USUALLY USE GREEK LETTERS TO DENOTE
PARAMETERS, BUT NOT ALWAYS, IN ORDER TO FAMILIARIZE THE STUDENT WITH
ALTERNATIVE NOTATION THAT IS IN COMMON USE.
NOTE ON FONTS
NOTE ON FONTS: TO ENHANCE READABILITY (ON THE COMPUTER SCREEN AND ON WALL PROJECTIONS), THESE NOTES ARE PRESENTED IN BLOCK LETTERS, USING THE MICROSOFT ARIEL FONT. MATHEMATICAL SYMBOLS ARE ITALICIZED, TO MAKE THEM EASIER TO DISTINGUISH FROM NORMAL TEXT.
MATHEMATICAL EXPRESSIONS ARE CONSTRUCTED USING MICROSOFT
EQUATION EDITOR 3.0, WHICH USES THE MICROSOFT TIMES
NEW ROMAN FONT, ITALICIZED. THERE ARE HENCE SOME SLIGHT DIFFERENCES
BETWEEN SYMBOL FONTS IN THE TEXT AND IN THE FORMULAS (E.G., E(X) IN THE
TEXT VS. ![]() IN
A FORMULA; f(x) AND g(x) IN TEXT VS.
IN
A FORMULA; f(x) AND g(x) IN TEXT VS. ![]() AND
AND ![]() IN A
FORMULA).
IN A
FORMULA).
(THE USE OF TIMES FONT FOR THE TEXT WOULD DECREASE READABILITY, AND THE USE OF THE EQUATION EDITOR TO REPRESENT ALL SYMBOLS IN THE TEXT WOULD INTRODUCE VARIATIONS IN LINE SPACING, GREATLY EXPAND THE COMPUTER FILE SIZE OF THIS DOCUMENT, SIGNIFICANTLY INCREASE THE TIME REQUIRED TO TYPE THESE NOTES, AND SIGNIFICANTLY INCREASE THE FILE SIZE AND INTERNET DOWNLOAD TIME (SINCE FORMULAS ARE STORED AS SEPARATE FILES IN .htm DOCUMENTS).)
DESCRIPTION OF A FINITE POPULATION (CONT.)
FREQUENCY DISTRIBUTION, TABULAR FORM:
INTERVAL FREQUENCY RELATIVE FREQUENCY
a0 - a1 f1 f1/N
a1 - a2 f2 f2/N
a2 – a3 f3 f3/N
…
ak-1 – ak fk f4/N
N (POPULATION SIZE) = f1 + f2 + … + fk
VALUES FALLING ON AN INTERVAL BOUNDARY ARE ASSIGNED TO THE LOWER INTERVAL (I.E., THE VALUE a1 IS ASSIGNED TO THE CATEGORY a0 - a1, NOT TO a1 - a2).
EXAMPLE: AGE DISTRIBUTION OF THE POPULATION
INTERVAL FREQUENCY RELATIVE FREQUENCY (PROPORTION)
0-18 247 .27
19-64 549 .61
65+ 113 .12
TOTAL 909 1.00
SPECIAL CASE: DISCRETE VARIABLE HAVING A SMALL NUMBER OF CATEGORIES (SUCH AS GENDER, EMPLOYMENT STATUS, OR HOUSEHOLD SIZE). IN THIS CASE THE INTERVALS MAY INCLUDE A SINGLE NUMBER:
EXAMPLE: GENDER DISTRIBUTION OF THE POPULATION
GENDER FREQUENCY RELATIVE FREQUENCY
MALE 110 .48
FEMALE 117 .52
TOTAL 227 1.00
EXAMPLE: DISTRIBUTION OF HOUSEHOLD SIZE
HOUSEHOLD SIZE FREQUENCY
1 f1
2 f2
3 f3
4 f4
5 f5
6 f6
7 f7
8 f8
9 f9
10 f10
11, 12, 13,…. f11, f12, f13,….
DESCRIPTION OF A FINITE POPULATION (CONT.)
FREQUENCY DISTRIBUTIONS, GRAPHICAL FORM:
DISCRETE VARIABLES
FREQUENCY DISTRIBUTION OF GENDER (THE SUM OF THE FREQUENCIES IS N)
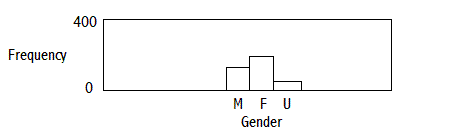
PROBABILITY DENSITY FUNCTION OF GENDER (THE SUM OF THE PROBABILITIES IS 1)
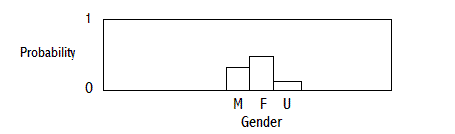
CONTINUOUS VARIABLES (OR ORDERED DISCRETE VARIABLES HAVING MANY VALUES)
FREQUENCY DISTRIBUTION OF AGE (HISTOGRAM)
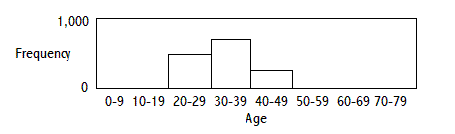
PROBABILITY DENSITY FUNCTION OF AGE
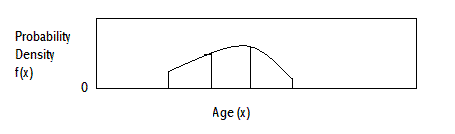
DESCRIPTION OF A FINITE POPULATION (CONT.)
CROSSTABULATIONS (TABLES OF COUNTS AND MEANS)
(JOINT) FREQUENCY DISTRIBUTION OF POPULATION BY GENDER AND AGE
AGE MALE FEMALE BOTH SEXES
0-18 20 150 170
19-64 150 550 700
65+ 30 100 130
ALL AGES 200 800 1,000
TABLE OF MEAN ANNUAL INCOME BY GENDER AND AGE
GENDER
MALE FEMALE TOTAL
0-18 1,000 800 900
AGE 19-64 30,000 35,000 34,000
65+ 10,000 10,000 10,000
TOTAL 20,000 22,000 30,000
STATISTICAL MODELS: REGRESSION EQUATIONS:
INCOME AS A FUNCTION OF EDUCATION: FORMULA OR TABLE
![]()
WHERE
y = AGE
x1 = HAS HIGH SCHOOL DIPLOMA (0 OR 1)
x2 = HAS COLLEGE DEGREE (0 OR 1)
x7 = PARENTS HAVE COLLEGE DEGREE (0 OR 1)
x11 = NUMBER OF YEARS OF WORK EXPERIENCE
e = ERROR TERM
|
Education |
||||||||||
|
<12 years |
HSD |
BA/BS |
MS |
PhD |
MD |
Other Prof Degree |
Other Degree |
Other |
||
|
Income |
<50K |
|||||||||
|
50K-100K |
||||||||||
|
100K-200K |
||||||||||
|
>200K |
||||||||||
SOCIAL AND ECONOMIC IMPACT OF AN ECONOMIC DEVELOPMENT PROGRAM: FORMULA OR TABLE
|
Program Participation |
|||
|
Non-Participant |
Participant |
||
|
Gender |
Female |
||
|
Male |
|||
FACTORS AFFECTING SAMPLE SURVEY DESIGN
THE DESIGN OF THE SAMPLE SURVEY (E.G., CHOICE OF SAMPLING UNITS, SAMPLE SIZES) WILL DEPEND ON WHAT THE ESTIMATION OBJECTIVES ARE, AND THE COSTS INVOVLED (E.G., INSTRUMENT PREPARATION, PRETESTING, SAMPLE DESIGN COSTS, SAMPLING COSTS, ANALYSIS COSTS).
THE OBJECTIVE OF SAMPLE SURVEY DESIGN IS TO ENABLE THE PRODUCTION OF ESTIMATES, OF DESIRED QUANTITIES, THAT ARE OF ADEQUATE ACCURACY (HIGH PRECISION, LOW BIAS) AND ACCEPTABLE COST, TO SUPPORT DECISIONS / ACTIONS.
TWO MAIN CLASSES OF SAMPLE SURVEYS: DESCRIPTIVE SURVEYS (ENUMERATIVE SURVEYS) AND ANALYTICAL SURVEYS (TO SUPPORT MODEL DEVELOPMENT – SIMILAR TO DESIGN OF EXPERIMENTS). THIS COURSE WILL ADDRESS BOTH TYPES OF SURVEYS.
DESCRIPTIVE SURVEYS FOCUS ON ESTIMATION OF OVERALL POPULATION (OR SUBPOPULATION) CHARACTERISTICS (SUCH AS MEANS OR TOTALS). ANALYTICAL SURVEYS FOCUS ON ESTIMATION OF RELATIONSHIPS AMONG VARIABLES AND ON TESTS OF HYPOTHESIS (E.G., IS IT REASONABLE TO CONCLUDE THAT TWO POPULATIONS COULD HAVE BEEN GENERATED BY THE SAME PROBABILITY DISTRIBUTION; OR, DOES AN ECONOMIC DEVELOPMENT PROGRAM HAVE A POSITIVE ECONOMIC IMPACT).
TYPES OF SAMPLING
- HAPHAZARD: WITHOUT ANY SCHEME
- PURPOSIVE, OR JUDGMENT: REPRESENTATIVE
- RANDOM SAMPLING, OR PROBABILITY SAMPLING: STATISTICAL THEORY CAN BE USED TO MAKE USEFUL STATEMENTS (INFERENCES). STATISTICAL THEORY IS APPLICABLE ONLY IN THIS CASE.
SIMPLEST FORM OF RANDOM SAMPLING: SIMPLE RANDOM SAMPLING WITHOUT REPLACEMENT
SOME BASIC CONCEPTS OF PROBABILITY AND STATISTICS
PROBABILITY THEORY
CONSIDER AN EXPERIMENT, WHICH, WHEN PERFORMED, HAS AN OUTCOME (THE RESULT OF THE EXPERIMENT)
SAMPLE SPACE: THE SET OF ALL POSSIBLE OUTCOMES OF AN EXPERIMENT
EXAMPLES:
COIN-TOSSING EXPERIMENT: HEAD, TAIL
A PERSON SELECTED IN A SURVEY: JOHN SMITH, MARY JONES,…
THE GENDER OF A PERSON SELECTED IN A SURVEY: M, F
A HOUSEHOLD SELECTED IN A SURVEY: THE SMITH FAMILY, THE JONES FAMILY
THE SIZE OF A HOUSEHOLD SELECTED IN A SURVEY: 0, 1, 2 ,3, 4,…
AN OPINION: DISAGREE STRONGLY, DISAGREE MILDLY, NEITHER AGREE NOR DISAGREE, AGREE MILDLY, AGREE STRONGLY
IN SAMPLE SURVEY, THE EXPERIMENT IS THE SELECTION (“DRAWING”) OF A SAMPLE UNIT. THE SAMPLE SPACE IS THE SET (COLLECTION) OF ALL SAMPLING UNITS.
THE PROBABILITY ASSOCIATED WITH A SAMPLE UNIT IS THE RELATIVE FREQUENCY WITH WHICH THAT UNIT WOULD BE SELECTED, IN REPEATED DRAWINGS.
IN THE SIMPLEST CASE, THE PROBABILITY OF SELECTION OF EACH SAMPLE UNIT IS THE SAME (I.E., 1/N IN THE CASE OF A SINGLE DRAW). THIS IS REFERRED TO AS SAMPLING WITH EQUAL PROBABILITIES.
IN SAMPLE SURVEY, IT IS FREQUENTLY THE CASE THAT THE SAMPLE UNITS ARE SELECTED WITH UNEQUAL PROBABILITIES. HOW TO SPECIFY THOSE PROBABILITIES, AND HOW TO SELECT THE SAMPLE ACCORDINGLY, IS THE CENTRAL PROBLEM OF SAMPLE SURVEY DESIGN.
OPTIONAL (SOME ADDITIONAL INFORMATION ABOUT PROBABILITES, INCLUDED FOR STUDENTS HAVING MATHEMATICAL BACKGROUND):
EVENT: A SUBSET (PART) OF THE SAMPLE SPACE (A COLLECTION OF OUTCOMES). EXAMPLES: HEAD (IN A COIN-TOSSING EXPERIMENT). AN INCOME OF $50,000 (OF A RESPONDENT TO A SURVEY). USUALLY DENOTED BY A, B, C,….
EVENT SPACE: THE COLLECTION OF ALL EVENTS.
AN OUTCOME IS REFERRED TO AS A “SIMPLE EVENT”
THE PROBABILITY OF AN EVENT: THE RELATIVE FREQUENCY WITH WHICH A PARTICULAR OUTCOME OCCURS IN REPETITIONS OF AN EXPERIMENT.
NOTATION:
OUTCOMES (“SIMPLE EVENTS”) a, b, c,… or A, B, C,…
PROBABILITY OF AN EVENT, A = Prob(A) = Pr(A) = P(A)
COMPOUND EVENTS: UNION OF A AND B (“A OCCURS OR B OCCURS”), INTERSECTION OF A AND B (“A OCCURS AND B OCCURS”) COMPLEMENT OF A (“A DOES NOT OCCUR”)
PROBABILITY OF A OR B = P(A UNION B) = P(A + B)
PROBABILITY OF A AND B = P(A INTERSECT B) = P(AB)
THE PROBABILITY FUNCTION, P(.), SPECIFIES THE PROBABILITY OF EACH EVENT. ITS VALUES RANGE FROM 0 TO 1, AND IF EVENTS A AND B ARE MUTUALLY EXCLUSIVE, THEN P(A OR B) = P(A) + P(B).
DEFINITION OF CONDITIONAL PROBABILITY:
PROBABILITY OF A GIVEN (CONDITIONAL ON) B = P(A|B) = P(AB)/P(B) IF P(B)>0
DEFINITION OF INDEPENDENT EVENTS:
EVENTS A AND B ARE INDEPENDENT IF ANY ONE OF THE FOLLOWING THREE CONDITIONS HOLDS:
P(AB) = P(A)P(B)
P(A|B) = P(A) IF P(B)>0
P(B|A) = P(B) IF P(A)>0
RULES FOR WORKING WITH PROBABILITIES:
P( A + B) = P(A) + P(B) – P(AB)
P(AB) = P(A|B)P(B) = P(A)P(B|A)
RANDOM VARIABLES AND DISTRIBUTION FUNCTIONS
RANDOM VARIABLE: A NUMERICAL-VALUED FUNCTION WHOSE VALUE DEPENDS ON THE OUTCOME OF AN EXPERIMENT. (IN MATHEMATICS: “A REAL-VALUED FUNCTION DEFINED ON A SAMPLE SPACE”; IT IS NOT A VARIABLE, BUT A FUNCTION.) DENOTED BY X(.) OR X.
A PARTICULAR VALUE OF THE RANDOM VARIABLE WILL BE DENOTED IN LOWER CASE (E.G., x IS A PARTICULAR VALUE (RESULT OF A PARTICULAR EXPERIMENT) OF THE RANDOM VARIABLE X.
EXAMPLES OF RANDOM VARIABLES:
DISCRETE RANDOM VARIABLES (NOMINAL, ORDINAL; SMALL INTEGERS):
HIV STATUS OF A PERSON IN A SURVEY: NOT INFECTED: 0; INFECTED: 1
GENDER OF INDIVIDUALS IN A SURVEY: FEMALE: 0; MALE: 1
SIZE OF A FAMILY IN A SURVEY: 0, 1, 2, 3, 4, 5, …
AGE CATEGORY: 0-17: 0; 18-64: 1; 65+: 2
INCOME CATEGORY: 0-$50,000 / YR: 1; 50,001 – 100,000 /YR: 2; 100,001 + /YR: 3
OPINION RESPONSE (“LIKERT SCALE”): DISAGREE STRONGLY: 1; DISAGREE MILDLY: 2; NEITHER AGREE NOR DISAGREE: 3; AGREE MILDLY: 4; AGREE STRONGLY: 5
CONTINUOUS RANDOM VARIABLES (INTERVAL OR RATIO SCALES OF MEASUREMENT):
THE AGE OF SOMEONE SELECTED IN A SURVEY (IN YEARS)
THE ANNUAL INCOME OF A FAMILY SELECTED IN A SURVEY (IN DOLLARS; NOT REALLY CONTINUOUS (DOLLARS OR THOUSANDS OF DOLLARS), BUT CLOSE ENOUGH – IT IS THE CONCEPTUAL MEASUREMENT SCALE THAT COUNTS)
A RANDOM VARIABLE IS A FUNCTION (OF THE OUTCOME) THAT HAS A NUMERICAL VALUE, WHEREAS THE OUTCOME OF AN EXPERIMENT MAY SIMPLY BE A NON-NUMERICAL ABSTRACT CONCEPT, SUCH AS A “HEAD” OR “TAIL” IN A COIN-TOSSING EXPERIMENT, A SAMPLE UNIT (SCHOOL, HOSPITAL, PERSON) SELECTED IN A SURVEY, OR GENDER (MALE, FEMALE) OF A PERSON IN A SURVEY.
RANDOM VARIABLES ARE USUALLY DENOTED BY UPPER-CASE LETTERS NEAR THE END OF THE ALPHABET, SUCH AS X, Y, Z,….
NEXT: PROPERTIES OF RANDOM VARIABLES:
EXPECTATION
VARIANCE
PROBABILITY DISTRIBUTION
OPTIONAL: CUMULATIVE DISTRIBUTION FUNCTION, FX(.), OF A RANDOM VARIABLE, X: FX(x) = P(X <= x) = Prob(the set of all outcomes, a, such that X(a )<= x) FOR EVERY REAL NUMBER x.
![]()
EXAMPLES OF CUMULATIVE DISTRIBUTION FUNCTIONS:
EXAMPLE 1, DISCRETE DISTRIBUTION: COIN TOSSING (TAIL=0, HEAD=1):
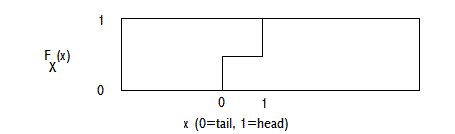
EXAMPLE 2, DISCRETE DISTRIBUTION: HOUSEHOLD INCOME IN A SURVEY OF HOUSEHOLDS
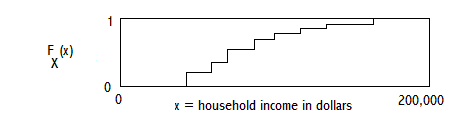
EXAMPLE 3, CONTINUOUS DISTRIBUTION: HOUSEHOLD INCOME IN A SURVEY OF HOUSEHOLDS
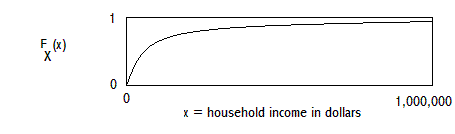
PROBABILITY DENSITY FUNCTIONS
DISCRETE RANDOM VARIABLES
THE PROBABILITY FUNCTION, OR DISCRETE DENSITY FUNCTION, OF A RANDOM VARIABLE, X, HAVING VALUES x1, x2, x3,…IS DEFINED AS:
![]()
EXAMPLE: PROBABILITY FUNCTION OF HOUSEHOLD SIZE IN SURVEY OF HOUSEHOLDS
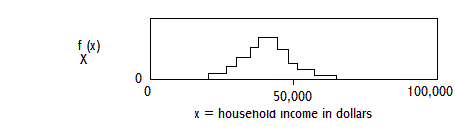
THE SUM OF THE PROBABILITIES IS EQUAL TO ONE.
OPTIONAL: CONTINUOUS RANDOM VARIABLES
LET FX(.) BE THE CUMULATIVE DISTRIBUTION FUNCTION OF THE RANDOM VARIABLE X. THE RANDOM VARIABLE X IS CONTINUOUS IF THERE EXISTS A FUNCTION fX(.) SUCH THAT
![]()
FOR EVERY REAL NUMBER x. THE FUNCTION fX(.) IS CALLED THE PROBABILITY DENSITY FUNCTION OF X.
EXAMPLE: PROBABILITY DENSITY FUNCTION OF HOUSEHOLD INCOME IN SURVEY OF HOUSEHOLDS
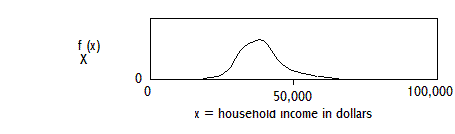
THE AREA UNDER THE CURVE IS EQUAL TO ONE.
EXPECTATION AND VARIANCE OF A RANDOM VARIABLE
EXPECTATION, OR MEAN, OR EXPECTED VALUE:
DISCRETE CASE: ![]()
OPTIONAL: CONTINUOUS CASE: ![]()
THE MEAN IS THE CENTER OF GRAVITY (CENTROID) OF THE UNIT MASS DETERMINED BY THE DENSITY FUNCTION.
VARIANCE: (EXPECTATION OF SQUARED DEVIATIONS FROM THE MEAN):
DISCRETE CASE: ![]()
OPTIONAL: CONTINUOUS CASE: ![]()
STANDARD DEVIATION = SQUARE ROOT OF VARIANCE: ![]()
NOTE: THE ABOVE FORMULAS FOR THE MEAN AND VARIANCE PRODUCE THE SAME RESULTS (IN THE DISCRETE CASE) AS THE FORMULAS GIVEN EARLIER FOR THE MEAN AND VARIANCE OF THE FINITE POPULATION (WHERE THE PROBABILITY ASSIGNED TO EACH MEMBER OF THE POPULATION IS 1/N). ALL THAT IS DIFFERENT IS THAT THE ABOVE FORMULAS ARE BASED ON THE PROBABILITY DENSITY FUNCTION OF A RANDOM VARIABLE, WHEREAS THE ORIGINAL FORMULAS WERE INTRODUCED BEFORE THE CONCEPTS OF PROBABILITY, RANDOM VARIABLE, AND THE PROBABILITY DENSITY FUNCTION OF A RANDOM VARIABLE WERE INTRODUCED. THE FORMULAS ARE DIFFERENT, BUT THE RESULTS ARE EXACTLY THE SAME.
THE REASON FOR INTRODUCING THE STATISTICAL THEORY IS NOT TO COMPLICATE THINGS UNNECESSARILY, BUT TO LEAD TO A BETTER UNDERSTANDING OF THE CONCEPTS TO BE INTRODUCED NEXT: STATISTICS, ESTIMATORS, AND SAMPLING DISTRIBUTIONS.
THE PRIMARY GOAL OF SAMPLE SURVEY IS TO OBTAIN ESTIMATES OF THE MEAN AND VARIANCE (AND OTHER QUANTITIES) OF POPULATIONS OF INTEREST, BASED ON SAMPLES FROM THOSE POPULATIONS, AND TO MAKE STATEMENTS ABOUT THE ACCURACY OF THOSE ESTIMATES. THE THEORY OF STATISTICS ENABLES US TO DO THIS.
OPTIONAL: SOME RULES FOR WORKING WITH RANDOM VARIABLES:
IF X AND Y ARE TWO RANDOM VARIABLES, THEN
E(cX) = c E(X)
var(cX) = c2 var(X)
E(X + Y) = E(X) + E(Y).
IF X AND Y ARE INDEPENDENT, THEN var(X + Y) = var(X) + var(Y).
IF g(.) IS A FUNCTION, THEN THE EXPECTATION OF g(X) IS DEFINED AS
E(g(X)) = ![]() .
.
IF X IS DISCRETE, AND
E(g(X)) = ![]()
IF X IS CONTINUOUS.
CHEBYCHEV (TCHEBYCHEFF) INEQUALITY:
![]() for
every k>0.
for
every k>0.
IF WE SET ![]() and
and ![]() , WE
OBTAIN:
, WE
OBTAIN:
![]() FOR
EVERY r>0
FOR
EVERY r>0
OR
![]()
FOR r = 2, WE HAVE ![]() , OR FOR
ANY RANDOM VARIABLE X HAVING FINITE VARIANCE AT LEAST THREE-FOURTHS OF THE
PROBABILITY FALLS WITHIN TWO STANDARD DEVIATIONS OF THE MEAN. (THIS IS NOT A
VERY USEFUL RESULT, SINCE IT HOLDS FOR ALL FINITE-VARIANCE RANDOM
VARIABLES.)
, OR FOR
ANY RANDOM VARIABLE X HAVING FINITE VARIANCE AT LEAST THREE-FOURTHS OF THE
PROBABILITY FALLS WITHIN TWO STANDARD DEVIATIONS OF THE MEAN. (THIS IS NOT A
VERY USEFUL RESULT, SINCE IT HOLDS FOR ALL FINITE-VARIANCE RANDOM
VARIABLES.)
JENSEN’S INEQUALITY. IF g(.) IS A CONVEX FUNCTION,
THEN ![]() .
.
TAYLOR’S APPROXIMATION FOR THE VARIANCE: ![]() , WHERE μ
DENOTES THE EXPECTATION OF X, E(X).
, WHERE μ
DENOTES THE EXPECTATION OF X, E(X).
IF ai DENOTES THE i-TH ELEMENT OF A FINITE
POPULATION (SAMPLE SPACE), AND Prob(ai) = pi, LET
US DEFINE THE RANDOM VARIABLE X(.) AS X(ai) = xi/pi,
WHERE xi DENOTES SOME ATTRIBUTE (SUCH AS INCOME). THEN E(X) =
![]() , THE
POPULATION TOTAL.
, THE
POPULATION TOTAL.
(DESCRIPTIVE) SAMPLING THEORY: SAMPLE; PROBABILITY SAMPLE
WE WILL DRAW CONCLUSIONS (MAKE INFERENCES) ABOUT THE POPULATION BASED ON A SAMPLE SELECTED FROM THE POPULATION. THIS IS INDUCTIVE INFERENCE, NOT DEDUCTIVE INFERENCE, SINCE OUR CONCLUSIONS ARE NOT MADE WITH CERTAINTY.
A SAMPLE IS A COLLECTION OF SAMPLING UNITS, X1, X2,…,Xn DRAWN FROM A FRAME. THE SIZE (NUMBER OF UNITS) OF THE SAMPLE IS DENOTED BY n. THE SAMPLE WILL BE DRAWN IN A SPECIAL WAY, DEPENDING ON THE OBJECTIVES OF THE SURVEY.
MOST AREAS OF STATISTICS (EXPERIMENTAL DESIGN, QUALITY CONTROL, RELIABILITY) APPLICATIONS DEAL WITH RANDOM SAMPLES. A RANDOM SAMPLE IS USUALLY DEFINED AS A SET OF INDEPENDENT AND IDENTICALLY DISTRIBUTED RANDOM VARIABLES (ALL DEFINED ON THE SAME SAMPLE SPACE).
THIS IS NOT THE TYPE OF SAMPLE THAT IS TYPICALLY USED IN (DESCRIPTIVE) SAMPLE SURVEY. IN SAMPLE SURVEY, SOME SAMPLE ELEMENTS MAY BE SELECTED FROM SUBSETS OF THE SAMPLE SPACE (POPULATION), AND THEY ARE NOT NECESSARILY INDEPENDENT. FURTHERMORE, THE PROBABILITY DENSITY FUNCTION USUALLY HAS NO SPECIFIC FORM (E.G., NORMAL, LOGNORMAL, EXPONENTIAL, BINOMIAL).
THE SAMPLES IN SAMPLE SURVEY ARE PROBABILITY SAMPLES (EACH UNIT OF THE SAMPLE IS SELECTED WITH A KNOWN, NONZERO PROBABILITY), BUT NOT THE USUAL “RANDOM SAMPLES” OF STATISTICS (INDEPENDENT AND IDENTICALLY DISTRIBUTED RANDOM VARIABLES).
THE INFERENCES ARE BEING MADE ABOUT THE PARTICULAR FINITE POPULATION AT HAND, NOT ABOUT A HYPOTHETICAL PROCESS THAT MAY HAVE GENERATED IT (CREATED IT AS A SAMPLE, OR “REALIZATION,” FROM A “SUPERPOPULATION” OF POPULATIONS). (IN DAY 2 WE WILL CONSIDER ANALYTICAL SURVEY DESIGNS, WHICH ARE BASED ON A MODEL OF A HYPOTHETICAL PROCESS THAT MAY BE CONSIDERED TO HAVE GENERATED THE PARTICULAR POPULATION AT HAND.)
(FOR DISCUSSION OF THIS CONCEPT, SEE “HISTORY AND DEVELOPMENT OF THE THEORETICAL FOUNDATIONS OF SURVEY BASED ESTIMATION AND ANALYSIS,” BY J. N. K. RAO AND D. R. BELLHOUSE, SURVEY METHODOLOGY, VOL. 16, NO. 1, PP. 3-29 (JUNE 1990) STATISTICS CANADA. RAO AND BELLHOUSE DISCUSS THREE APPROACHES TO SAMPLE SURVEY: DESIGN-BASED (CORRESPONDING TO DESCRIPTIVE SURVEYS), MODEL-DEPENDENT AND MODEL-BASED (OR MODEL-ASSISTED) (THE LATTER TWO CORRESPONDING TO ANALYTICAL SURVEYS). A SAMPLING TEXT THAT INCLUDES DISCUSSION OF THESE CONCEPTS IS SAMPLING: DESIGN AND ANALYSIS 2nd ED., BY SHARON L. LOHR (CENGAGE LEARNING, 2009). MOST OLDER BOOKS ON SAMPLING DO NOT DISCUSS THESE CONCEPTS.)
SAMPLING THEORY (CONT.): STATISTIC; ESTIMATOR
FOR EACH POPULATION QUANTITY OF INTEREST (E.G., POPULATION MEAN, SUBPOPULATION MEANS), WE WISH TO ESTIMATE THE QUANTITY FROM THE SAMPLE.
A STATISTIC IS ANY QUANTITY THAT CAN BE CALCULATED FROM THE SAMPLE (I.E., A FUNCTION OF THE SAMPLE). (A STATISTIC IS A RANDOM VARIABLE; IT DOES NOT DEPEND ON ANY UNKNOWN PARAMETERS, SUCH AS μ OR σ2.)
AN ESTIMATOR IS A STATISTIC USED TO ESTIMATE A POPULATION CHARACTERISTIC (PARAMETER, SUCH AS A MEAN OR TOTAL). (IF A STATISTIC IS USED TO ESTIMATE A POPULATION PARAMETER, THEN IT IS AN ESTIMATOR.)
EXAMPLE OF AN ESTIMATOR: USE THE SAMPLE MEAN TO ESTIMATE THE POPULATION MEAN. (THE VALUE OF THE ESTIMATOR, CALCULATED FROM A PARTICULAR SAMPLE, IS CALLED THE ESTIMATE. THE ESTIMATOR IS A FUNCTION (FORMULA); THE ESTIMATE IS A NUMBER.)
TWO TYPES OF ESTIMATION (ESTIMATORS): POINT ESTIMATION AND INTERVAL ESTIMATION. WE CONSIDER POINT ESTIMATION FIRST.
THE ACADEMIC DISCIPLINE OF SAMPLE SURVEY IS CONCERNED WITH IDENTIFYING “GOOD” ESTIMATORS (ESTIMATORS THAT ARE IN SOME SENSE “CLOSE” TO THE POPULATION VALUES THEY ARE INTENDED TO ESTIMATE), AND IN DETERMINING SAMPLE DESIGNS THAT ASSURE THAT THE ESTIMATES ARE AS “CLOSE” AS DESIRED.
THE APPLIED FIELD OF SAMPLE SURVEY DESIGN AND ANALYSIS IS CONCERNED WITH KNOWING THOSE ESTIMATORS AND SAMPLE DESIGN PROCEDURES.
SAMPLING THEORY (CONT.): PRECISION, TRUENESS/BIAS, ACCURACY
PROPERTIES OF ESTIMATORS:
PRECISION: HOW MUCH VARIATION IS THERE IN THE ESTIMATE, FROM SAMPLE TO SAMPLE
TRUENESS: ON AVERAGE, HOW “CLOSE” IS THE ESTIMATE TO THE POPULATION CHARACTERISTIC BEING ESTIMATED
ACCURACY: A COMBINATION OF PRECISION AND TRUENESS
ISO-5725 (“ACCURACY (TRUENESS AND PRECISION) OF MEASUREMENT METHODS AND RESULTS”) USES THE TERM “TRUENESS”; STATISTICIANS USUALLY USE THE TERM “BIAS” (WHICH HAS THE REVERSE HIGH/LOW SENSE OF TRUENESS).
OTHER TERMS FOR THE CONCEPT OF PRECISION ARE REPEATABILITY AND RELIABILITY (ALL IN THE SAME HIGH/LOW SENSE); AND VARIABILITY, SPREAD AND DISPERSION (REVERSE SENSE).
OTHER TERMS FOR THE CONCEPT OF TRUENESS ARE VALIDITY AND UNBIASEDNESS (SAME HIGH/LOW SENSE); AND BIAS (REVERSE SENSE).
GRAPHIC ILLUSTRATION OF RELATIONSHIP BETWEEN PRECISION, BIAS AND ACCURACY.

THE PRECISION (OF AN ESTIMATOR, X) WILL BE MEASURED BY THE VARIANCE:
![]() ;
;
WHERE ![]() , OR THE STANDARD
DEVIATION:
, OR THE STANDARD
DEVIATION:
![]() .
.
THE TRUENESS OF AN ESTIMATOR WILL BE MEASURED BY THE BIAS, WHICH IS DEFINED AS THE DIFFERENCE BETWEEN THE EXPECTATION OF THE ESTIMATOR AND THE POPULATION PARAMETER OF WHICH IT IS AN ESTIMATE:
![]() .
.
AN ESTIMATOR IS UNBIASED IF ITS EXPECTATION IS EQUAL TO THE POPULATION PARAMETER OF WHICH IT IS AN ESTIMATE.
ACCURACY WILL BE MEASURED BY THE MEAN SQUARED ERROR:
![]() .
.
WE WOULD LIKE ESTIMATORS THAT HAVE LOW VARIANCE (HIGH PRECISION) AND LOW BIAS (COMPARED TO OTHER ESTIMATORS THAT HAVE THE SAME SAMPLE SIZE OR SAMPLING COST).
THERE ARE OTHER PROPERTIES OF ESTIMATORS, SUCH AS CONSISTENCY (THE TENDENCY FOR AN ESTIMATE OF A PARAMETER TO APPROACH THE PARAMERTER VALUE AS THE SAMPLE SIZE INCREASES). THE MOST IMPORTANT PROPERTIES OF ESTIMATORS ARE PRECISION AND BIAS.
PRINCIPAL ITEMS OF INTEREST FOR EACH SAMPLE DESIGN AND ESTIMATION METHOD:
IN WHAT FOLLOWS, WE SHALL PRESENT FORMULAS FOR VARIOUS SAMPLE ESTIMATES OF POPULATION PARAMETERS.
WE SHALL INDICATE WHETHER AN ESTIMATOR IS BIASED OR UNBIASED. WE SHALL ALSO PRESENT FORMULAS FOR THE TRUE VARIANCE OF THE ESTIMATE AND THE SAMPLE ESTIMATE OF THE VARIANCE OF THE ESTIMATE (AND ITS SQUARE ROOT, THE ESTIMATED STANDARD ERROR OF THE ESTIMATE).
THE TRUE VALUE IS OF INTEREST TO HELP US DECIDE ON SAMPLE SIZES, DURING THE COURSE OF DESIGNING A SURVEY.
THE ESTIMATED VALUE IS OF INTEREST TO INDICATE THE PRECISION OF AN ESTIMATE, AFTER THE SURVEY IS COMPLETED AND THE DATA ANALYZED. THE ESTIMATED STANDARD ERROR IS USED TO CONSTRUCT CONFIDENCE INTERVALS.
SAMPLING THEORY (CONT.): NOTES
THERE ARE VARIOUS METHODS FOR DETERMINING ESTIMATORS (METHOD OF MOMENTS, LEAST-SQUARES, MAXIMUM LIKELIHOOD, BAYESIAN METHODS, RAO-BLACKWELL METHOD, MINIMUM CHI-SQUARE, MINIMUM-DISTANCE) AND VARIOUS CRITERIA FOR COMPARING ESTIMATORS (BIAS, VARIANCE, MEAN SQUARED ERROR, CONSISTENCY, SUFFICIENCY, LOCATION/SCALE INVARIANCE). THESE METHODS WILL NOT BE ADDRESSED IN THIS COURSE.
NOTE ON SCOPE OF COURSE: IN THIS COURSE, WE RESTRICT ATTENTION TO STANDARD ESTIMATORS OF COMMON POPULATION PARAMETERS SUCH AS MEANS AND TOTALS, OR RATIOS OR DIFFERENCES AMONG THEM, AND USE LINEAR ESTIMATION TECHNIQUES (LINEAR COMBINATIONS OF THE SAMPLE VALUES). FOR MORE COMPLEX PARAMETERS, SUCH AS SIMPLE AND PARTIAL CORRELATION COEFFICIENTS, MEDIANS, QUANTILES, REGRESSION COEFFICIENTS, MORE ADVANCED METHODS (NONLINEAR ESTIMATION PROCEDURES) ARE REQUIRED. SINCE THE SAMPLING METHODS USED IN SAMPLE SURVEY ARE COMPLEX, THESE ESTIMATION METHODS ARE COMPLICATED (E.G., TAYLOR SERIES EXPANSION, BALANCED REPEATED REPLICATION, THE “JACKKNIFE” METHOD, RESAMPLING).
SAMPLING THEORY (CONT.): EXAMPLE
CONSIDER THE ESTIMATOR THAT IS THE SAMPLE MEAN, FROM A SIMPLE RANDOM SAMPLE DRAWN WITH REPLACEMENT (“SRSWR”).
POPULATION ELEMENTS: x1, x2, …, xN (LOWER CASE SIGNFIES ACTUAL NUMERICAL VALUES)
SAMPLE: X1, X2, …, Xn (UPPER CASE SIGNIFIES RANDOM VARIABLES; FUNCTIONS; CONCEPTUAL)
SAMPLE: x1, x2, …, xn (LOWER CASE SIGNIFIES NUMBERS, IN A SPECIFIC CASE)
NOTE: THE ITEMS x1, x2, …, xn OF THE SAMPLE ARE NOT (NECESSARILY) THE FIRST n ITEMS (x1, x2, …, xn ) OF THE POPULATION.
POPULATION MEAN: 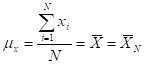
SAMPLE MEAN:
OR 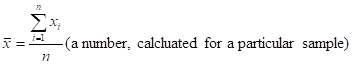
SAMPLING THEORY (CONT.): EXAMPLE (CONT.)
NOTE: THERE IS INCONSISTENCY IN THE FIELD OF STATISTICS IN THE USE OF CAPITAL LETTERS AND LOWER-CASE (“SMALL”) LETTERS. SOME AUTHORS USE CAPITAL LETTERS TO DENOTE RANDOM VARIABLES (FUNCTIONS), AND SMALL LETTERS TO DENOTE REAL NUMBERS (ELEMENTS OF A POPULATION OR SAMPLE, OBSERVED VALUES OF AN ESTIMATOR). OTHERS USE CAPITAL LETTERS TO REFER TO POPULATION PARAMETERS (MEAN, TOTAL) AND SMALL LETTERS TO REFER TO POPULATION ELEMENTS, SAMPLE ELEMENTS, AND SAMPLE ESTIMATORS, WITHOUT DISTINGUISHING BETWEEN RANDOM VARIABLES (FUNCTIONS) AND OBSERVED NUMERICAL VALUES.
WHAT IS EVEN MORE CONFUSING IS THAT MANY AUTHORS USE THE
SAME SYMBOL INTERCHANGEABLY AS A RANDOM VARIABLE OR A REAL NUMBER, WITHOUT
COMMENT. FOR EXAMPLE, IN THE EXPRESSION ![]() ,
, ![]() AND
AND ![]() ARE USED
EITHER AS RANDOM VARIABLES OR AS NUMBERS FROM A PARTICULAR SAMPLE. THIS
PRACTICE MUST BE VERY CONFUSING TO THE NEW STUDENT, BUT IT IS NOT UNUSUAL.
(ANOTHER CONFUSING ITEM IS THE USE OF THE TERM “RANDOM VARIABLE” TO DESCRIBE A
FUNCTION.)
ARE USED
EITHER AS RANDOM VARIABLES OR AS NUMBERS FROM A PARTICULAR SAMPLE. THIS
PRACTICE MUST BE VERY CONFUSING TO THE NEW STUDENT, BUT IT IS NOT UNUSUAL.
(ANOTHER CONFUSING ITEM IS THE USE OF THE TERM “RANDOM VARIABLE” TO DESCRIBE A
FUNCTION.)
IN MATHEMATICAL STATISTICS, THIS DISTINCTION IS VERY IMPORTANT. FOR EXAMPLE, IN THE STATEMENT, Prob(X = x), X REFERS TO A RANDOM VARIABLE (A FUNCTION), AND x REFERS TO A REAL NUMBER. FOR EXAMPLE, Prob(AGE = 27. IN THIS CASE, THE EXPRESSION E(X) REFERS TO THE EXPECTATION (EXPECTED VALUE, MEAN VALUE, AVERAGE VALUE) OF THE RANDOM VARIABLE X, WHICH IS THE MEAN AGE OF THE MEMBERS OF THE POPULATION. THE EXPRESSION E(x) IS SIMPLY THE EXPECTATION OF THE REAL NUMBER, x, WHICH IS x. IN THE EXAMPLE WHERE X = AGE AND x = 27, E(AGE) = μX = 40.3, SAY, BUT E(27)=27.
IN THIS COURSE, CAPITAL LETTERS WILL REFER TO POPULATION PARAMETERS AND TO RANDOM VARIABLES, AND LOWER-CASE LETTERS WILL REFER TO POPULATION ELEMENTS, SAMPLE ELEMENTS, AND THE CALCULATED VALUES OF SAMPLE STATISTICS. LOWER-CASE LETTERS WILL NOT REFER TO RANDOM VARIABLES (UNLESS SPECIFICALLY STATED). ALTERNATIVE NOTATIONS WILL BE PRESENTED, TO FAMILIARIZE THE STUDENT WITH NOTATIONS FOUND IN DIFFERENT REFERENCE TEXTS.
WHILE THIS DISTINCTION IS IMPORTANT CONCEPTUALLY
(MATHEMATICALLY), IT OFTEN IS IGNORED IN PRACTICAL APPLICATIONS. FOR EXAMPLE,
IN RECALLING THE FORMULA USED TO CALCULATE THE SAMPLE MEAN, IT DOES NOT MATTER
WHETHER ONE RECALLS ![]() (A
FORMULA INVOLVING RANDOM VARIABLES) OR
(A
FORMULA INVOLVING RANDOM VARIABLES) OR ![]() (A
FORMULA INVOLVING REAL NUMBERS FROM A PARTICULAR SAMPLE). IN THE INTEREST OF
SIMPLICITY, WE SHALL OFTEN USE THE LATTER TYPE OF EXPRESSION (LOWER-CASE
LETTERS, SAMPLE VALUES) FOR FORMULAS.
(A
FORMULA INVOLVING REAL NUMBERS FROM A PARTICULAR SAMPLE). IN THE INTEREST OF
SIMPLICITY, WE SHALL OFTEN USE THE LATTER TYPE OF EXPRESSION (LOWER-CASE
LETTERS, SAMPLE VALUES) FOR FORMULAS.
SAMPLING THEORY (CONT.): EXAMPLE (CONT.)
IT CAN BE SHOWN THAT:
![]()
AND
![]()
WHERE μX IS THE POPULATION MEAN AND σX2 IS THE POPULATION VARIANCE.
μX IS ESTIMATED (IN SRSWR) BY 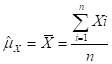 .
.
σX2 IS ESTIMATED (IN SRSWR) BY:
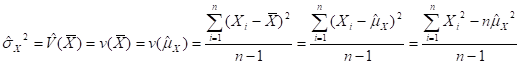 .
.
(THE DIVISOR n-1 IS USED INSTEAD OF n SO THAT ![]() IS
UNBIASED. THE BEST FORMULAS FOR SAMPLE ESTIMATES OF POPULATION PARAMETERS ARE OFTEN
NOT IDENTICAL IN FORM TO THE POPULATION FORMULAS. IN FACT, IN SOME CASES, SUCH
AS ESTIMATING A POWER SPECTRUM IN TIME SERIES ANALYSIS, USING THE POPULATION
FORMULA PRODUCES A TERRIBLE ESTIMATE (IT IS NOT EVEN CONSISTENT).)
IS
UNBIASED. THE BEST FORMULAS FOR SAMPLE ESTIMATES OF POPULATION PARAMETERS ARE OFTEN
NOT IDENTICAL IN FORM TO THE POPULATION FORMULAS. IN FACT, IN SOME CASES, SUCH
AS ESTIMATING A POWER SPECTRUM IN TIME SERIES ANALYSIS, USING THE POPULATION
FORMULA PRODUCES A TERRIBLE ESTIMATE (IT IS NOT EVEN CONSISTENT).)
![]() IS
ESTIMATED (IN SRSWR) BY:
IS
ESTIMATED (IN SRSWR) BY:
![]() .
.
THE QUANTITY ![]() IS CALLED
THE STANDARD ERROR OF THE ESTIMATE,
IS CALLED
THE STANDARD ERROR OF THE ESTIMATE, ![]() , DENOTED
, DENOTED
![]() . (THE
STANDARD ERROR OF THE ESTIMATE IS SIMPLY THE STANDARD DEVIATION OF THE
ESTIMATE, BUT THE TERM “STANDARD ERROR” IS USED INSTEAD OF “STANDARD DEVIATION”
WHEN REFERRING TO THE STANDARD DEVIATION OF ESTIMATES OR POPULATION
PARAMETERS.)
. (THE
STANDARD ERROR OF THE ESTIMATE IS SIMPLY THE STANDARD DEVIATION OF THE
ESTIMATE, BUT THE TERM “STANDARD ERROR” IS USED INSTEAD OF “STANDARD DEVIATION”
WHEN REFERRING TO THE STANDARD DEVIATION OF ESTIMATES OR POPULATION
PARAMETERS.)
IT IS ESTIMATED (IN SRSWR) BY ![]() .
.
SAMPLING THEORY (CONT.): EXAMPLE (CONT.)
HENCE THE SAMPLE MEAN, ![]() , OF A
SIMPLE RANDOM SAMPLE DRAWN WITH REPLACEMENT IS UNBIASED, AND ITS
VARIANCE DECREASES BY THE FACTOR 1/n AS THE SAMPLE SIZE n
INCREASES.
, OF A
SIMPLE RANDOM SAMPLE DRAWN WITH REPLACEMENT IS UNBIASED, AND ITS
VARIANCE DECREASES BY THE FACTOR 1/n AS THE SAMPLE SIZE n
INCREASES.
IT CAN BE SHOWN THAT THE SAMPLE MEAN OF A SIMPLE RANDOM SAMPLE DRAWN WITH REPLACEMENT HAS THE MINIMUM VARIANCE OF ALL UNBIASED ESTIMATORS (OF THE POPULATION MEAN) THAT ARE LINEAR FUNCTIONS OF THE SAMPLE (“BEST LINEAR UNBIASED ESTIMATE,” “BLUE”).
NOTE: THE PRECEDING ESTIMATION FORMULAS APPLY TO SIMPLE RANDOM SAMPLING WITH REPLACEMENT. FOR OTHER METHODS OF SAMPLING, THE FORMULAS ARE DIFFERENT.
NOTE: THE STANDARD ERROR OF THE ESTIMATE IS OF INTEREST MAINLY FOR CONSTRUCTING INTERVAL ESTIMATES (TO BE EXAMINED SHORTLY).
NOTE ALSO:
POPULATION TOTAL =![]() (=
X) = NμX
(=
X) = NμX
SAMPLE ESTIMATE OF POPULATION TOTAL = ![]()
SAMPLING THEORY (CONT.): SAMPLING DISTRIBUTION
SAMPLING DISTRIBUTION OF THE ESTIMATOR (THE PROBABILITY DISTRIBUTION OF A RANDOM VARIABLE).
CONSIDER THE HYPOTHETICAL UNIVERSE OF ALL POSSIBLE SAMPLES FOR ANY METHOD OF SAMPLING. THERE IS A NUMERICAL VALUE OF THE STATISTIC (OR ESTIMATE) FOR EVERY POSSIBLE SAMPLE. THE PROBABILITY DISTRIBUTION OF THIS STATISTIC (ESTIMATE) IS THE SAMPLING DISTRIBUTION OF THE STATISTIC.
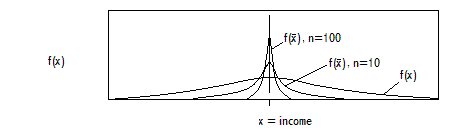
(WEAK) LAW OF LARGE NUMBERS: AS THE SAMPLE SIZE INCREASES, THE SAMPLE MEAN OF A SIMPLE RANDOM SAMPLE DRAWN WITH REPLACEMENT BECOMES VERY CLOSE TO THE POPULATION MEAN (THE PROBABILITY THAT THE SAMPLE MEAN DIFFERS BY ANY SPECIFIED AMOUNT FROM THE POPULATION MEAN DECREASES TO ZERO AS THE SAMPLE SIZE INCREASES TO INFINITY).
CENTRAL LIMIT THEOREM: THE SAMPLING DISTRIBUTION OF THE SAMPLE MEAN (IN SIMPLE RANDOM SAMPLING WITH REPLACEMENT) APPROACHES THE NORMAL DISTRIBUTION (THE “BELL-SHAPED CURVE”) AS THE SAMPLE SIZE APPROACHES INFINITY. IF μX AND σX2 DENOTE THE MEAN AND VARIANCE OF THE POPULATION, THEN THE MEAN AND VARIANCE OF THE LIMITING DISTRIBUTION ARE μX AND σX2 /n. WE WILL DISCUSS THE NORMAL DISTRIBUTION IN GREATER DETAIL SHORTLY.
THE TWO PRECEDING RESULTS ARE TRUE FOR ANY FINITE POPULATION (THEY HOLD FOR RANDOM SAMPLING FROM ANY PROBABILITY DENSITY WITH FINITE VARIANCE).
THESE RESULTS ARE VERY IMPORTANT IN SAMPLE SURVEY. THEY ARE THE BASIS FOR THE ESTIMATION FORMULAS THAT ARE USED TO ANALYZE THE DATA.
THEY ARE VERY USEFUL SINCE THE FORM OF THE PROBABILITY DISTRIBUTION IS USUALLY NOT KNOWN (BUT ALWAYS HAS A FINITE VARIANCE).
THEY ARE APPLICABLE FOR LARGE SAMPLE SIZES (E.G., N>30).
SAMPLING THEORY (CONT.): INTERVAL ESTIMATION
THE PRECISION OF AN ESTIMATE WILL BE DETERMINED, USING THE THEORY OF STATISTICS, BASED ON INFORMATION IN THE SAMPLE.
THE FORMULAS USED TO ESTIMATE THE POPULATION MEAN (OR OTHER CHARACTERISTIC) WILL DEPEND ON THE SAMPLE DESIGN AND SAMPLE SELECTION METHOD.
THE PRECEDING MATERIAL ON ESTIMATION HAS BEEN CONCERNED WITH POINT ESTIMATION OF POPULATION PARAMETERS. WE WILL NOW ADDRESS INTERVAL ESTIMATION.
A POINT ESTIMATE SPECIFIES A SINGLE, “LIKELY,” VALUE AS THE ESTIMATE. WE KNOW SOMETHING ABOUT ITS PRECISION FROM ITS STANDARD ERROR (AND THE THEORY OF STATISTICS).
AN INTERVAL ESTIMATE OF A PARAMETER IS AN INTERVAL THAT HAS A SPECIFIED PROBABILITY OF INCLUDING THE PARAMETER (THE INTERVAL IS THE RANDOM QUANTITY, NOT THE PARAMETER).
CONFIDENCE INTERVAL. LET θ DENOTE A POPULATION PARAMETER (E.G., THE MEAN, μ). LET T1 = t1(X1, …,Xn) AND T2 = t2(X1, …,Xn) BE TWO STATISTICS SATISFYING T1 <= T2 FOR WHICH P(T1 < θ < T2) = α, WHERE α DOES NOT DEPEND ON θ. THEN THE RANDOM INTERVAL (T1,T2) IS CALLED A 100α PERCENT CONFIDENCE INTERVAL FOR θ.
α IS CALLED THE CONFIDENCE COEFFICIENT. T1 AND T2 ARE CALLED THE LOWER AND UPPER CONFIDENCE LIMITS, RESPECTIVELY.
A VALUE (t1, t2) OF THE RANDOM INTERVAL (T1, T2) IS ALSO CALLED A 100α PERCENT CONFIDENCE INTERVAL FOR θ.
(SIMILAR DEFINITIONS FOR ONE-SIDED LOWER AND UPPER CONFIDENCE INTERVALS AND LIMITS.)
NOTE: CONFIDENCE INTERVALS ARE RELATED TO TESTS OF HYPOTHESIS, TO BE DISCUSSED IN DAY 2.
SAMPLING THEORY (CONT.): CONFIDENCE INTERVALS
HOW TO DETERMINE CONFIDENCE INTERVALS: NEED TO USE INFORMATION ABOUT THE SAMPLING DISTRIBUTION OF CERTAIN STATISTICS.
EXAMPLE: FROM PROBABILITY THEORY: CHEBYCHEV
INEQUALITY (FOR ANY STATISTIC FROM A FINITE POPULATION, NOT JUST ![]() ):
):
![]()
SO (SINCE ![]() )
) ![]() IS AN
APPROXIMATE (1 – 1/r2) PERCENT CONFIDENCE INTERVAL FOR μX.
IS AN
APPROXIMATE (1 – 1/r2) PERCENT CONFIDENCE INTERVAL FOR μX.
THE CHEBYCHEV-INEQUALITY METHOD OF CONSTRUCTING CONFIDENCE INTERVALS IS NOT VERY GOOD.
IT IS USUALLY MUCH BETTER TO OBTAIN CONFIDENCE INTERVALS
FROM THE KNOWLEDGE THAT, FOR LARGE SAMPLES, THE SAMPLING DISTRIBUTION OF ![]() TENDS TO
A NORMAL DISTRIBUTION WITH MEAN
TENDS TO
A NORMAL DISTRIBUTION WITH MEAN ![]() AND
VARIANCE
AND
VARIANCE ![]() .
.
SAMPLING THEORY (CONT.): THE NORMAL DISTRIBUTION
THE NORMAL DISTRIBUTION:
PROBABILITY DENSITY FUNCTION: ![]()
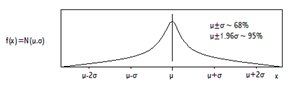
THE STANDARD NORMAL DISTRIBUTION IS THE DISTRIBUTION OF ![]() . IT IS
A NORMAL DISTRIBUTION WITH μ = 0 AND σ = 1):
. IT IS
A NORMAL DISTRIBUTION WITH μ = 0 AND σ = 1): ![]()
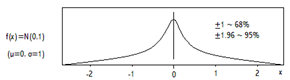
TABLES AVAILABLE. 95% OF THE AREA IS CONTAINED
WITHIN THE INTERVAL μ ![]() 1.96σ.
90% OF THE AREA IS CONTAINED WITHIN THE INTERVAL μ
1.96σ.
90% OF THE AREA IS CONTAINED WITHIN THE INTERVAL μ ![]() 1.645σ.
1.645σ.
SAMPLING THEORY (CONT.): CONFIDENCE INTERVALS
CONFIDENCE INTERVAL FOR ![]() :
:
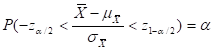
SO (REARRANGING AND SETTING ![]() )
)
![]()
HENCE
![]()
HENCE
![]()
IS A 100α PERCENT CONFIDENCE INTERVAL FOR μ, WHERE zp DENOTES THE p PERCENTILE POINT OF THE NORMAL PROBABILITY DENSITY FUNCTION.
FOR EXAMPLE, z.025 = -1.96 AND z.975 = 1.96, SO
![]()
IS A 95% CONFIDENCE INTERVAL FOR μX.
IN PRACTICE, WE DO NOT KNOW THE VALUE OF ![]() , AND WE
USE THE SAMPLE ESTIMATE,
, AND WE
USE THE SAMPLE ESTIMATE, ![]() , IN ITS PLACE.
IN THIS CASE, HOWEVER, THE PROBABILITY DISTRIBUTION OF
, IN ITS PLACE.
IN THIS CASE, HOWEVER, THE PROBABILITY DISTRIBUTION OF 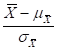 IS NOT
EXACTLY A STANDARD NORMAL DISTRIBUTION. IT IS A STUDENT’S t
DISTRIBUTION, WHICH IS A LITTLE “WIDER” THAN THE STANDARD NORMAL DISTRIBUTION.
A REASONABLE AND CONVENIENT APPROXIMATION IS TO REPLACE THE FACTOR 1.96 BY 2,
AND USE
IS NOT
EXACTLY A STANDARD NORMAL DISTRIBUTION. IT IS A STUDENT’S t
DISTRIBUTION, WHICH IS A LITTLE “WIDER” THAN THE STANDARD NORMAL DISTRIBUTION.
A REASONABLE AND CONVENIENT APPROXIMATION IS TO REPLACE THE FACTOR 1.96 BY 2,
AND USE
![]()
AS A 95% CONFIDENCE INTERVAL.
THE QUANTITY ![]() IS
CALLED THE “BOUND ON THE ERROR OF ESTIMATION OF
IS
CALLED THE “BOUND ON THE ERROR OF ESTIMATION OF ![]() ”.
”.
THE PRECEDING ILLUSTRATED THE CONSTUCTION OF A CONFIDENCE
INTERVAL FOR THE POPULATION MEAN, μ, IN THE CASE OF SIMPLE RANDOM
SAMPLING WITH REPLACEMENT, USING ![]() AS THE
ESTIMATE OF THE POPULATION MEAN, μX, AND
AS THE
ESTIMATE OF THE POPULATION MEAN, μX, AND ![]() AS ITS
ESTIMATED STANDARD ERROR. IN GENERAL, FOR AN ARBITRARY SAMPLE DESIGN (AND
PARAMETER TO BE ESTIMATED), WE CONSTRUCT THE CONFIDENCE INTERVAL USING THE
APPROPRIATE PARAMETER ESTIMATE AND ITS ESTIMATED STANDARD ERROR.
AS ITS
ESTIMATED STANDARD ERROR. IN GENERAL, FOR AN ARBITRARY SAMPLE DESIGN (AND
PARAMETER TO BE ESTIMATED), WE CONSTRUCT THE CONFIDENCE INTERVAL USING THE
APPROPRIATE PARAMETER ESTIMATE AND ITS ESTIMATED STANDARD ERROR.
SAMPLING THEORY (CONT.): DIFFERENT SAMPLING METHODS
WE WILL NOW EXAMINE SEVERAL DIFFERENT TYPES OF SAMPLING USED IN SAMPLE SURVEY:
SIMPLE RANDOM SAMPLING, WITH AND WITHOUT REPLACEMENT
STRATIFIED SAMPLING
CLUSTER SAMPLING
SYSTEMATIC SAMPLING
MULTISTAGE SAMPLING
DOUBLE SAMPLING (TWO-PHASE SAMPLING)
AND TWO ALTERNATIVE TYPES OF ESTIMATION (IN ADDITION TO THE USUAL LINEAR ESTIMATORS):
RATIO ESTIMATORS
REGRESSION ESTIMATORS.
IN DAY ONE OF THE COURSE, WE EXAMINE THE SAMPLING METHODS (DEFINITIONS, SAMPLE SELECTION METHODS, ESTIMATION FORMULAS (POINT ESTIMATES, CONFIDENCE INTERVALS)
IN DAY TWO WE SHOW HOW TO DETERMINE WHICH ONE TO USE, AND HOW TO TAILOR IT TO THE PARTICULAR APPLICATION (I.E., DESIGN THE SURVEY).
A NOTE ON NOTATION…IT IS CUSTOMARY IN STATISTICS TO USE X TO SPECIFY AN ARBITRARY (SINGLE) RANDOM VARIABLE, AND TO USE X1, X2,… OR X, Y, Z,… FOR SEQUENCES OR SETS OF RANDOM VARIABLES. WHEN ONE VARIABLE DEPENDS ON ANOTHER IN SOME WAY (SUCH AS INCOME DEPENDING ON AGE OR EDUCATION), IT IS CUSTOMARY TO USE Y FOR THE “DEPENDENT” VARIABLE AND X’s FOR THE EXPLANATORY (“INDEPENDENT”) VARIABLES. IN SAMPLE SURVEY, IT IS CUSTOMARY TO USE Y FOR AN ARBITRARY RANDOM VARIABLE AND FOR A DEPENDENT VARIABLE.
WHILE IT DOES NOT MATTER THEORETICALLY WHAT SYMBOL IS USED TO REPRESENT A RANDOM VARIABLE, WE SHALL DEFER TO CONVENTION AND HENCEFORTH USE Y, INSTEAD OF X, TO DENOTE AN ARBITRARY RANDOM VARIABLE. (THE CONVENTIONAL NOTATION IS GENERALLY GOOD AND HELPFUL, AND THERE IS NO GOOD REASON TO DEPART FROM IT.) WHETHER X OR Y IS USED IS NOT RELEVANT – ALL THAT MATTERS IS HOW THE RANDOM VARIABLE IS DEFINED. THE CONVENTION OF USING Y TO DENOTE A DEPENDENT VARIABLE (E.G., IN A MULTIPLE REGRESSION EQUATION) IS WELL ESTABLISHED, HOWEVER, AND THERE IS NO REASON FOR DEPARTING FROM IT.
THE NOTATION IN THIS COURSE CLOSELY FOLLOWS THE NOTATION IN SAMPLING TECHNIQUES, 3rd EDITION BY WILLIAM G. COCHRAN (WILEY, 1977) OR ELEMENTARY SURVEY SAMPLING, 7TH EDITION, BY RICHARD L. SCHEAFFER, WILLIAM MENDENHALL, R. LYMAN OTT AND KENNETH G. GEROW (CENGAGE LEARNING, 2011. (COCHRAN HAS MORE FORMULAS, AND IS A MATHEMATICS TEXT. SCHEAFFER IS MUCH SIMPLER, AND PRESENTS JUST THE BASIC RESULTS, WITHOUT PROOF.)
7.2 Simple Random Sampling
SIMPLE RANDOM SAMPLING
(FROM A FINITE POPULATION)
POPULATION SIZE = N, SAMPLE SIZE = n
POPULATION MEAN = ![]()
POPULATION VARIANCE = ![]()
ALSO ![]()
POPULATION TOTAL = ![]()
SAMPLE MEAN (POINT ESTIMATOR OF POP. MEAN) = 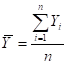 (A RANDOM
VARIABLE)
(A RANDOM
VARIABLE)
OR 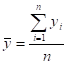 (A
NUMBER, CALCULATED FROM A PARTICULAR SAMPLE).
(A
NUMBER, CALCULATED FROM A PARTICULAR SAMPLE).
SAMPLE VARIANCE = ![]() (A RANDOM
VARIABLE)
(A RANDOM
VARIABLE)
OR ![]() (A
NUMBER, CALCULATED FROM AN ACTUAL SAMPLE).
(A
NUMBER, CALCULATED FROM AN ACTUAL SAMPLE).
SAMPLING WITH REPLACEMENT SAMPLING WITHOUT REPLACEMENT
![]()
![]()
(TRUE) VARIANCE OF ![]()
![]()
![]()
![]()
ESTIMATED VARIANCE OF ![]()
![]()
ESTIMATED STANDARD ERROR OF ![]()
THE FACTOR (N – n)/N = 1 – n/N IS CALLED THE FINITE POPULATION CORRECTION (fpc).
IT SHOWS HOW MUCH LOWER THE VARIANCE OF THE ESTIMATE IS WITH SAMPLING WITHOUT REPLACEMENT, COMPARED TO SAMPLING WITH REPLACEMENT.
(NOTE: HERE, AND IN THE SAMPLING METHODS THAT FOLLOW, IF THE TOTAL POPULATION SIZE IS NOT KNOWN, THEN REPLACE THE fpc BY 1.)
95% CONFIDENCE INTERVAL FOR THE POPULATION MEAN: ![]() .
.
AS NOTED EARLIER, THE TERM ![]() IS CALLED
THE “BOUND ON THE ERROR OF ESTIMATION OF
IS CALLED
THE “BOUND ON THE ERROR OF ESTIMATION OF ![]() .”
.”
SIMPLE RANDOM SAMPLING WITH BINARY DATA
(SAME FORMULAS APPLY, BUT THEY SIMPLIFY)
EACH yi = 0 OR 1
POPULATION MEAN = ![]()
POPULATION VARIANCE = σ2 = ![]()
ALSO ![]()
SAMPLE MEAN = 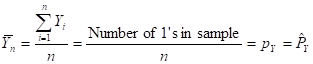
SAMPLE VARIANCE = ![]()
SAMPLING WITH REPLACEMENT SAMPLING WITHOUT REPLACEMENT
(DROP THE SUBSCRIPT Y.)
![]()
![]()
(TRUE) VARIANCE OF ![]()
![]()
![]()
![]()
ESTIMATED VARIANCE OF ![]()
![]()
ESTIMATED STANDARD ERROR OF ![]()
95% CONFIDENCE INTERVAL FOR P: ![]()
SELECTING RANDOM SAMPLES
RANDOMNESS IS A PROPERTY OF THE PROCESS GENERATING THE “RANDOM” NUMBERS – IT CANNOT BE PROVED FROM THE NUMBERS THEMSELVES.
TABLES OF RANDOM NUMBERS
ENTER TABLE RANDOMLY
DOCUMENT STARTING POINT AND RECORD SELECTED NUMBERS
USE A TABLE FROM AN ACCESSIBLE (IN-PRINT) SOURCE (SO THAT YOUR SELECTION CAN BE DOCUMENTED AND VERIFIED BY OTHERS, BY ACCESSING THAT SOURCE AND SEEING THE NUMBERS YOU SELECTED).
SYSTEMATIC SAMPLING (WILL BE TREATED IN GREATER DETAIL LATER)
SELECT EVERY k-th ITEM FROM A LIST OF THE SAMPLE UNITS (FRAME).
APPROPRIATE IF LIST IS IN RANDOM ORDER (E.G., PREPARED ARBITRARILY), BUT IT OFTEN PRODUCES INCREASES IN PRECISION IF THE LIST IS NOT IN RANDOM ORDER (E.G., A TREND IS PRESENT).
IF LIST IS NOT IN RANDOM ORDER, THEN THE SAMPLE IS NOT RANDOM, AND RESULTS MAY BE BIASED. THE GREATEST DANGER IS IF THERE IS SOME SORT OF PERIODICITY IN THE LIST.
EVERY k-th UNIT IS SELECTED FROM THE LIST, k=N/n.
IF IT IS SUSPECTED THAT THE LIST IS NOT IN RANDOM ORDER, THEN SELECT A NUMBER OF SYSTEMATIC SAMPLES (FOR EXAMPLE, TEN SYSTEMATIC SAMPLES, EACH WITH INTERVAL 10k, AND EACH STARTING FROM A NEW RANDOM STARTING POINT).
COMPUTER-GENERATED (“PSEUDORANDOM”) NUMBERS. GENERATED BY MATHEMATICAL FORMULAS, STARTING WITH A “SEED”: REPRODUCIBLE, DOCUMENTABLE.
MATHEMATICAL / STATISTICAL SOFTWARE PACKAGES (E.G., PROC SURVEYSELECT IN SAS).
RANDOM NUMBERS GENERATED BY A HAND CALCULATOR ARE GENERALLY NOT REPRODUCIBLE. OK FOR “PERSONAL USE,” BUT NOT FOR PAID WORK FOR A CLIENT. RANDOM NUMBERS GENERATED BY AN INTERNET WEBSITE MAY BE REPRODUCIBLE, BUT ONLY AS LONG AS THE GENERATOR USED REMAINS SUPPORTED AND AVAILABLE ON THE WEBSITE; THEY ARE NOT RECOMMENDED.
REASON FOR DOCUMENTATION:
· REVIEW OF WORK (TO ENSURE / ESTABLISH CORRECTNESS OF SAMPLING PROCEDURES)
· LEGAL TESTIMONY (TO PROVE CORRECTNESS IN A COURT OF LAW)
ESTIMATION OF SAMPLE SIZE
SIMPLE RANDOM SAMPLING WITH REPLACEMENT (“SRSWR”)
A RECOMMENDED SAMPLE SIZE MAY BE DETERMINED BY SPECIFYING A BOUND (LIMIT, NUMERICAL VALUE) ON THE STANDARD ERROR OF THE ESTIMATE (OR THE SIZE OF A 95% CONFIDENCE INTERVAL), SETTING THIS VALUE EQUAL TO THE THEORETICAL FORMULA FOR THE BOUND, AND SOLVING FOR n.
EXAMPLE:
SUPPOSE THAT WE WANT A 95% CONFIDENCE INTERVAL FOR THE
POPULATION MEAN TO BE OF SIZE ![]() .
.
THEN, SINCE THE FORMULA FOR A 95% CONFIDENCE INTERVAL (IN
SRSWR) IS ![]() ,
WE SET
,
WE SET ![]() AND
SOLVE FOR n:
AND
SOLVE FOR n:
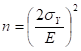
TO USE THIS FORMULA, WE TO SPECIFY E, AND WE NEED AN ESTIMATE OF THE STANDARD DEVIATION, σY.
THIS IS OBTAINED FROM PREVIOUS SURVEYS, REPORTS, OR JUDGMENT (E.G., IF WE JUDGE THAT MOST OF THE POPULATION COVERS A RANGE OF 200,000, THEN WE COULD ESTIMATE σY = 200,000/4 = 50,000).
FOR EXAMPLE, IF σY = 50,000 AND E=5,000, THEN n = 400.
THE PRECEDING METHOD FOR DETERMINING SAMPLE SIZE DOES NOT TAKE COST (BUDGET RESTRICTIONS) INTO ACCOUNT. IT IS APPROPRIATE FOR SRSWR OR FOR SRSWOR IF N IS LARGE.
NOTE THAT IN DETERMINING SAMPLE SIZES, WE USE THE FORMULAS FOR THE POPULATION (TRUE) VALUES OF THE VARIANCE OR STANDARD ERROR OF THE ESTIMATE – WE DO NOT USE THE SAMPLE FORMULAS SINCE WE ARE NOT USING SAMPLE DATA (WE DO NOT YET HAVE A SAMPLE!).
GENERAL NOTE ON SAMPLE SIZE DETERMINATION FOR DESCRIPTIVE SURVEYS (NOT JUST SIMPLE RANDOM SAMPLING)
A FREE COMPUTER PROGRAM FOR DETERMINING SAMPLE SIZES, BOTH FOR SIMPLE RANDOM SAMPLING AND FOR MORE COMPLEX DESIGNS, IS AVAILABLE FROM BRIXTON HEALTH (A PUBLIC HEALTH AND EPIDEMIOLOGY CONSULTANCY IN LIVERPOOL, ENGLAND, UK) AT http://www.brixtonhealth.com/samplexs.html .
THE COMPUTER PROGRAM USED BY THE AUTHOR TO DETERMINE SAMPLE SIZES FOR SURVEYS (BOTH SIMPLE AND COMPLEX) IS POSTED AT http://www.foundationwebsite.org/SampleSize.exe . IT IS DESIGNED PRIMARILY FOR USE IN DETERMINING SAMPLE SIZES FOR ANALYTICAL SURVEYS. FOR DESCRIPTIVE SURVEYS, THE USUAL APPROACH TO SAMPLE SIZE DETERMINATION IS TO SPECIFY A DESIRED LEVEL OF PRECISION (FOR AN ESTIMATE OF INTEREST) AND TO DETERMINE THE SAMPLE SIZE THAT PRODUCES THAT LEVEL OF PRECISION. FOR ANALYTICAL SURVEYS, THE USUAL APPROACH IS TO SPECIFY A DESIRED LEVEL OF POWER FOR A SPECIFIED TEST OF HYPOTHESIS (E.G., ABOUT THE SIZE OF A “DOUBLE DIFFERENCE” ESTIMATE), AND TO DETERMINE THE SAMPLE SIZE THAT PRODUCES THAT LEVEL OF POWER.
THERE ARE MANY OTHER SOURCES OF INFORMATION ABOUT SAMPLE SURVEY DESIGN AND SAMPLING ON THE INTERNET WORLD WIDE WEB.
ESTIMATION OF SAMPLE SIZE
SIMPLE RANDOM SAMPLING WITH REPLACEMENT (“SRSWR”)
IN SAMPLING FOR PROPORTIONS, ![]() (DROPPING
THE SUBSCRIPT X), SO
(DROPPING
THE SUBSCRIPT X), SO
![]() .
.
TO USE THIS FORMULA, WE NEED TO SPECIFY THE PROPORTION, P.
SINCE P(1-P) ASSUMES ITS MAXIMUM VALUE FOR P=.5,
THE MAXIMUM SIZE FOR A 95% CONFIDENCE INTERVAL, ![]() , IS
, IS ![]() , AND SO,
SETTING
, AND SO,
SETTING ![]() AND
SOLVING FOR n, WE OBTAIN THE REQUIRED SAMPLE SIZE AS:
AND
SOLVING FOR n, WE OBTAIN THE REQUIRED SAMPLE SIZE AS:
![]() .
.
FOR EXAMPLE, IF E =.05, THEN n = 400. IF E = .03 THEN n = 1,111. (NOTE: MANY TELEVISION OPINION POLLS HAVE n = 1,000, AND HAVE AN ERROR OF ESTIMATION OF ABOUT .03.)
NOTE: AN ADVANTAGE OF DETERMINING SAMPLE SIZES FOR SAMPLING FOR PROPORTIONS IS THAT THE VARIANCE (OF THE ESTIMATE OF THE MEAN) IS A FUNCTION OF THE (TRUE) MEAN. HENCE, WE CAN DETERMINE THE SAMPLE SIZE SIMPLY BY SPECIFYING THE MEAN. THE SAMPLE SIZE IS OFTEN (BUT NOT ALWAYS) DETERMINED BY SETTING THE VALUE OF p EQUAL TO .5 (SINCE THIS VALUE PRODUCES THE MAXIMUM VALUE OF n).
ESTIMATION OF THE POPULATION TOTAL
(SIMPLE RANDOM SAMPLING WITHOUT REPLACEMENT)
THE POPULATION MEAN IS ![]() .
.
THE POPULATION TOTAL IS ![]() .
.
AN ESTIMATOR OF THE POPULATION TOTAL IS
![]() .
.
THE ESTIMATED VARIANCE OF ![]() IS
IS
![]() .
.
THE “BOUND ON THE ERROR OF ESTIMATION” IS![]() .
.
FOR SIMPLE RANDOM SAMPLING WITH REPLACEMENT, SIMPLY DROP THE
FINITE POPULATION CORRECTION (fpc), ![]() .
.
THE CALCULATION OF SAMLE SIZE PROCEEDS AS IN THE CASE OF ESTIMATION OF THE POPULATION MEAN, BUT WITH THE DIFFERENT FORMULA FOR THE VARIANCE.
SAMPLING VARIANCE OF OTHER STATISTICS (SRSWR)
(MEDIAN, PERCENTILES, STANDARD DEVIATION, COEFFICIENT OF VARIATION)
IN THE PRECEDING, WE HAVE GIVEN FORMULAS FOR THE VARIANCES
(TRUE AND ESTIMATED) OF THE SAMPLE MEAN, ![]() , AND THE
ESTIMATED POPULATION TOTAL,
, AND THE
ESTIMATED POPULATION TOTAL, ![]() .
.
HERE ARE STANDARD ERRORS FOR SOME OTHER STATISTICS:
IF THE PARENT POPULATION IS NORMAL, THE STANDARD ERROR OF
THE SAMPLE MEDIAN IS 1.25![]()
IF THE PARENT POPULATION IS NORMAL, THE STANDARD ERROR OF
THE SAMPLE COEFFICIENT OF VARIATION IS ![]() , WHERE CV
DENOTES THE POPULATION COEFFICIENT OF VARIATION.
, WHERE CV
DENOTES THE POPULATION COEFFICIENT OF VARIATION.
IF THE PARENT POPULATION IS NORMAL, THE STANDARD ERROR OF
THE SAMPLE STANDARD DEVIATION IS ![]() .
.
SUMMARY OF MAIN RESULTS
THE GOAL IS ESTIMATION OF FINITE-POPULATION PARAMETERS: MEAN
(![]() ), TOTAL
(
), TOTAL
(![]() ). THE
FOLLOWING ARE THE MAIN FORMULAS INVOLVED:
). THE
FOLLOWING ARE THE MAIN FORMULAS INVOLVED:
FORMULAS FOR ESTIMATORS OF THE
POPULATION PARAMETERS: SAMPLE MEAN (![]() ),
ESTIMATED POPULATION TOTAL (
),
ESTIMATED POPULATION TOTAL (![]() ).
).
(FROM THIS POINT ON, WE WILL USE ![]() RATHER
THAN Y, TO DENOTE THE POPULATION TOTAL, TO AVOID CONFUSION WITH THE
SYMBOL Y USED TO DENOTE A RANDOM VARIABLE.)
RATHER
THAN Y, TO DENOTE THE POPULATION TOTAL, TO AVOID CONFUSION WITH THE
SYMBOL Y USED TO DENOTE A RANDOM VARIABLE.)
FORMULAS FOR THE TRUE VALUES OF THE VARIANCES OR STANDARD DEVIATIONS (STANDARD ERRORS) OF THE ESTIMATORS. (THESE ARE USED IN THE ESTIMATION OF THE SAMPLE SIZES REQUIRED TO ACHIEVE SPECIFIED LEVELS OF PRECISION.)
FORMULAS FOR ESTIMATING THE
STANDARD ERRORS OF THE SAMPLE ESTIMATES: STANDARD ERROR OF ![]() ,
STANDARD ERROR OF
,
STANDARD ERROR OF ![]() . (THESE
ARE USED TO INDICATE THE LEVEL OF PRECISION OF THE SAMPLE ESTIMATES.)
. (THESE
ARE USED TO INDICATE THE LEVEL OF PRECISION OF THE SAMPLE ESTIMATES.)
BOUND ON THE ERROR OF ESTIMATION (TWICE THE ESTIMATED STANDARD ERROR OF THE ESTIMATE)
95% CONFIDENCE INTERVAL: THE
ESTIMATE ![]() TWICE
THE ESTIMATED STANDARD ERROR OF THE ESTIMATE
TWICE
THE ESTIMATED STANDARD ERROR OF THE ESTIMATE
THE ABOVE SUMMARY WILL APPLY NOT JUST TO SIMPLE RANDOM SAMPLING (WITH OR WITHOUT REPLACEMENT), BUT TO MANY OF THE OTHER TYPES OF SAMPLING TO BE DISCUSSED.
SO, IN GENERAL, ALL WE REALLY NEED TO KNOW ABOUT EACH SURVEY DESIGN IS WHAT IS THE FORMULA FOR A GOOD ESTIMATE (OF A SPECIFIED POPULATION PARAMETER, SUCH AS THE POPULATION MEAN OR TOTAL), AND THE FORMULA FOR THE STANDARED ERROR OF THE ESTIMATE. FROM THIS WE CAN STATE THE “BOUND ON THE ERROR OF ESTIMATION” (TWICE THE STANDARD ERROR OF THE ESTIMATE) AND A 95% CONFIDENCE INTERVAL.
USING SUPPLEMENTARY (AUXILIARY) INFORMATION TO ASSIST SURVEY DESIGN
IF NOTHING IS KNOWN ABOUT THE POPULATION IN ADVANCE OF SAMPLING (EXCEPT FOR A LIST OF SAMPLING UNITS), THEN SIMPLE RANDOM SAMPLING IS ALL THAT CAN BE DONE.
INFORMATION KNOWN ABOUT THE POPULATION PRIOR TO SAMPLING CAN ENABLE THE CONSTRUCTION OF AN IMPROVED (MORE EFFICIENT) SAMPLE DESIGN (HIGHER PRECISION FOR THE SAME SAMPLING EFFORT (SMALLER SAMPLE, LOWER COST), OR ACHIEVEMENT OF A SPECIFIED LEVEL OF PRECISION FOR LESS SAMPLING EFFORT).
THIS INFORMATION MAY BE ABOUT THE PRIMARY VARIABLE(S) OF INTEREST, OR ABOUT VARIABLES RELATED TO THEM (E.G., IN AN INCOME SURVEY, MAY KNOW LAST YEAR’S INCOME, OR VARIABLES RELATED TO INCOME, SUCH AS QUALITY OF NEIGHBORHOOD, OR AGE, OR EDUCATION).
THIS INFORMATION MAY BE QUALITATIVE OR QUANTITATIVE, BUT IT MUST BE DETERMINABLE FOR EACH SAMPLE UNIT IN THE FRAME.
QUALITATIVE (NOMINAL):
RICH OR POOR (NEIGHBORHOODS, SOIL REGIONS)
ADVANCED OR RETARDED (ECONOMIC REGIONS)
MORE OR LESS DENSLY POPULATED
URBAN OR RURAL
RESIDENCE, ETHNICITY
QUANTITATIVE (ORDINAL, INTERVAL):
INCOME DATA WHEN SURVEYING EXPENDITURE DATA
HEIGHT WHEN ESTIMATING WEIGHT
AGE WHEN ESTIMATING BLOOD PRESSURE
SEX WHEN ESTIMATING MARKET PREFERENCES
EDUCATIONAL LEVEL OR NATIONALITY WHEN SURVEYING ATTITUDES
POLITICAL AFFILIATION WHEN SURVEYING POLITICAL OPINIONS
SAMPLING COSTS (URBAN, RURAL) WHEN SURVEYING SCHOOLS
THIS INFORMATION WILL ENABLE US TO CONSTRUCT A VARIETY OF SURVEY DESIGNS THAT ARE MORE EFFICIENT THAN SIMPLE RANDOM SAMPLING:
STRATIFIED SAMPLING
CLUSTER SAMPLING
MULTISTAGE SAMPLING
DOUBLE SAMPLING (TWO-PHASE SAMPLING)
7.3 Stratified Random Sampling
STRATIFIED RANDOM SAMPLING
DEFINITION: A STRATIFIED RANDOM SAMPLE IS ONE OBTAINED BY SEPARATING THE SAMPLE UNITS (POPULATION ELEMENTS) INTO NONOVERLAPPING GROUPS, CALLED STRATA, AND SELECTING A SIMPLE RANDOM SAMPLE FROM EACH STRATUM.
THE STRATA ARE DEFINED ON THE BASIS OF AUXILIARY INFORMATION.
REASONS (INDICATIONS) FOR STRATIFICATION:
1. POPULATION ELEMENTS ARE MORE HOMOGENEOUS (LESS VARIABLE) WITHIN STRATA THAN IN THE GENERAL POPULATION (WITH RESPECT TO THE VARIABLES OF INTEREST).
2. COST OF SAMPLING MAY BE LOWER IN SOME STRATA (ADMINISTRATIVE CONVENIENCE).
3. ESTIMATES OF POPULATION PARAMETERS (I.E., MEANS, PROPORTIONS, VARIANCES) CAN BE READILY OBTAINED FOR EACH STRATUM.
EXAMPLE1:
IN A COUNTY CONTAINING FIVE VOTING DISTRICTS, WE WISH TO ESTIMATE THE PROPORTION OF REGISTERED VOTERS WHO FAVOR A PARTICULAR ELECTION CANDIDATE. WE WANT AN OVERALL ESTIMATE FOR THE COUNTY AND ESTIMATES FOR EACH VOTING DISTRICT. A LIST OF REGISTERED VOTERS IS AVAILABLE. A SAMPLE OF 100 VOTERS IS SELECTED FROM EACH DISTRICT.
THE DATA ARE COLLECTED AND ANALYZED (USING FORMULAS TO BE PRESENTED), AND THE PROPORTIONS ARE ESTIMATED FOR THE COUNTY AND EACH DISTRICT.
EXAMPLE 2:
IT IS DESIRED TO ESTIMATE THE TOTAL NUMBER OF COMPUTERS IN ALL SCHOOLS IN ZAMBIA. IT IS KNOWN THAT MOST RURAL SCHOOLS AND MOST SMALL SCHOOLS DO NOT HAVE COMPUTERS. ALSO, IT IS KNOWN THAT MANY PRIVATE SCHOOLS DO HAVE COMPUTERS. IT IS ALSO KNOWN THAT MOST LARGE SCHOOLS ARE IN URBAN AREAS. RECENT DATA ON SCHOOL SIZE AND OWNERSHIP ARE KNOWN FROM LAST YEAR’S ANNUAL SCHOOL CENSUS.
IN THIS CASE, USE OF A STRATIFIED SAMPLE DESIGN, WITH STRATIFICATION BY SCHOOL SIZE, URBAN/RURAL STATUS, AND OWNERSHIP STATUS, WOULD PROBABLY BE A GOOD CHOICE. (NOTE: FEW PRACTICAL SAMPLE SURVEYS COLLECT DATA ON ONLY ONE VARIABLE. WHILE THIS DESIGN MAY BE GOOD FOR ESTIMATING THE TOTAL NUMBER OF COMPUTERS, IT WOULD NOT NECESSARILY BE THE BEST FOR ESTIMATING SOME OTHER PARAMETER, SUCH AS THE TYPE OF WATER SOURCE FOR THE SCHOOL (NONE, WELL, PUMP, MUNICIPAL WATER). ALL OF THE SURVEY OBJECTIVES AND CONSTRAINTS MUST BE CONSIDERED TOGETHER IN DESIGNING THE SURVEY.
STRATIFIED RANDOM SAMPLING
NOTATION / ESTIMATION FORMULAS
NUMBER OF STRATA: L
WILL USE THE SUFFIX / SUBSCRIPT h TO DENOTE AN ARBITRARY STRATUM, AND SUFFIX / SUBSCRIPT iI TO DENOTE AN ARBITRARY UNIT WITHIN A STRATUM.
NUMBER OF UNITS (IN STRATUM h) = “SIZE” OF STRATUM h: Nh
NUMBER OF UNITS IN SAMPLE (IN STRATUM h): nh
VALUE OF THE i-th UNIT: yhi
STRATUM WEIGHT: ![]()
SAMPLING FRACTION: ![]()
TRUE MEAN: 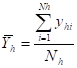
SAMPLE MEAN: 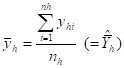
TRUE VARIANCE: 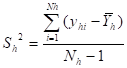
(WILL USE S2 RATHER THAN σ2, SINCE (1) IT IS CUSTOMARY IN SAMPLE SURVEY; AND (2) THE FORMULAS ARE A LITTLE SIMPLER.)
SAMPLE VARIANCE: ![]()
TOTAL POPULATION SIZE: N = N1 + N2 + … + Nk
TOTAL SAMPLE SIZE: n = n1 + n2 + … + nk
THE POPULATION TOTAL, MEAN AND VARIANCE ARE DEFINED THE SAME AS BEFORE.
STRATIFIED RANDOM SAMPLING
ESTIMATION FORMULAS
![]()
![]()
![]()
ESTIMATE OF THE POPULATION MEAN (st STANDS FOR “STRATIFIED”):
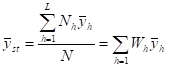
THIS IS NOT, IN GENERAL, THE SAME AS THE SAMPLE MEAN, WHICH IS:
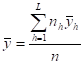
THE ESTIMATE ![]() IS EQUAL
TO
IS EQUAL
TO ![]() ONLY IF:
ONLY IF:
![]()
I.E., IF THE STRATIFICATION INVOLVES A PROPORTIONAL ALLOCATION OF THE SAMPLE TO THE STRATA (SAMPLE SIZES PROPORTIONAL TO STRATUM SIZES), THEN THE SAMPLE IS SAID TO BE “SELF-WEIGHTING.”
STRATIFIED RANDOM SAMPLING
ESTIMATION FORMULAS / MAJOR RESULTS
MAJOR RESULTS:
THE ESTIMATE ![]() IS AN
UNBIASED ESTIMATE OF THE POPULATION MEAN,
IS AN
UNBIASED ESTIMATE OF THE POPULATION MEAN, ![]() , I.E.,
, I.E.,
![]()
THE TRUE VARIANCE OF ![]() IS:
IS:
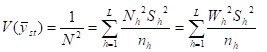
AN UNBIASED ESTIMATE OF THE VARIANCE OF ![]() IS:
IS:
![]()
APPROXIMATE 95% CONFIDENCE LIMITS ARE HENCE AS FOLLOWS:
FOR THE POPULATION MEAN:
![]()
FOR THE POPULATION TOTAL:
![]()
THE ESTIMATION OF SAMPLE SIZES IS COMPLICATED FOR STRATIFIED SAMPLING, BECAUSE THERE ARE MANY SAMPLE SIZES INVOLVED (I.E., ONE FOR EACH STRATUM).
IN MANY APPLICATIONS, THE STRATA ARE SUBPOPULATIONS OF SPECIAL INTEREST, SUCH AS URBAN/RURAL OR MALE/FEMALE OR COUNTRY REGIONS, AND SEPARATE ESTIMATES ARE DESIRED FOR EACH SUCH STRATUM. IN THESE CASES, THE SAMPLE-SIZE FORMULAS FOR SIMPLE RANDOM SAMPLING APPLY TO DETERMINE THE SAMPLE SIZE FOR EACH SUCH STRATUM.
STRATIFIED RANDOM SAMPLING
ALLOCATION OF SAMPLE TO STRATA
PROPORTIONAL ALLOCATION (SELF-WEIGHTING):
![]()
OPTIMAL (MINIMUM VARIANCE), IF COST OF SAMPLING IS THE SAME IN ALL STRATA, BUT THE STRATUM VARIANCES MAY DIFFER:
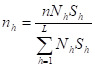
THIS IS CALLED THE “NEYMAN” ALLOCATION.
OPTIMAL (MINIMUM VARIANCE), WITH SAMPLING COST FUNCTION (“LINEAR” COST FUNCTION):
COST =![]()
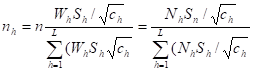
GUIDELINES: TAKE A LARGER SAMPLE IN A STRATUM IF
- THE STRATUM IS LARGER
- THE STRATUM IS MORE VARIABLE INTERNALLY
- SAMPLING IS CHEAPER IN THE STRATUM
THE MORE WE KNOW ABOUT THE VARIABLE OF INTEREST (y), THE BETTER JOB WE CAN DO OF STRATIFICATION. IN SOME CASES, IT MAY BE WORTHWHILE TO CONDUCT A PRELIMINARY SAMPLE TO OBTAIN SOME INFORMATION THAT WOULD ASSIST STRATIFICATION (TWO-PHASE SAMPLING, OR DOUBLE SAMPLING).
IN SAMPLING FOR PROPORTIONS, THE FORMULAS BECOME A LITTLE SIMPLER – SEE A TEXT ON SAMPLE SURVEY FOR THE FORMULAS IN THAT CASE.
SYSTEMATIC SAMPLING: WHEN THE UNITS ARE ARRANGED IN DESCENDING OR ASCENDING ORDER, THEN SYSTEMATIC SAMPLING HAS A SIMILAR EFFECT AS STRATIFICATION. (WE ADDRESS SYSTEMATIC SAMPLING LATER.)
GAINS IN PRECISION FROM STRATIFICATION
THE GAIN IN PRECISION FROM STRATIFICATION OVER SIMPLE RANDOM SAMPLING DEPENDS MAINLY (APART FROM COST CONSIDERATIONS) ON HOW MUCH LESS THE VARIATION WITHIN STRATA IS COMPARED TO THE VARIATION OVER THE GENERAL POPULATION.
A SIMPLE MODEL.
CONSIDER THE CASE IN WHICH THE OBSERVED RANDOM VARIABLE, X, IS THE SUM OF TWO INDEPENDENT RANDOM VARIABLES, A “STRATUM” COMPONENT, XS, AND A “WITHIN-STRATUM” COMPONENT, XW:
X = XS + XW
SUPPOSE THAT E(XS) = μS, E(XW) = 0, V(XS) = σS2 AND V(XW) = σW2.
THEN V(X) = V(XS) + V(XW), OR σ2 = σS2 + σW2.
SUPPOSE THAT THERE ARE L STRATA AND THAT AN EQUAL NUMBER OF UNITS, nS, IS SELECTED FROM EACH STRATUM. THE TOTAL SAMPLE SIZE IS n = LnS.
THE ESTIMATOR OF THE POPULATION MEAN IS:
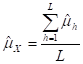
WHERE
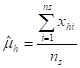 .
.
ITS VARIANCE IS:
![]() .
.
THE VARIANCE OF A SIMPLE RANDOM SAMPLE (WITH REPLACEMENT) OF SIZE n = Lns IS:
![]() .
.
SO THE RATIO OF THE VARIANCES OF STRATIFIED RANDOM SAMPLING TO SIMPLE RANDOM SAMPLING IN THIS CASE IS σW2/σ2.
ALTERNATIVE ESTIMATION TECHNIQUES: RATIO AND REGRESSION ESTIMATORS
RATIO ESTIMATORS (IN SIMPLE RANDOM SAMPLING)
VARIABLE OF PRIMARY INTEREST (“RESPONSE” VARIABLE): Y
SUPPOSE THAT THERE IS ANOTHER (“AUXILIARY”) VARIATE, X,
CORRELATED WITH Y, AND KNOWN FOR EACH UNIT OF THE SAMPLE, AND FOR WHICH
WE KNOW THE POPULATION TOTAL, ![]() .
.
SUPPOSE FURTHER THAT THE RELATIONSHIP BETWEEN THE RESPONSE VARIABLE AND THE AUXILIARY VARIABLE IS LINEAR THROUGH THE ORIGIN:
THEN A RATIO ESTIMATOR IS A GOOD CHOICE. IT IS, IN FACT, THE BEST CHOICE IF THE VARIANCE OF THE RESPONSE VARIABLE, Y, ABOUT THE LINE IS PROPORTIONAL TO X.
THE RATIO ESTIMATE OF ![]() , THE
POPULATION TOTAL (FOR Y) IS:
, THE
POPULATION TOTAL (FOR Y) IS:
![]()
(THE PRECEDING IS SHEAFFER’S NOTATION. IN COCHRAN’S NOTATION, USING X AND Y TO DENOTE THE POPULATION TOTALS, THIS FORMULA IS:
![]()
WHERE x AND y DENOTE THE SAMPLE TOTALS OF THE xi AND yi, RESPECTIVELY, AND X DENOTES THE POPUATION TOTAL FOR THE xi. THIS NOTATION IS CONFUSING, SINCE X REFERS BOTH TO A RANDOM VARIABLE AND A POPULATION TOTAL (OF THE xi), AND x, WHICH WOULD NORMALLY REFER TO A SPECIFIC VALUE OF THE X RANDOM VARIABLE, INSTEAD REFERS TO THE SAMPLE TOTAL OF THE xi.)
THE RATIO ESTIMATE OF![]() , THE
POPULATION MEAN (FOR Y) IS:
, THE
POPULATION MEAN (FOR Y) IS:
![]()
(OR, IN COCHRAN’S NOTATION:
![]() ).
).
THE RATIO ESTIMATE IS BIASED, BUT THE BIAS IS NEGLIGIBLE IN LARGE SAMPLES. IT IS CONSISTENT, I.E., ITS AVERAGE TENDS TO THE TRUE VALUE AS THE SAMPLE SIZE INCREASES.
NOTE: FROM THIS POINT ON IN THIS COURSE, WE WILL NOT PRESENT FORMULAS FOR THE TRUE VARIANCES OF ALL OF THE SAMPLE ESTIMATES DISCUSSED. THE TRUE VARIANCE IS NEEDED TO DETERMINE SAMPLE SIZE, BUT IT IS NOT USED IN THE ANALYSIS OF THE SAMPLE DATA. THE FORMULAS FOR THE ESTIMATED VARIANCES (BASED ON THE SAMPLE DATA) WILL ALWAYS BE PRESENTED (SINCE THEY ARE ALWAYS NEEDED IN THE ANALYSIS OF THE SAMPLE DATA), BUT THE TRUE FORMULAS WILL BE PRESENTED ONLY WHEN ADDRESSING THE PROBLEM OF DETERMINING SAMPLE SIZE (IN ADVANCE OF THE SURVEY). STANDARD REFERENCE TEXTS MAY BE CONSULTED FOR THE FORMULAS FOR THE TRUE VARIANCES, IN THOSE CASES IN WHICH THEY ARE NOT PRESENTED HERE.
SOME DISCUSSION OF DETERMINING SAMPLE SIZES WAS PRESENTED EARLIER, IN THE CASE OF SIMPLE RANDOM SAMPLING. DETERMING SAMPLE SIZES FOR OTHER SAMPLE DESIGNS IS ADDRESSED IN DAY TWO OF THE COURSE.
THE MAJOR PROBLEM IN DETERMINING SAMPLE SIZES IN COMPLEX SURVEYS BY SETTING THE DESIRED NUMERICAL VALUE OF AN ERROR BOUND EQUAL TO THE THEORETICAL (FORMULA) VALUE IS THAT THE VARIANCES INVOLVED IN THE FORMULA ARE USUALLY NOT KNOWN (PRIOR TO CONDUCTING THE SURVEY), EVEN APPROXIMATELY. FOR THIS REASON, A DIFFEREENT APPROACH IS USED TO DETERMINE SAMPLE SIZES FOR COMPLEX SURVEYS. IT IS BASED ON A FUNCTION CALLED THE “DESIGN EFFECT,” OR KISH’S “DEFF.” THIS APPROACH IS DISCUSSED IN DAY TWO OF THE COURSE.
THE FORMULAS THAT ARE PRESENTED IN THE FOLLOWING ARE USED TO ANALYZE THE DATA, BUT THEY ARE NOT VERY USEFUL FOR ESTIMATION OF SAMPLE SIZES, BECAUSE THE VALUES OF THE PARAMETERS INVOLVED ARE USUALLY NOT KNOWN UNTIL AFTER THE SURVEY HAS BEEN CONDUCTED.
THE FORMULAS THAT ARE PRESENTED IN THIS COURSE ARE USEFUL FOR CALCULATING ESTIMATES IN THE CASE OF HIGHLY STRUCTURED SURVEY DESIGNS. IN MANY LARGE-SCALE SURVEYS, IT IS NECESSARY TO DEPART FROM HIGHLY STRUCTURED DESIGNS, AND THE FORMULAS DO NOT APPLY. IN SUCH CASES, NUMERICAL METHODS (BASED ON SIMULATION, OR “RESAMPLING”) ARE AVAILABLE TO DO THE ESTIMATION. THESE ARE MENTIONED IN THIS COURSE, BUT NOT DESCRIBED IN DETAIL.
RATIO ESTIMATORS IN SIMPLE RANDOM SAMPLING
SUMMARY OF RESULTS
ESTIMATOR OF THE POPULATION RATIO, R:
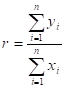
ESTIMATED VARIANCE OF r:
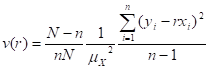
BOUND ON THE ERROR OF ESTIMATION OF r:
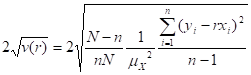
IF THE POPULATION MEAN FOR X, μX, IS
UNKNOWN, USE THE SAMPLE ESTIMATE, ![]() , TO
APPROXIMATE
, TO
APPROXIMATE ![]() .
.
RATIO ESTIMATOR OF THE POPULATION TOTAL:
![]()
ESTIMATED VARIANCE OF ![]() :
:
![]() .
.
NOTE THAT IT IS NECESSARY TO KNOW ![]() , THE
POPULATION TOTAL FOR X, IN ORDER TO ESTIMATE
, THE
POPULATION TOTAL FOR X, IN ORDER TO ESTIMATE ![]() BY THE
RATIO ESTIMATION METHOD.
BY THE
RATIO ESTIMATION METHOD.
AS USUAL, AN APPROXIMATE 95% CONFIDENCE INTERVAL FOR A POPULATION PARAMETER IS GIVEN BY:
PARAMETER ESTIMATE PLUS/MINUS 2 (ESTIMATED STANDARD ERROR OF THE PARAMETER ESTIMATE),
WHERE THE ESTIMATED STANDARD ERROR OF THE PARAMETER ESTIMATE IS THE SQUARE ROOT OF ITS ESTIMATED VARIANCE. IN THE PRECEDING CASE:
![]()
RATIO ESTIMATOR OF THE POPULATION MEAN:
![]()
ESTIMATED VARIANCE OF ![]() :
:
![]() .
.
NOTE THAT IT IS NECESSARY TO KNOW ![]() , THE
POPULATION MEAN FOR X, IN ORDER TO ESTIMATE
, THE
POPULATION MEAN FOR X, IN ORDER TO ESTIMATE ![]() BY THE
RATIO ESTIMATION METHOD.
BY THE
RATIO ESTIMATION METHOD.
RATIO ESTIMATORS IN STRATIFIED RANDOM SAMPLING
TWO APPROACHES:
- SEPARATE RATIO ESTIMATE. CONSTRUCT A SEPARATE RATIO ESTIMATE FOR EACH STRATUM, AND THEN FORM A WEIGHTED AVERAGE OF THESE SEPARATE ESTIMATES AS A SINGLE ESTIMATE OF THE POPULATION RATIO.
- COMBINED RATIO ESTIMATE. ESTIMATE THE MEANS FOR Y AND X USING THE FORMULA FOR STRATIFIED RANDOM SAMPLING, AND THEN USE THE RATIO OF THESE OVERALL MEANS AS A RATIO ESTIMATOR.
WHICH METHOD IS PREFERRED DEPENDS ON THE NATURE OF THE POPULATION AND THE DESIGN. IF THE RATIO VARIES FROM STRATUM TO STRATUM, THE SEPARATE ESTIMATE IS USUALLY BETTER (MORE PRECISE). IF THE SAMPLE SIZE IS SMALL IN EACH STRATUM, THE COMBINED RATIO ESTIMATE IS USUALLY BETTER.
THE FORMULAS FOR RATIO ESTIMATORS IN STRATIFIED RANDOM SAMPLING ARE SOMEWHAT COMPLICATED. REFER TO COCHRAN, SAMPLING TECHNIQUES FOR THE FORMULAS. THERE ARE TECHNIQUES AVAILABLE TO REDUCE OR REMOVE THE BIAS, AND TO IMPROVE THE VARIANCE OF THE ESTIMATE.
PRODUCT ESTIMATORS:
IF X AND Y TAKE ONLY POSITIVE VALUES AND THE CORRELATION IS NEGATIVE, THEN A RATIO ESTIMATE IS NOT APPROPRIATE, BUT A SIMILAR ESTIMATE, CALLED A PRODUCT ESTIMATOR, IS INDICATED:
![]() ,
,
(OR, IN COCHRAN’S NOTATION:
![]() ).
).
REGRESSION ESTIMATORS IN SIMPLE RANDOM SAMPLING
VARIABLE OF PRIMARY INTEREST (“RESPONSE” VARIABLE): Y
SUPPOSE THAT THERE IS ANOTHER (“AUXILIARY”) VARIATE, X,
CORRELATED WITH Y, AND KNOWN FOR EACH UNIT OF THE SAMPLE, AND FOR WHICH
WE KNOW THE POPULATION TOTAL, ![]() .
.
SUPPOSE FURTHER THAT THE RELATIONSHIP BETWEEN THE RESPONSE VARIABLE AND THE AUXILIARY VARIABLE IS LINEAR, BUT NOT NECESSARILY THROUGH THE ORIGIN, AS WAS ASSUMED IN THE CASE OF RATIO ESTIMATION:
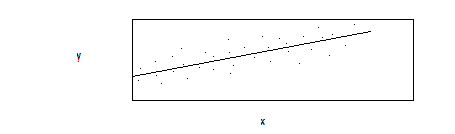
THEN USE OF A LINEAR REGRESSION ESTIMATOR IS APPROPRIATE.
FOR EXAMPLE, MAY KNOW LAST YEAR’S SCHOOL BUDGET FOR EACH SCHOOL IN THE COUNTRY (FROM AN ANNUAL SCHOOL CENSUS), AND WANT TO OBTAIN A PRELIMINARY ESTIMATE THIS YEAR’S BUDGET FROM A SAMPLE OF SCHOOLS.
(LINEAR) REGRESSION ESTIMATOR OF A POPULATION MEAN, ![]() :
:
![]()
WHERE
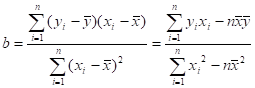
ESTIMATED VARIANCE OF ![]() :
:
![]()
BOUND ON THE ERROR OF ESTIMATION: 2![]() .
.
FOR AN ESTIMATE OF THE POPULATION TOTAL (FOR Y), USE ![]()
7.4 Cluster Sampling
CLUSTER SAMPLING
(SINGLE-STAGE CLUSTER SAMPLING)
A CLUSTER SAMPLE IS A SIMPLE RANDOM SAMPLE IN WHICH EACH SAMPLING UNIT IS A COLLECTION, OR CLUSTER, OF ELEMENTS. IN THIS CASE THE SAMPLING UNITS ARE THE CLUSTERS, AND THE ELEMENTS WITHIN THE UNITS ARE CALLED SUBUNITS.
CLUSTER SAMPLING IS FAR MORE COST-EFFECTIVE THAN SIMPLE RANDOM SAMPLING OR STRATIFIED SAMPLING, IF
- THE COST OF OBTAINING A FRAME THAT LISTS ALL OF THE POPULATION ELEMENTS IS HIGH; OR
- THE COST OF OBTAINING OBSERVATIONS INCREASES SUBSTANTIALLY AS THE DISTANCE SEPARATING THE SAMPLE ELEMENTS INCREASES.
EXAMPLES:
IN MANY COUNTRIES THERE ARE NO COMPLETE, UP-TO-DATE LISTS OF HOUSEHOLDS OR FARMS, AND THE COST OF CONSTRUCTING A FRAME OF ALL UNITS OF THE POPULATION WOULD BE PROHBITIVE. IT IS MUCH CHEAPER TO DIVIDE THE COUNTRY INTO GEOGRAPHIC AREAS (I.E., CONSTRUCT AN AREA FRAME), SELECT A RANDOM SAMPLE OF GEOGRAPHIC AREAS, AND OBSERVE ALL OF THE ELEMENTS (HOUSEHOLDS, FARMS) WITHIN EACH SELECTED AREA.
SUPPOSE THAT IN A CITY, CITY BLOCKS CONTAIN AN AVERAGE OF 20 HOUSEHOLDS EACH. INTERVIEWING ALL HOUSEHOLDS IN A SAMPLE OF 50 BLOCKS WILL COST SUBSTANTIALLY LESS THAN INTERVIEWING A SIMPLE RANDOM SAMPLE OF 1,000 HOUSEHOLDS. ALSO, A FRAME OF CITY BLOCKS MAY BE READILY AVAILABLE, WHEREAS A FRAME OF HOUSEHOLDS MAY NOT.
OTHER EXAMPLES:
- SELECT A SAMPLE OF STUDENTS OR TEACHERS BY MEANS OF A CLUSTER SAMPLE OF SCHOOLS
- SELECT A SAMPLE OF PATIENTS OR DOCTORS BY SELECTING A SAMPLE OF HOSPITALS OR NURSING HOMES
- SELECT A SAMPLE OF PRODUCTION UNITS BY SELECTING A CLUSTER SAMPLE OF BOXES OF UNITS COMING OFF A PRODUCTION LINE
IN CLUSTER SAMPLING, IT IS DESIRED THAT CLUSTERS BE INTERNALLY HETEROGENEOUS (WITH RESPECT TO THE CHARACTERISTICS BEING MEASURED). IF ALL OF THE ELEMENTS WITHIN A CLUSTER ARE VERY SIMILAR THEN RELATIVELY LITTLE INFORMATION IS PROVIDED COMPARED TO A SIMPLE RANDOM SAMPLE OF THE SAME SIZE. THIS IS THE OPPOSITE OF STRATIFIED SAMPLING, WHERE IT IS DESIRED TO HAVE THE STRATA AS INTERNALLY HOMOGENEOUS AS POSSIBLE.
CLUSTER SAMPLING
NOTATION AND ESTIMATION FORMULAS
NOTATION (WE DROP THE SUBSCRIPT Y FROM THE POPULATION PARAMETERS, SINCE Y IS THE ONLY RANDOM VARIABLE OF CONCERN HERE:
![]() = NUMBER
OF CLUSTERS IN THE POPULATION
= NUMBER
OF CLUSTERS IN THE POPULATION
![]() = NUMBER
OF CLUSTERS SELECTED, USING SIMPLE RANDOM SAMPLING
= NUMBER
OF CLUSTERS SELECTED, USING SIMPLE RANDOM SAMPLING
![]() = NUMBER
OF ELEMENTS IN THE i-th CLUSTER
= NUMBER
OF ELEMENTS IN THE i-th CLUSTER
![]() = AVERAGE
CLUSTER SIZE FOR THE SAMPLE
= AVERAGE
CLUSTER SIZE FOR THE SAMPLE
![]() = NUMBER
OF ELEMENTS IN THE POPULATION
= NUMBER
OF ELEMENTS IN THE POPULATION
![]() = AVERAGE
CLUSTER SIZE FOR THE POPULATION
= AVERAGE
CLUSTER SIZE FOR THE POPULATION
![]() = TOTAL
OF THE VALUES FOR ALL OBSERVATIONS IN THE i-th CLUSTER
= TOTAL
OF THE VALUES FOR ALL OBSERVATIONS IN THE i-th CLUSTER
ESTIMATION FORMULAS:
NOTE: THERE ARE ALTERNATIVE ESTIMATORS FOR THE VARIANCE IN CLUSTER SAMPLING, AND SOME OF THEM ARE COMPLICATED (AND INVOLVE ADVANCED STATISTICAL TECHNIQUES SUCH AS ANALYSIS OF VARIANCE). THE FORMULAS PRESENTED HERE FOLLOW SCHAEFFER, AND ARE THE LEAST COMPLICATED. THEY ARE BIASED, BUT THE BIAS IS LOW FOR LARGE n AND DISAPPEARS IF THE CLUSTER SIZES (mi) ARE ALL EQUAL.
ESTIMATOR OF THE POPULATION MEAN, μ:
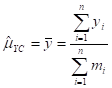
ESTIMATED VARIANCE OF ![]() :
:
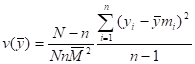
BOUND ON THE ERROR OF ESTIMATION: ![]()
IF ![]() IS
UNKNOWN, REPLACE IT BY THE ESTIMATE
IS
UNKNOWN, REPLACE IT BY THE ESTIMATE ![]() .
.
ESTIMATOR OF THE POPULATION TOTAL, ![]() , WHEN M
(THE TOTAL NUMBER OF ELEMENTS IN THE POPULATION) IS KNOWN. SINCE
, WHEN M
(THE TOTAL NUMBER OF ELEMENTS IN THE POPULATION) IS KNOWN. SINCE ![]() ,
,
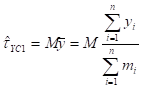
ESTIMATED VARIANCE OF ![]() :
:
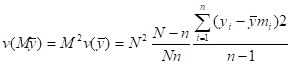
BOUND ON THE ERROR OF ESTIMATION: ![]()
IN ORDER TO USE THE ESTIMATOR ![]() TO
ESTIMATE THE POPULATION TOTAL, IT IS, OF COURSE, NECESSARY TO KNOW THE VALUE OF
M (THE TOTAL NUMBER OF ELEMENTS IN THE POPULATION). IN SITUATIONS IN
WHICH CLUSTER SAMPLING IS APPROPRIATE, M MAY NOT BE KNOWN.
TO
ESTIMATE THE POPULATION TOTAL, IT IS, OF COURSE, NECESSARY TO KNOW THE VALUE OF
M (THE TOTAL NUMBER OF ELEMENTS IN THE POPULATION). IN SITUATIONS IN
WHICH CLUSTER SAMPLING IS APPROPRIATE, M MAY NOT BE KNOWN.
AN ESTIMATOR OF THE POPULATION TOTAL, ![]() , THAT
DOES NOT REQUIRE KNOWLEDGE OF M IS GIVEN BELOW.
, THAT
DOES NOT REQUIRE KNOWLEDGE OF M IS GIVEN BELOW.
DEFINE
![]() = AVERAGE
OF THE CLUSTER TOTALS FOR THE n SAMPLE CLUSTERS
= AVERAGE
OF THE CLUSTER TOTALS FOR THE n SAMPLE CLUSTERS
THEN
![]()
ESTIMATED VARIANCE OF ![]() :
:
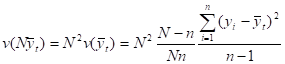
BOUND ON THE ERROR OF ESTIMATION: ![]()
CLUSTER SAMPLING MAY BE COMBINED WITH STRATIFIED SAMPLING, WHERE A CLUSTER SAMPLE IS SELECTED FROM EACH STRATUM. THE ESTIMATION FORMULAS ARE SOMEWHAT COMPLICATED, AND THE STUDENT IS REFERRED TO A REFERENCE TEXT ON SAMPLE SURVEY, SUCH AS COCHRAN, SAMPLING TECHNIQUES.
7.5 Systematic Sampling
SYSTEMATIC SAMPLING
NUMBER THE N UNITS OF THE FRAME (POPULATION) FROM 1 TO N IN SOME ORDER (E.G., AN EXISTING LIST, OR A CARD INDEX).
TO SELECT A SAMPLE OF n UNITS, TAKE A UNIT AT RANDOM FROM THE FIRST k UNITS AND EVERY k-th UNIT THEREAFTER, WHERE k = N/n. THIS TYPE OF SYSTEMATIC SAMPLE IS CALLED AN “EVERY k-th” OR “ONE-IN-k” SYSTEMATIC SAMPLE.
ADVANTAGES OF SYSTEMATIC SAMPLING:
- IT IS EASIER TO PERFORM, AND HENCE LESS PRONE TO ERRORS, THAN SIMPLE RANDOM SAMPLING.
- IT IS OFTEN MORE PRECISE THAN SIMPLE RANDOM SAMPLING (SINCE IT IN EFFECT STRATIFIES THE POPULATION INTO n STRATA – THE FIRST k UNITS, THE SECOND k UNITS, AND SO ON).
EXAMPLE: SELECT A SAMPLE OF n SHOPPERS ON A STREET CORNER. DO NOT KNOW THE TOTAL POPULATION SIZE (N), AND CANNOT LIST THE POPULATION. COULD SELECT EVERY 20-th SHOPPER UNTIL HAVE OBTAINED A SAMPLE OF SIZE n = 50.
SYSTEMATIC SAMPLING IS MORE PRECISE THAN SIMPLE RANDOM SAMPLING IF THE VARIATION AMONG UNITS IN THE SAME SYSTEMATIC SAMPLE IS GREATER THAN THE VARIATION AMONG THE WHOLE POPULATION. (IF UNITS WITHIN THE SAME SYSTEMATIC SAMPLE ARE SIMILAR TO EACH OTHER, THEN THEY DO NOT PROVIDE AS MUCH INFORMATION AS A SIMPLE RANDOM SAMPLE.)
IF THE LIST IS IN RANDOM ORDER, THEN SYSTEMATIC SAMPLING PRODUCES THE SAME RESULTS AS SIMPLE RANDOM SAMPLING (WITHOUT REPLACEMENT).
IF THE LIST IS NOT IN RANDOM ORDER, SYSTEMATIC SAMPLING MAY BE MORE PRECISE THAN SIMPLE RANDOM SAMPLING, OR LESS PRECISE. IN THIS CASE, IT IS NOT POSSIBLE TO ESTIMATE THE VARIANCE OF THE ESTIMATE FROM THE SAMPLE. IN ORDER TO BE ABLE TO ESTIMATE THE VARIANCE, IT IS NECESSARY TO TAKE TWO OR MORE SYSTEMATIC SAMPLES, I.E, SELECT TWO OR MORE STARTING POINTS AT RANDOM, AND TAKE A SYSTEMATIC SAMPLE STARTING FROM EACH STARTING POINT. IF m (E.G., 10) SYSTEMATIC SAMPLES ARE SELECTED, THEN EACH ONE IS OF SIZE n/m, WHERE n DENOTES THE TOTAL SAMPLE SIZE DESIRED (AND THE SKIP INTERVAL IS m TIMES AS LARGE AS IT WOULD HAVE BEEN HAD A SINGLE SYSTEMATIC SAMPLE BEEN SELECTED). THE PROCESS OF SELECTING SEVERAL SYSTEMATIC SAMPLES (FROM RANDOMLY SELECTED STARTING POINTS) IS CALLED “REPEATED SYSTEMATIC SAMPLING”.
THE PRECISION OF A SYSTEMATIC SAMPLE DEPENDS ON HOW THE POPULATION IS ORDERED. IF THE UNITS OF THE POPULATION ARE ORDERED, THEN SYSTEMATIC SAMPLING IS MORE PRECISE THAN SIMPLE RANDOM SAMPLING. IF NEARBY UNITS ARE SIMILAR (HIGHLY CORRELATED), THEN SYSTEMATIC SAMPLING IS USUALLY MORE PRECISE THAN SIMPLE RANDOM SAMPLING. IF SOME SORT OF PERIODIC VARIATION IS PRESENT IN THE POPULATION, SYSTEMATIC SAMPLING CAN PRODUCE VERY POOR RESULTS IF ONLY A SINGLE SYSTEMATIC SAMPLE IS SELECTED.
SCHEMATIC REPRESENTATION OF SYSTEMATIC SAMPLING
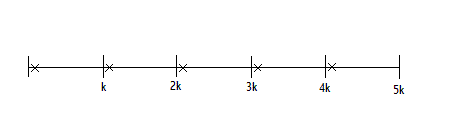
EXAMPLE 1: SYSTEMATIC SAMPLING IN A POPULATION WITH A LINEAR TREND
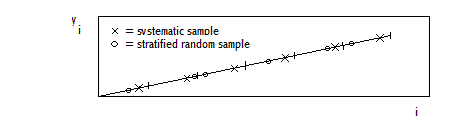
EXAMPLE 2: SYSTEMATIC SAMPLING IN A POPULATION WITH PERIODIC VARIATION

SYSTEMATIC SAMPLING IS EQUIVALENT TO STRATIFIED SAMPLING IN THE CASE IN WHICH A SINGLE ITEM IS SELECTED FROM EACH STRATUM (OR m ITEMS ARE SELECTED FROM EACH STRATUM, IF m SYSTEMATIC SAMPLES ARE SELECTED).
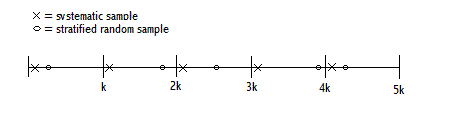
SYSTEMATIC SAMPLING IS EQUIVALENT TO CLUSTER SAMPLING IN THE CASE IN WHICH A SINGLE CLUSTER IS SELECTED (OR m CLUSTERS ARE SELECTED, IF m SYSTEMATIC SAMPLES ARE SELECTED).
Sample Number
1 2 … i … k
y1 y2 yi yk
yk+1 yk+2 yk+i y2k
…
y(n-1)k+1 y(n-1)k+2 … y(n-1)k+i … ynk
ESTIMATION FORMULAS FOR SYSTEMATIC SAMPLING, IN THE CASE OF A RANDOMLY ORDERED LIST: THE SAME AS FOR SIMPLE RANDOM SAMPLING.
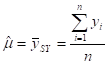
ESTIMATED VARIANCE OF ![]() :
:
![]()
BOUND ON THE ERROR OF ESTIMATION: ![]()
IF N IS UNKNOWN, REPLACE THE fpc, (N-n)/N BY 1.
ESTIMATION OF THE POPULATION TOTAL WHEN N (THE POPULATION SIZE) IS KNOWN (WHICH IS OFTEN NOT THE CASE IN SYSTEMATIC SAMPLING):
![]()
ESTIMATED VARIANCE OF ![]() :
:
![]()
BOUND ON THE ERROR OF ESTIMATION: ![]()
ESTIMATION FORMULAS FOR REPEATED SYSTEMATIC SAMPLING
n = TOTAL SAMPLE SIZE
m = NUMBER OF SYSTEMATIC SAMPLES, EACH OF SIZE n/m (n IS ASSUMED TO BE AN INTEGRAL MULTIPLE OF m)
k’ = SKIP INTERVAL FOR EACH SYSTEMATIC SAMPLE = mN/n
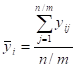 = SAMPLE
MEAN OF THE i-th SYSTEMATIC SAMPLE
= SAMPLE
MEAN OF THE i-th SYSTEMATIC SAMPLE
ESTIMATOR OF THE POPULATION MEAN μ USING m ONE-IN-k’ SYSTEMATIC SAMPLES:
![]()
ESTIMATED VARIANCE OF ![]() :
:
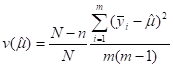
BOUND ON THE ERROR OF ESTIMATION: ![]() .
.
ESTIMATOR OF THE POPULATION TOTAL, ![]() , USING m
ONE-IN-k’ SYSTEMATIC SAMPLES:
, USING m
ONE-IN-k’ SYSTEMATIC SAMPLES:
![]()
ESTIMATED VARIANCE OF ![]() :
:
![]()
BOUND ON THE ERROR OF ESTIMATION: ![]()
7.6 Multistage Sampling
TWO-STAGE CLUSTER SAMPLING (SUBSAMPLING); MULTISTAGE SAMPLING)
A TWO-STAGE CLUSTER SAMPLE IS A SAMPLE OBTAINED BY SELECTING A SAMPLE OF CLUSTERS AND THEN SELECTING A SAMPLE OF ELEMENTS FROM EACH SAMPLED CLUSTER. SAMPLING MAY BE EXTENDED TO MORE THAN TWO STAGES, IN WHICH CASE IT IS CALLED MULTISTAGE SAMPLING.
THE CLUSTERS ARE CALLED THE PRIMARY UNITS AND THE ELEMENTS SELECTED FROM CLUSTERS ARE CALLED SECONDARY UNITS.
THE MOTIVATION FOR USING TWO-STAGE CLUSTER SAMPLING IS THAT THE UNITS WITHIN A CLUSTER MAY BE SIMILAR, SO THAT IT IS INEFFICIENT TO OBSERVE ALL OF THEM.
CLUSTERS ARE USUALLY FORMED FROM UNITS THAT ARE GEOGRAPHICALLY PROXIMATE OR EASY TO ADMINISTER.
THE SURVEY DESIGN OBJECTIVE IN TWO-STAGE CLUSTER SAMPLING IS TO BALANCE THE NUMBER OF FIRST-STAGE AND SECOND-STAGE UNITS TO ACHIEVE MAXIMUM PRECISION FOR A FIXED COST. THIS PROBLEM WILL BE ADDRESSED IN DAY 2.
NOTATION:
μ = POPULATION MEAN
![]() =
POPULATION TOTAL
=
POPULATION TOTAL
![]() = NUMBER
OF CLUSTERS IN THE POPULATION
= NUMBER
OF CLUSTERS IN THE POPULATION
![]() = NUMBER
OF CLUSTERS SELECTED, USING SIMPLE RANDOM SAMPLING
= NUMBER
OF CLUSTERS SELECTED, USING SIMPLE RANDOM SAMPLING
Mi = NUMBER OF ELEMENTS IN THE i-th CLUSTER
![]() = NUMBER
OF ELEMENTS SELECTED IN A SIMPLE RANDOM SAMPLE FROM THE i-th CLUSTER
= NUMBER
OF ELEMENTS SELECTED IN A SIMPLE RANDOM SAMPLE FROM THE i-th CLUSTER
![]() = NUMBER
OF ELEMENTS IN THE POPULATION
= NUMBER
OF ELEMENTS IN THE POPULATION
![]() = AVERAGE
CLUSTER SIZE FOR THE POPULATION
= AVERAGE
CLUSTER SIZE FOR THE POPULATION
![]() = VALUE
OF THE j-th SAMPLE ELEMENT FROM THE i-th SAMPLE CLUSTER
= VALUE
OF THE j-th SAMPLE ELEMENT FROM THE i-th SAMPLE CLUSTER
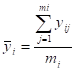
TWO-STAGE CLUSTER SAMPLING: ESTIMATION FORMULAS
ESTIMATION FORMULAS:
UNBIASED ESTIMATOR OF THE POPULATION MEAN, μ:
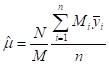
ESTIMATED VARIANCE OF ![]() :
:
![]()
WHERE
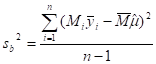
AND
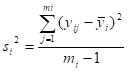
BOUND ON THE ERROR OF ESTIMATION: ![]()
ESTIMATION OF THE POPULATION TOTAL, ![]() :
:
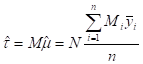
ESTIMATED VARIANCE OF ![]() :
:
![]()
BOUND ON THE ERROR OF ESTIMATION: ![]()
THE ESTIMATOR ![]() GIVEN
ABOVE REQUIRES A KNOWLEDGE OF M, THE TOTAL NUMBER OF ELEMENTS IN THE
POPULATION. IN CLUSTER SAMPLING, THIS IS OFTEN UNKNOWN. IN THIS CASE, IT IS
ESTIMATED AS THE AVERAGE CLUSTER SIZE MULTIPLIED BY THE NUMBER OF CLUSTERS IN
THE POPULATION, N:
GIVEN
ABOVE REQUIRES A KNOWLEDGE OF M, THE TOTAL NUMBER OF ELEMENTS IN THE
POPULATION. IN CLUSTER SAMPLING, THIS IS OFTEN UNKNOWN. IN THIS CASE, IT IS
ESTIMATED AS THE AVERAGE CLUSTER SIZE MULTIPLIED BY THE NUMBER OF CLUSTERS IN
THE POPULATION, N:
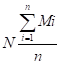
IF WE REPLACE M IN THE FORMULA FOR ![]() , THEN WE
OBTAIN A RATIO ESTIMATOR, SINCE BOTH THE NUMERATOR AND DENOMINATOR ARE RANDOM
VARIABLES. THE ESTIMATION FORMULAS FOR RATIO ESTIMATORS THEN APPLY.
, THEN WE
OBTAIN A RATIO ESTIMATOR, SINCE BOTH THE NUMERATOR AND DENOMINATOR ARE RANDOM
VARIABLES. THE ESTIMATION FORMULAS FOR RATIO ESTIMATORS THEN APPLY.
RATIO ESTIMATOR OF THE POPULATION MEAN, μ:
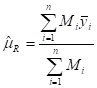
ESTIMATED VARIANCE OF ![]() :
:
![]()
WHERE
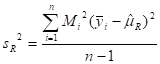
AND
BOUND ON THE ERROR OF ESTIMATION: ![]()
THE ESTIMATOR ![]() IS
BIASED, BUT THE BIAS IS LOW FOR LARGE n.
IS
BIASED, BUT THE BIAS IS LOW FOR LARGE n.
7.7 Double Sampling
DOUBLE SAMPLING
(TWO-PHASE SAMPLING)
SURVEY DESIGNS CAN BE SUBSTANTIALLY IMPROVED (REDUCED SAMPLE SIZE, REDUCED COST, INCREASED PRECISION) WITH KNOWLEDGE OF:
AN AUXILIARY VARIATE
VARIANCES (IN THE POPULATION, WITHIN AND BETWEEN STRATA, WITHIN AND BETWEEN CLUSTERS)
SUCH DATA MAY BE COLLECTED IN A PRELIMINARY SAMPLE. SUCH A PROCEDURE IS CALLED DOUBLE SAMPLING, OR TWO-PHASE SAMPLING.
EXAMPLES:
- TO ENABLE STRATIFICATION. WOULD LIKE TO STRATIFY ON AGE AND SEX, BUT DO NOT HAVE AGE AND SEX DATA. IT MAY BE FEASIBLE TO CONDUCT A LARGE PRELIMINARY SURVEY (E.G., USING SYSTEMATIC SAMPLING), RECORD AGE AND SEX FOR EACH SAMPLED PERSON, AND CONDUCT A SECOND SURVEY, STRATIFIED BY AGE AND SEX, FOR INTERVIEW.
- TO ENABLE ANALYTICAL COMPARISONS. WOULD LIKE TO MAKE COMPARISONS BETWEEN SUBGROUPS OF THE POPULATION (E.G., MALE VS. FEMALE, WHITE VS. BLACK, EMPLOYED VS. UNEMPLOYED).
- TO ENABLE RATIO OF REGRESSION ESTIMATION. CONDUCT A LARGE SURVEY TO RECORD Y, AND A MUCH SMALLER SURVEY TO RECORD ONE OR MORE VARIATES, X1, X2,… RELATED TO IT.
- REPEATED SAMPLING OF THE SAME POPULATION (LONGITUDINAL, OR PANEL, SURVEYS). ESTIMATION OBJECTIVES:
- ESTIMATE CHANGE IN MEAN FROM ONE TIME TO ANOTHER (BEST TO RETAIN SAME SAMPLE FOR ALL SAMPLING OCCASIONS).
- ESTIMATE THE MEAN OVER ALL TIME (BEST TO DRAW A NEW SAMPLE ON EACH OCCASION)
- ESTIMATE THE MEAN FOR THE MOST RECENT TIME (SAME PRECISION FROM KEEPING THE SAME SAMPLE FOR ALL OCCASIONS OR BY CHANGING IT ON EVERY OCCASION. REPLACEMENT OF PART OF THE SAMPLE ON EACH OCCASION MAY BE A BETTER ALTERNATIVE).
OPTIMAL ALLOCATION (IN CASE ONE, TO ENABLE STRATIFICATION): CHOOSE THE PRELIMINARY-SURVEY SAMPLE SIZE AND THE SECOND-SURVEY SAMPLE SIZE TO MINIMIZE THE VARIANCE OF THE STRATIFIED ESTIMATE, SUBJECT TO SPECIFIED TOTAL COST.
FORMULAS WILL NOT BE PRESENTED FOR DOUBLE SAMPLING. CONSULT COCHRAN, SAMPLING TECHNIQUES, FOR DISCUSSION AND FORMULAS.
DAY 2: HOW TO DESIGN SURVEYS AND ANALYZE SURVEY DATA
PART ONE: HOW TO DESIGN DESCRIPTIVE SURVEYS
OVERVIEW OF SECOND DAY’S COURSE CONTENT
REVIEW OF FIRST DAY’S TOPICS
THE ELEMENTS OF SURVEY DESIGN
DISTINCTION BETWEEN DESCRIPTIVE AND ANALYTICAL SURVEYS
GENERAL PROCEDURE FOR DESIGNING A DESCRIPTIVE SURVEY
WHEN AND HOW TO USE SIMPLE RANDOM SAMPLING
WHEN AND HOW TO USE STRATIFICATION
WHEN AND HOW TO USE A CLUSTERED DESIGN
WHEN AND HOW TO USE SYSTEMATIC SAMPLING
WHEN AND HOW TO USE A MULTISTAGE DESIGN
WHEN AND HOW TO USE DOUBLE SAMPLING
HOW TO RESOLVE CONFLICTING / MULTIPLE SURVEY DESIGN OBJECTIVES
PART TWO: HOW TO DESIGN ANALYTICAL SURVEYS
SURVEY OF REGRESSION ANALYSIS
GENERAL PROCEDURE FOR DESIGNING AN ANALYTICAL SURVEY
HOW TO USE MULTIPLE STRATIFICATION FOR AN ANALYTICAL DESIGN
HOW TO USE CONTROLLED SELECTION FOR AN ANALYTICAL DESIGN
PART THREE: HOW TO ANALYZE SURVEY DATA
STANDARD ESTIMATION PROCEDURES FOR DESCRIPTIVE SURVEYS
STANDARD ESTIMATION PROCEDURES FOR ANALYTICAL SURVEYS
COMPUTER PROGRAMS FOR ANALYSIS OF SURVEY DATA
OUTLINE OF TOPICS FOR THIRD DAY
8. Day 2: How to Design Surveys and Analyze Survey Data
SAMPLE SURVEY DESIGN AND ANALYSIS:
A COMPREHENSIVE THREE-DAY COURSE
LECTURE NOTES
DAY TWO: HOW TO DESIGN SURVEYS AND ANALYZE SURVEY DATA
Joseph George Caldwell, PhD (Statistics)
1432 N Camino Mateo, Tucson, AZ 85745-3311 USA
Tel. (001)(520)222-3446, E-mail jcaldwell9@yahoo.com
Updated November 9, 2016
Copyright © 1980 - 2016 Joseph George Caldwell. All rights reserved.
DAY 2: HOW TO DESIGN SURVEYS AND ANALYZE SURVEY DATA
PART ONE: HOW TO DESIGN DESCRIPTIVE SURVEYS
DAY TWO PRELIMINARIES: OVERVIEW OF SECOND DAY'S COURSE CONTENT; REVIEW OF FIRST DAY'S TOPICS; THE ELEMENTS OF SURVEY DESIGN; DISTINCTIONS BETWEEN DESCRIPTIVE AND ANALYTICAL
SURVEYS
GENERAL PROCEDURE FOR DESIGNING A DESCRIPTIVE SAMPLE SURVEY
WHEN AND HOW TO USE SIMPLE RANDOM SAMPLING
WHEN AND HOW TO USE STRATIFIED SAMPLING
WHEN AND HOW TO USE CLUSTER SAMPLING
WHEN AND HOW TO USE SYSTEMATIC SAMPLING
WHEN AND HOW TO USE MULTISTAGE SAMPLING
WHEN AND HOW TO USE DOUBLE SAMPLING
HOW TO RESOLVE CONFLICTING MULTIPLE SURVEY DESIGN OBJECTIVES
PART TWO: HOW TO DESIGN ANALYTICAL SURVEYS
REVIEW OF REGRESSION ANALYSIS
GENERAL PROCEDURE FOR DESIGNING AN ANALYTICAL SURVEY
ILLUSTRATION OF METHODS FOR THE DESIGN OF ANALYTICAL SURVEYS
PART THREE: HOW TO ANALYZE SURVEY DATA
STANDARD ESTIMATION PROCEDURES FOR DESCRIPTIVE SURVEYS
STANDARD ESTIMATION PROCEDURES FOR ANALYTICAL SURVEYS
COMPUTER PROGRAMS FOR ANALYSIS OF SURVEY DATA: OUTLINE OF TOPICS FOR THIRD DAY
PART ONE. HOW TO DESIGN DESCRIPTIVE SURVEYS
8.1 Day Two Preliminaries (Overview; Review of Day 1; Elements of Survey Design; Descriptive vs. Analytical Surveys)
REVIEW OF FIRST DAY’S TOPICS
DEFINITIONS:
SAMPLE DESIGN: SAMPLE SELECTION PROCESS; ESTIMATION PROCESS
SURVEY CONCEPTS:
ELEMENTS; INDIVIDUALS; ELEMENTARY UNITS
POPULATION: THE COLLECTION OF ELEMENTS; DEFINED BY CONTENT, UNITS, EXTENT, AND TIME
TARGET POPULATION: POPULATION OF INTEREST
SURVEY POPULATION: POPULATION SAMPLED FROM
UNIVERSE: CONCEPTUALLY INFINITE POPULATION GENERATED BY THEORETICAL MODEL OR PROCESS WHICH PRODUCES THE FINITE POPULATION
SUBCLASS: SUBPOPULATION
DOMAIN: SUBCLASS PLANNED FOR IN THE SURVEY
OBSERVATION: UNIT OBSERVED
DEFINITIONS (CONT'D):
VARIABLE: A MEASUREMENT ON AN ELEMENT (x1, x2, …, xn)
SAMPLING UNITS: GROUPS OF ITEMS SELECTED IN SAMPLING
ELEMENT SAMPLING: SAMPLE UNIT = ELEMENT
CLUSTER SAMPLING: SAMPLE UNIT = MORE THAN ONE ELEMENT
STRATUM: SUBPOPULATION
LIST: COMPILATION OF SAMPLING UNITS
OBSERVATIONAL UNIT: UNITS FROM WHICH RESPONSES ARE OBTAINED
FRAME: LIST, OR NECESSARY PORTION
PERFECT FRAME: COMPLETE, ACCURATE, UNDUPLICATED, UP-TO-DATE
DEFINITIONS (CONT'D)
BASIC STATISTICAL CONCEPTS
POPULATION
RANDOM VARIABLE
LEVEL OF MEASUREMENT (NOMINAL, ORDINAL, INTERVAL)
PERCENTILES, MOMENTS (MEAN, STANDARD DEVIATION)
PROBABILITY DISTRIBUTION
HISTOGRAM: FREQUENCY PLOT
DISTRIBUTION PARAMETERS: VARIABLES SPECIFYING A DISTRIBUTION (E.G,, MEAN AND VARIANCE FOR A NORMAL DISTRIBUTION)
SAMPLE
STATISTIC
ESTIMATE, ESTIMATOR
SAMPLING DISTRIBUTION
DEFINITIONS (CONT'D)
PRECISION (RELIABILITY); BIAS (VALIDITY); ACCURACY
STANDARD ERROR (PRECISION)
COEFFICIENT OF VARIATION
MEAN SQUARE ERROR (ACCURACY) = VARIANCE + (BIAS)2
CONFIDENCE INTERVAL
NORMAL DISTRIBUTION; BINOMIAL DISTRIBUTION CORRELATION; VARIANCE
ALTERNATIVE ESTIMATORS (SIMPLE, RATIO, REGRESSION)
LAW OF LARGE NUMBERS; CENTRAL LIMIT THEOREM
SAMPLING DISTRIBUTIONS; BIAS, STANDARD ERROR OF THE ESTIMATE
FORMULAS FOR COMPUTING PARAMETER ESTIMATES AND PRECISION
ESTIMATES
REPLACEMENT AND NONREPLACEMENT SAMPLING (BINOMIAL,
HYPERGEOMETRIC)
FINITE POPULATION CORRECTION (FPC) FACTOR
REVIEW OF FIRST DAY'S TOPICS (CONT'D)
TAXONOMY OF SURVEY SELECTION PROCEDURES
NONPROBABILITY PROCEDURES:
HAPHAZARD
PURPOSIVE, OR JUDGMENT ("REPRESENTATIVE" SAMPLING)
QUOTA SAMPLING (PURPOSIVE)
CAPTURE-RECAPTURE
PROBABILITY SAMPLING (EVERY UNIT HAS A KNOWN NONZERO
PROBABILITY OF SELECTION) -- CAN USE STATISTICAL THEORY TO DEVELOP "GOOD" ESTIMATES AND ESTIMATE PRECISION ("RANDOM" SAMPLING; "REPRESENTATIVE" SAMPLING)
|
EQUAL PROBABILITIES -- AT ALL SAMPLING STAGES -- EQUAL OVERALL PROBABILITIES |
UNEQUAL PROBABILITIES -- UNINTENDED (SAMPLE FRAME OR SELECTION PROBLEMS) -- OPTIMAL ALLOCATION |
|
ELEMENT SAMPLING |
CLUSTER SAMPLING -- ONE-STAGE -- SUBSAMPLING (TWO-STAGE) |
|
UNSTRATIFIED |
STRATIFIED |
|
RANDOM SELECTION |
SYSTEMATIC SELECTION |
|
ONE-PHASE |
TWO-PHASE (DOUBLE) |
|
CROSS-SECTIONAL |
LONGITUDINAL (PANEL, TIME SERIES) |
CHARACTERISTICS OF A SAMPLE DESIGN
GOAL-ORIENTED (ADDRESSES RESEARCH OBJECTIVES)
MEASURABLE PRECISION (CAN ESTIMATE STANDARD ERRORS)
FEASIBLE TO IMPLEMENT
EFFICIENT (HIGH PRECISION /COST RATIO) -- DESIGN EFFECT; "OPTIMAL" DESIGN
PRECISION (STANDARD ERROR)
BIAS
ACCURACY (TOTAL ERROR -- SAMPLING VARIABILITY + BIAS + NONSAMPLING ERRORS)
SELECTION PROCEDURES
LIST OR FRAME
TABLE OF RANDOM NUMBERS
SYSTEMATIC SAMPLING
SAMPLING WITH OR WITHOUT REPLACEMENT
THE ELEMENTS OF SURVEY DESIGN
SPECIFY POPULATION OF INTEREST
DEFINE ESTIMATES OF INTEREST
SPECIFY PRECISION OBJECTIVES OF THE SURVEY; RESOURCE CONSTRAINTS;
POLITICAL CONSTRAINTS
SPECIFY OTHER VARIABLES OF INTEREST (EXPLANATORY VARIABLES,
STRATIFICATION VARIABLES)
DEVELOP INSTRUMENTATION (DEVELOPMENT, PRETEST, PILOT TEST,
RELIABILITY, VALIDITY)
DEVELOP SAMPLE DESIGN
DETERMINE SAMPLE SIZE AND ALLOCATION
SPECIFY SAMPLE SELECTION PROCEDURE
SPECIFY FIELD PROCEDURES
DETERMINE DATA PROCESSING PROCEDURES
DEVELOP DATA ANALYSIS PLAN
OUTLINE FINAL REPORT
DISTINCTIONS BETWEEN DESCRIPTIVE AND ANALYICAL SURVEYS
DESCRIPTIVE SURVEY
· CONDITION OR STATE OF A FINITE POPULATION AT SOME POINT IN TIME
· ESTIMATION OF MEANS AND PROPORTIONS FOR THE POPULATION AND VARIOUS SUBPOPULATIONS
· ESTIMATION OF SOME BASIC RELATIONSHIPS, THROUGH CROSSTABULATIONS (BY STRATA)
· NOTE: TEST DIFFERENCES, IF MADE AT ALL, ARE MADE UNDER INFINITE POPULATION ASSUMPTION
ANALYTICAL SURVEY
· ESTIMATION OF RELATIONSHIPS BETWEEN (DEPENDENT AND INDEPENDENT) VARIABLES, FOR A CONCEPTUALLY INFINITE POPULATION
· INFERENCES ABOUT THE PROCESS GENERATING OR ACTING ON THE
· POPULATION, NOT ABOUT THE POPULATION ITSELF
· MODEL BUILDING (MODEL IDENTIFICATION; ESTIMATION; TEST OF MODEL ADEQUACY; RESPECIFICATION); GENERAL LINEAR STATISTICAL MODEL (EXPERIMENTAL DESIGN, MULTIPLE REGRESSION ANALYSIS)
DIFFERENCES
· IN DESCRIPTIVE SURVEY, WANT LARGE SAMPLE SIZES IN SUBPOPULATIONS OF INTEREST
· IN ANALYTICAL SURVEY, WANT VARIATION AND BALANCE IN VARIABLES OF INTEREST, AND ORTHOGONALITY (LOW CORRELATION) BETWEEN VARIABLES THAT ARE NOT CAUSALLY RELATED
· FPC IS IRRELEVANT IN ANALYTICAL SURVEY (INFINITE POPULATION)
A GOOD REFERENCE THAT DISCUSSES THE DISTINCTION BETWEEN
DESCRIPTIVE AND ANALYTICAL SURVEYS (DESIGN-BASED, MODEL-BASED, MODEL-ASSISTED
INFERENCE) IS SHARON L. LOHR’S SAMPLING: DESIGN AND ANALYSIS 2ND ED., (CENGAGE
LEARNING, 2009).
8.2 General Procedure for Designing a Descriptive Sample Survey
II. GENERAL PROCEDURE FOR DESIGNING A DESCRIPTIVE SAMPLE SURVEY
(RELATE TO SLIDE "THE ELEMENTS OF SURVEY DESIGN")
1. SPECIFY POPULATION OF INTEREST
· TARGET POPULATION: CONTENT, UNITS, EXTENT, TIME
· UNITS OF ANALYSIS (E.G., STUDENTS, SCHOOLS, SCHOOL DISTRICTS)
· SURVEY POPULATION; RECOGNIZES PRACTICAL CONSTRAINTS
o INACCESSABILITY OR LACK OF DATA; AVAILABLITY OF FRAME
o EXPENSE (OF TRAVELLING, MEASURING)
o LEGAL, POLITICAL CONSTRAINTS
o TOTAL COST CONSTRAINTS
· WORK WITH PROGRAMMATIC PEOPLE TO DETERMINE A SURVEY POPULATION THAT WILL PERMIT MEANINGFUL RESULTS (WORTH STUDYING, ADEQUATE PRECISION)
· SUMMARIZE NATURE OF POPULATION:
o FOR AVAILABLE VARIABLES RELATED TO THE STUDY, COMPUTE
§ MEANS
§ CROSSTABS
§ STRATUM VARIANCES
o SAMPLING COST INFORMATION
o CLUSTER STRUCTURE OF POPULATION (INTRACLUSTER CORRELATION COEFFICIENT)
2. DEFINE ESTIMATES OF INTEREST
· DEFINE VARIABLES OF INTEREST (E.G,, AGE, SEX, RACE, EARNINGS, STATUS, OPINION)
· DEFINE SUBPOPULATIONS OF INTEREST (E.G. WOMEN, UNEMPLOYED, COLLEGE STUDENTS, PUBLIC SCHOOLS)
· IDENTIFY SURROGATE VARIABLES (E.G„ EARNINGS VS. INCOME; BUDGET VS. EXPENDITURES)
· IDENTIFY METHODS OF OBSERVATION (RECORD SCAN, INTERVIEW, MAIL QUESTIONNAIRE)
· IDENTIFY MEASURES OF INTEREST (E.G., MEAN CHANGES IN EARNINGS, RELATIVE TO A COMPARISON GROUP)
· IDENTIFY DISTRIBUTION PARAMETERS TO BE ESTIMATED (MEAN, PERCENTILES, PERCENTAGES)
3. SPECIFY OBJECTIVES AND CONSTRAINTS
· PRECISION OBJECTIVES: CONFIDENCE LIMITS ON KEY ESTIMATES, FOR KEY SUBPOPULATIONS
· RESOURCE CONSTRAINTS (TIME, FUNDS, PERSONNEL)
· POLITICAL AND LEGAL CONSTRAINTS
· DATA LIMITATIONS (FRAME, MEASUREMENT)
4. SPECIFY OTHER VARIABLES OF INTEREST
· STRATIFICATION VARIABLES
o FOR PRECISION IMPROVEMENT
o FOR COST REDUCTION
o FOR SUBPOPULATIONS OF INTEREST
· EXPLANATORY VARIABLES
o FOR CROSSTABS
o FOR IMPROVED ESTIMATES (RATIO, REGRESSION)
o FOR NONRESPONSE ANALYSIS
· SAMPLING COST DATA
· INTRASTRATUM VARIABILITY
· INTRACLUSTER CORRELATION COEFFICIENTS
5. DEVELOP INSTRUMENTATION
TYPE OF INSTRUMENT (MAIL, TELEPHONE, PERSONAL INTERVIEWS, DATA COLLECTION FORM)
INSTRUMENT DESIGN
· QUESTION CONTENT
· QUESTION ORDER (RAPPORT-BUILDING FIRST, SENSITIVE LAST)
· QUESTION WORDING (NO LEADING, BIASED, DIFFICULT-TO-UNDERSTAND, DIFFICULT TO ANSWER, AMBIGUOUS, INFLAMMATORY)
· QUESTION STRUCTURE/FORMAT (OPEN OR CLOSED; NUMBER OF
· CATEGORIES)
· QUESTIONNAIRE LENGTH
· QUESTIONNAIRE LAYOUT (SELF-CODING, SMOOTH FLOW, CLEAR SKIP PATTERNS, RESPONSE SHEETS)
· QUESTIONNAIRE INSTRUCTIONS (PROCEDURES, PROBES)
· OPPORTUNITIES FOR INTERVIEWER COMMENT ON VALIDITY OF RESPONSE
PRETEST
· LIMITED TRIAL (JUDGMENT SAMPLE) ON AS WIDE A VARIETY OF THE POPULATION AS POSSIBLE, TO CHECK FOR DATA AVAILABILITY, SMOOTHNESS OF FLOW, UNDERSTANDABILITY, LENGTH)
PILOT TEST (POSSIBLY A RANDOM SAMPLE)
· TEST OF FIELD PROCEDURES
· MORE THOROUGH TEST OF INSTRUMENT
· RELIABILITY ASSESSMENT (ITEM-ITEM, ITEM-TOTAL, SPLIT-HALF CORRELATIONS)
· VALIDITY ASSESSMENT (INDEPENDENT CHECKS)
· REORDERING (FACTOR ANALYSIS)
6. DEVELOP SAMPLE DESIGN
· SYNTHESIZE SEVERAL DESIGN ALTERNATIVES, EMPHASIZING DIFFERENT DESIGN OBJECTIVES (E.G., ESTIMATE TOTALS VS. ESTIMATE DIFFERENCES (CONTRASTS); ESTIMATE CLUSTER MEAN VS. ELEMENT MEAN)
· DESIGN ALTERNATIVES: STRATIFIED, CLUSTERED, MULTISTAGE, TWO-PHASE
· INDICATE PRECISION, COST, OPERATIONAL PROBLEMS OF EACH DESIGN (USE ESTIMATION FORMULAS)
· ACHIEVE A CONSENSUS ON THE "BEST" OVERALL DESIGN
7. DETERMINE SAMPLE SIZE AND ALLOCATION
· NUMBER OF FIRST-STAGE AND SECOND-STAGE SAMPLE UNITS
· NUMBER OF FIRST-PHASE AND SECOND-PHASE UNITS
· NUMBER OF SAMPLE UNITS PER STRATUM
· PROPORTION OF PANEL TO BE REPLACED
FOR SIMPLE DESIGN WITH FEW OBJECTIVES, USE FORMULAS FOR OPTIMAL ALLOCATION (GIVEN COST, VARIANCE, INTRACLUSTER CORRELATION COEFFICIENT)
FOR COMPLEX DESIGNS WITH MANY OBJECTIVES, USE JUDGMENT TO DEVELOP SEVERAL ALTERNATIVES, PRESENT CHARACTERISTICS OF EACH
FOR DECRIPTIVE SURVEYS, EXAMINE SAMPLE WEIGHTS (RECIPROCALS OF SELECTION PROBABILITIES -- WANT UNIFORM WEIGHTS, TO EXTENT POSSIBLE)
A MAJOR DIFFICULTY IN DETERMINING SAMPLE SIZES FOR COMPLEX SURVEYS IS THAT THE STANDARD APPROACH (OF SETTING THE DESIRED NUMERICAL VALUE OF AN ERROR BOUND EQUAL TO THE THEORETICAL (FORMULA) VALUE) INVOLVES QUANTITIES (VARIANCES) WHOSE VALUES ARE NOT KNOWN, EVEN APPROXIMATELY, PRIOR TO THE SURVEY. PRACTICAL METHODS WILL BE PRESENTED FOR DEALING WITH THIS PROBLEM.
AS MENTIONED IN DAY ONE (PAGE 58), A COMPUTER PROGRAM FOR DETERMINING SAMPLE SIZES IN SAMPLE SURVEYS (EITHER SIMPLE OR COMPLEX DESIGNS) IS POSTED AT http://www.foundationwebsite.org/SampleSize.exe (A MICROSOFT ACCESS PROGRAM). IN USING THIS PROGRAM, THE “SAMPLE SIZE” IS USUALLY TAKEN TO BE THE NUMBER OF FIRST-STAGE UNITS. THE SAMPLE SIZE FOR SECOND-STAGE UNITS IS USUALLY DETERMINED BY THE VALUE OF THE INTRA-UNIT CORRELATION COEFFICIENT (WHICH VARIES ACCORDING TO THE VARIABLE OF INTEREST). (THIS WILL BE DISCUSSED LATER.) IN MOST APPLICATIONS, LITTLE IS KNOWN IN ADVANCE OF THE SURVEY ABOUT THE VALUES OF MEANS OR VARIANCES, AND THE SAMPLE SIZE IS DETERMINED ACCORDING TO EDUCATED GUESSES ABOUT CORRELATIONS AND STANDARDIZED UNITS. TO AVOID THE NECESSITY OF SPECIFYING THE VARIANCE, THE SAMPLE SIZE MAY BE DETERMINED FOR SAMPLING FOR PROPORTIONS (IN WHICH CASE THE VARIANCE IS A FUNCTION OF THE MEAN), OR BY SPECIFYING THE SIZE OF CONFIDENCE INTERVALS OR DIFFERENCES TO BE DETECTED RELATIVE TO (IN UNITS OF) THE STANDARD DEVIATION.
8. SPECIFY SAMPLE SELECTION PROCEDURES
· WITH OR WITHOUT REPLACEMENT (FIRST AND SECOND STAGE)
· PPS (PPMS) OR NON PPS
· SYSTEMATIC SAMPLING
· SELECTION TO ENABLE VARIANCE ESTIMATION
· CONTROLLED SELECTION
9. SPECIFY FIELD PROCEDURES
· NUMBER AND SPACING OF QUESTIONNAIRE WAVES
· LETTERS OF ENDORSEMENT
· CLEARANCES
· NATURE OF INITIAL CONTACT; CALL BACKS
· INCENTIVES FOR RESPONDENTS; FOR WORKERS; AUDITS
· FIELD EDIT, RECONTACT
· TRANSMITTAL TO CENTRAL PROCESSING FACILITY
10. SPECIFY DATA PROCESSING PROCEDURES
· LOGGING, MANUAL EDIT, CODING
· KEYING, MACHINE EDIT
· DATA BASE DESIGN (AUDIT TRAIL, UPDATE FILE)
· TREATMENT OF MISSING VALUES (CODES, IMPUTED VALUES)
· HANDLING OF NONRESPONSE SUBSAMPLE
· DATA BASE DOCUMENTATION
11. DEVELOP DATA ANALYSIS PLAN
PRELIMINARY ANALYSIS
· NONRESPONSE COUNTS
· TREATMENT OF NONRESPONSE (IMPUTATION)
· FREQUENCY COUNTS, MEANS, MINIMA, MAXIMA, RANGES, STANDARD DEVIATIONS (FOR ALL VARIABLES); PEARSON CORRLATION MATRIX FOR CONTINUOUS VARIABLES
· FORM DUMMY VARIABLES FOR ALL NONORDINAL (NOMINAL) DATA, COMPUTE CRAMER CORRELATION MATRIX FOR ALL VARIABLES
DIRECTED ANALYSIS
· COMPUTE ESTIMATES OF INTEREST (MEANS, PERCENTAGES, TOTALS, SUBPOPULATION ESTIMATES)
· COMPUTE CROSSTABS OF INTEREST, WITH TESTS OF SIGNIFICANCE
· PERFORM TESTS OF HYPOTHESES
12. REPORT PREPARATION
· ESTIMATES: TABLES AND CHARTS
· COMMENTARY
· GENERALIZED VARIANCES
· CHARACTERIZATION OF NONRESPONSE
· DISCUSSION OF POTENTIAL SOURCES OF BIAS (SELECTION, MEASUREMENT, NONRESPONSE, PROCESSING, ESTIMATION PROCEDURE)
· DISCUSSION OF EXTERNAL VALIDITY
8.3 When and How to Use Simple Random Sampling
III. WHEN AND HOW TO USE SIMPLE RANDOM SAMPLING
1. NATURE OF SITUATION WHICH WARRANTS USE OF SIMPLE RANDOM SAMPLING
· ESTIMATES WANTED FOR TOTAL POPULATION OR LARGE SUBPOPULATIONS
· NO MAJOR COST DIFFERENCES IN SAMPLING VARIOUS CLASSES OF SAMPLE UNITS
· RELATIVELY HOMOGENEOUS POPULATION, OR NO AUXILIARY INFORMATION
· NO COST SAVINGS IN SAMPLING "NEARBY" UNITS OR OTHER NATURAL CLUSTERS OF THE POPULATION (I,E., CLUSTER SAMPLING WOULDN'T SAVE MONEY)
· SAMPLING IS INEXPENSIVE (E,G„ COMPUTER FILES)
· SAMPLE FRAME IS AVAILABLE FOR ENTIRE POPULATION
· LIMITED ANALYSIS CAPABILITY
METHODS FOR DETERMINING SAMPLE SIZES FOR SIMPLE RANDOM
SAMPLING WERE DISCUSSED IN DAY ONE OF THE COURSE.
2. HOW TO SELECT A SIMPLE RANDOM SAMPLE (WITH REPLACEMENT)
· REPRODUCIBLE METHODS
o TABLE OF RANDOM NUMBERS
o COMPUTER-GENERATED RANDOM NUMBERS (WITH SEED) (Nui, i=1,2,…,N)
· NONREPRODUCIBLE METHODS
o ROLLS, SPINS, SHUFFLING (WITH RESHUFFLE AFTER EACH DRAW)
o COMPUTER-GENERATED RANDOM NUMBERS (WITHOUT SEED)
· OTHER METHODS (QUESTIONABLE)
· LAST DIGITS OF SOCIAL SECURITY NUMBER
3. SAMPLING WITHOUT REPLACEMENT
· FOR SMALL POPULATIONS, WILL IMPROVE PRECISION (FPC)
· COMPUTATION OF VARIANCE IS COMPLICATED
4. HOW TO SELECT A SIMPLE RANDOM SAMPLE WITHOUT REPLACEMENT
· REPRODUCIBLE METHODS
o TABLE OF RANDOM NUMBERS
o RANDOM PERMUTATIONS
o COMPUTER-GENERATED RANDOM NUMBERS
· NONREPRODUCIBLE METHODS
o SHUFFLING, ROLLS, SPINS
· SYSTEMATIC SAMPLING OF RANDOMLY ORDERED LIST
8.4 When and How to Use Stratified Sampling
IV. WHEN AND HOW TO USE STRATIED SAMPLING
1. NATURE OF SITUATION WHICH WARRANTS USE OF STRATIFIED SAMPLING
· SUBPOPULATIONS OF INTEREST
· ADMINISTRATIVE DIFFERENCES
· COST REDUCTION
· VARIANCE REDUCTION
o DEPENDENT VARIABLE CORRELATED WITH VARIABLE OF STRATIFICATION
o STRATA ARE INTERNALLY HOMOGENEOUS
· HAVE AUXILIARY INFORMATION ON ALL OF POPULATION
2. THE USE OF A "CERTAINTY" STRATUM
· POLITICAL REASONS
· COST REASONS
· (IN TWO-STAGE SAMPLING -- DISCUSSED LATER)
· NO PROBLEM IN ASSIGNING UNIIT SELECTION PROBABILITIES BEFORE SELECTING THE SAMPLE
3. ERRORS IN CLASSIFICATION
· LEAVE THE WRONG UNITS IN THE WRONG STRATA
· SLIGHT DECREASE IN EFFICIENCY
· CORRECTING THE SAMPLE CAN LEAD TO BIAS
4. HOW TO DETERMINE THE NUMBER OF STRATA AND THE STRATUM
BOUNDARIES
· CASE 1: STRATIFICATION FOR SUBPOPULATIONS OF INTEREST
o COMPARE VARIANCE OF ESTIMATED MEAN WITH STRATIFICATION TO VARIANCE WITHOUT STRATIFICATION (DESIGN EFFECT)
o ASSESS TRADEOFF OF PRECISION OF ESTIMATES FOR TOTAL POPULATION FOR PRECISION OF ESTIMATES OF SUBPOPULATIONS
· CASE 2: STRATIFICATION FOR PRECISION IMPROVEMENT
o NUMBER OF STRATA:
§ EMPIRICAL EVIDENCE: 2-6 CATEGORIES
o STRATUM BOUNDARIES:
§ SUPPOSE X IS A KNOWN VARIABLE RELATED TO THE VARIABLE OF INTEREST Y.
![]()
![]()
![]()
![]()
0-5 .4 .63 .63
5-10 .2 .45 1.08
…
95-100 .05 .22 5.67
1.00
SET THE STRATUM BOUNDARIES TO CREATE EQUAL INTERALS ON THE ![]() .
.
5. POSTSTRATIFICATION
STRATIFICATION: STRATUM SIZES KNOWN IN ADVANCE OF SAMPLING, FIXED SAMPLE SIZE PER STRATUM
POSTSTRATIFICATION: STRATA DETERMINED AFTER SAMPLE IS
SELECTED; STRATUM SIZES KNOWN, SAMPLE SIZE PER STRATUM
IS RANDOM VARIABLE
GAINS IN PRECISION DUE TO POSTSTRATIFICATION COMPARABLE TO
THOSE FROM STRATIFICATION WITH SAME EXPECTED STRATUM
SAMPLE SIZE. SLIGHT LOSS IN PRECISION BECAUSE OF UNKNOWN
SAMPLE SIZE.
6. STRATIFICATION WITH RANDOM QUOTAS
USUAL PROCEDURE: SORT UNITS INTO STRATA, DRAW SAMPLES
EQUIVALENT PROCEDURE: SELECT SAMPLE, SORT INTO STRATA,
RESELECT UNTIL STRATUM SIZES MET
7. STRATIFICATION TO THE LIMIT
IF SEVERAL VARIABLES OF INTEREST (SUBPOPULATIONS, EXPLANATORY VARIABLES), DESIRE TO CROSS-STRATIFY
|
Public/Private |
|||||
|
Urban |
Rural |
Urban |
Rural |
||
|
School Size |
Very Small |
||||
|
Small |
|||||
|
Medium |
|||||
|
Large |
|||||
NUMBER OF CELLS MULTIPLIES QUICKLY (E.G., 5 VARIABLES OF
STRATIFICATION, EACH AT 3 LEVELS, IMPLIES 35 = 243 CELLS)
UNLESS DESIRE TO APPLY SPECIAL DESIGN PROCEDURES, NEED AT LEAST TWO UNITS PER STRATUM TO ESTIMATE VARIANCE.
IF STRATIFY TO THE LIMIT OF ONE UNIT PER STRATUM, MUST
“COLLAPSE” STRATA TO ESTIMATE VARIANCE (BIASED ESTIMATE)
8. MULTIPLE STRATIFICATION (DEEP STRATIFICATION, TWO-WAY
STRATIFICATION, CROSS-STRATIFICATION)
STRATIFY ON VARIABLES A AND B
|
B |
||||||||||||||
|
1 |
R |
|||||||||||||
|
A |
1 |
x |
3 |
|||||||||||
|
x |
||||||||||||||
|
x |
||||||||||||||
|
x |
3 |
|||||||||||||
|
x |
||||||||||||||
|
x |
||||||||||||||
|
x |
2 |
|||||||||||||
|
x |
||||||||||||||
|
x |
2 |
|||||||||||||
|
x |
||||||||||||||
|
x |
2 |
|||||||||||||
|
C |
x |
|||||||||||||
|
2 |
2 |
2 |
2 |
2 |
2 |
n=12 |
||||||||
R = NUMBER OF ROWS = 6
C = NUMBER OF COLUMNS = 5
R x C = 6 x 5 = 30
n = SAMPLE SIZE = 12
CASE 1: STRATIFICATION ALONG MARGINALS (NOT IN CELLS)
n > max(R,C)
AT LEAST 1 UNIT PER ROW
AT LEAST 1 UNIT PER COLUMN
NOT NECESSARILY 1 UNIT PER CELL
SPECIFY MARGINAL COUNTS, USE PROBABILITY SELECTION OF CELLS ...
CASE 2: CONTROLLED SELECTION: LATIN SQUARE DESIGN
n=R=C
|
Control Classes |
||||
|
1 |
2 |
3 |
||
|
Strata |
I |
Aa |
Bb |
Cc |
|
II |
Cb |
Ac |
Ba |
|
|
III |
Bc |
Ca |
Ab |
|
SIX PATTERNS OF CONTROLLED SELECTION: A, B, C, a, b,c
ASSIGN A PROBABILITY TO EACH PATTERN (E.G., 1/3), AND SELECT A PATTERN (NON-INDEPENDENT SAMPLING)
CASE 3: CONTROLLED SELECTION: GENERAL CASE
n < R, n < C
DEFINE A SERIES OF DESIRABLE PATTERNS SUCH THAT THE
COLLECTION OF PATTERNS IN TOTO "COVER" ALL CELLS.
ASSIGN PROBABILITIES TO THE PATTERNS SUCH THAT THE EXPECTED MARGINAL TOTALS ARE AS DESIRED, AND THE PROBABILITIES OF SELECTION OF THE INDIVIDUAL ELEMENTS ARE AS UNIFORM AS POSSIBLE.
SELECT A PATTERN.
MULTIPLE STRATIFICATION: USEFUL IF SAMPLE SIZE IS SMALL (E.G., SAMPLE OF CLUSTERS), OR LARGE NUMBER OF VARIABLES OF STRATIFICATION.
CASE 4: OPTIMIZATION TECHNIQUES
SPECIFY A SERIES OF CONSTRAINTS, SUCH AS CONSTRAINTS ON THE PRECISION OF VARIOUS ESTIMATES, OR ON COST, OR ON STRATUM SIZES, AND DETERMINE AN ALLOCATION OVER THE STRATA THAT MINIMIZES OR MAXIMIZES A SPECIFIED OBJECTIVE FUNCTION, SUBJECT TO THESE CONSTRAINTS.
EXAMPLE:
CONSTRAINTS:
VARIANCE OF POPULATION MEAN <= A1
VARIANCE OF STRATUM MEANS <= A2
SAMPLE ALL UNITS IN TEXAS
OBJECTIVE:
DETERMINE SAMPLE ALLOCATION THAT MINIMIZES TOTAL COST, SUBJECT TO ABOVE CONSTRAINTS
PROCEDURE:
VARIOUS OPTIMIZATION METHODS, E.G., LAGRANGE MULTIPLIERS (EXAMPLE: NEYMAN ALLOCATION TO STRATA)
9. HOW TO ALLOCATE SAMPLE SIZES TO STRATA, WHEN COSTS AND VARIANCES ARE KNOWN
COST =![]()
OPTIMAL ALLOCATION:
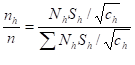
TAKE A LARGER SAMPLE IF:
1. THE STRATUM IS LARGER
2. THE STRATUM IS MORE VARIABLE INTERNALLY
3, SAMPLING IS CHEAPER IN THE STRATUM.
10. HOW TO ALLOCATE SAMPLE SIZES TO STRATA, WHEN COSTS AND VARIANCES ARE UNKNOWN
· ASSUME COSTS SAME
· ASSUME VARIANCES SAME
· REVIEW VARIANCES OF ESTIMATES OF INTEREST FOR:
o EQUAL ALLOCATION
o PROPORTIONAL ALLOCATION (SELF-WEIGHTING)
IN A SELF-WEIGHTING DESIGN, THE SAMPLE MEAN IS AN UNBIASED ESTIMATE
OF POPULATION MEAN:
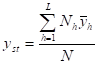
![]() (THE
SAME FOR ALL STRATA)
(THE
SAME FOR ALL STRATA)
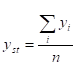 (THE
AVERAGE OF ALL OBSERVATIONS, REGARDLESS OF STRATUM)
(THE
AVERAGE OF ALL OBSERVATIONS, REGARDLESS OF STRATUM)
11. SELECTION OF VARIABLES OF STRATIFICATION
· COARSE DIVISIONS FOR SEVERAL VARIABLES PREFERABLE TO FINE DIVISIONS FOR A FEW VARIABLES
· NO NEED TO CROSS-CLASSIFY; COLLAPSE UNIMPORTANT
CELLS ("NESTED" STRATIFICATION)
· STRATIFY ON VARIABLES UNRELATED TO EACH OTHER
· QUALITATIVE/SUBJECTIVE VARIABLES: CAN BE USED FOR STRATIFICATION~ BUT NOT IN ESTIMATION PROCEDURE
· AVOID STRATIFICATION PAST THE LIMIT OF TWO UNITS PER CELL
8.5 When and How to Use Cluster Sampling
V. WHEN AND HOW TO USE CLUSTER SAMPLING
1. NATURE OF SITUATIONS WHICH WARRANT USE OF CLUSTER SAMPLING
· NATURAL CLUSTERS OF THE POPULATION (HOUSEHOLDS, SCHOOLS, SMSAs)
· CONFINING SAMPLING TO NEARBY UNITS PRODUCES LARGE COST SAVINGS
· NO FRAME AVAILABLE FOR ALL UNITS, BUT COULD CONSTRUCT FRAME FOR A FEW CLUSTERS
· ELEMENTS WITHIN CLUSTERS ARE NOT HIGHLY "SIMILAR" WITH RESPECT TO VARIABLES OF INTEREST.
2. THE "CLUSTER EFFECT"
ELEMENTS WITHIN CLUSTER ARE USUALLY POSITIVELY CORRELATED
POSITIVE INTRACLUSTER CORRELATION COEFFICIENT (ρ) REDUCES PRECISION OVER THAT OF A SIMPLE RANDOM SAMPLE OF THE SAME SIZE
![]()
COST SAVING OFFSETS LOSS IN PRECISION
(NOTE: IF ρ IS NEGATIVE), CLUSTERING IMPROVES PRECISION)
3. DETERMINING SAMPLE SIZES IN CLUSTER SAMPLING (EQUAL-SIZE
CLUSTERS)
COST FUNCTION:
![]()
WHERE
M = CLUSTER SIZE
n = SAMPLE SIZE
VARIANCE FUNCTION:
![]()
WHERE
![]()
IS THE WITHIN-CLUSTER VARIANCE.
WE COULD SOLVE FOR THE VALUE OF M (E.G., TO MINIMIZE THE VARIANCE, SUBJECT TO A FIXED COST), BUT WILL NOT (SEE COCHRAN’S BOOK FOR THIS). THE ABOVE VARIANCE FUNCTION IS RARELY EVER KNOWN. THIS FORMULATION WAS DEVELOPED SIMPLY TO PROVIDE GUIDANCE IN DETERMINING THIS CLUSTER SIZE. IN FACT, IN MOST SOCIOECONOMIC SURVEYS, THE CLUSTER SIZE IS NOT DETERMINED BY THE SURVEY DESIGNER, BUT IS TAKEN AS AN EXISTING ADMINISTRATIVE UNIT (E.G., CENSUS ENUMERATION AREA, DISTRICT, VILLAGE, SCHOOL). BASED ON THIS MODEL, THE FOLLOWING RECOMMENDATIONS ARE MADE.
THE OPTIMAL CLUSTER SIZE (M) BECOMES SMALLER WHEN:
· LENGTH OF INTERVIEW INCREASES
· TRAVEL BECOMES CHEAPER
· THE ELEMENTS BECOME MORE DENSE (CLUSTERS CLOSER TOGETHER)
· THE TOTAL AMOUNT OF MONEY (C) INCREASES
· THE CLUSTERS ARE INTERNALLY HOMOGENEOUS (THE WITHIN-CLUSTER VARIANCE IS SMALL RELATIVE TO THE POPULATION VARIANCE)
ALTHOUGH THE ABOVE FORMULATION IS NOT USUALLY USED TO DETERMINE M, IT CAN BE USED TO DETERMINE THE VALUE OF n (THE NUMBER OF CLUSTERS OF SIZE M TO SELECT. THE VALUE OF n IS THE SOLUTION OF THE FOLLOWING EQUATION:
2c1M√n / c2 =
√(1 + 4Cc1M/c22) - 1
4. VARIABLE-SIZE CLUSTERS: SAMPLING WITH PROBABILITIES
PROPORTIONAL TO SIZE (PPS) (SAMPLING WITH REPLACEMENT)
· SIMPLE RANDOM SAMPLE OF CLUSTERS YIELDS ESTIMATE OF POOR PRECISION IF CLUSTERS VARY IN SIZE
· LARGE INCREASE IN PRECISION IF SELECT CLUSTERS WITH PROBABILITIES PROPORTIONAL TO SIZE
· FORMULAS FOR VARIANCES ARE SIMPLER
(NOTE: PPS IS NOT SELF-WEIGHTING)
5. VARIABLE-SIZE CLUSTERS: SAMPLING WITH PROBABILITIES
PROPORTIONAL TO A MEASURE OF SIZE (PPMS)
IF WE DON'T KNOW CLUSTER SIZE EXACTLY, SET PROBABILITIES
PROPORTIONAL TO A MEASURE OF SIZE
![]()
6. VARIABLE-SIZE CLUSTERS: PPMS, WITHOUT REPLACEMENT
IN STRATIFIED CLUSTER SAMPLING, THERE MAY BE A SMALL
NUMBER OF LARGE CLUSTERS IN A STRATUM, SO THAT FPC IS
NOT NEGLIGIBLE
IF WE USE SAMPLING WITHOUT REPLACEMENT, FORMULAS FOR
VARIANCE BECOME VERY COMPLICATED
USE THE RAO-HARTLEY-COCHRAN TECHNIQUE TO ENABLE VARIANCE ESTIMATION:
· ASSIGN UNITS TO GROUPS AT RANDOM, MAKING THE NUMBER OF UNITS PER GROUP AS NEARLY EQUAL AS POSSIBLE
· SELECT 1 UNIT FROM EACH GROUP, PPS
THE ESTIMATOR
![]()
IS UNBIASED. ITS ESTIMATED VARIANCE IS:
![]()
WHERE
![]()
WHERE THERE ARE k GROUPS OF SIZE Q+1 AND n-k GROUPS OF SIZE Q.
7. STRATIFICATION OF CLUSTERS
AS AN ALTERNATIVE TO PPS, WE CAN STRATIFY CLUSTERS BY SIZE,
AND SELECT WITH EQUAL PROBABILITIES FROM WITHIN STRATA.
8. STRATIFICATION OF CLUSTERS: THE USE OF A CERTAINTY STRATUM
IN PPS SELECTION, THE USUAL PROCEDURE IS AS FOLLOWS:
SIZE CUM. SIZE ASSIGNED RANDOM
UNIT Mi ΣMi RANGE NUMBER
1 4 4 1-4
2 6 10 5-10 x
…
N 3 372 369-372 x
WITH REPLACEMENT: NO PROBLEM
WITHOUT REPLACEMENT: IF SOME CLUSTERS ARE LARGE, OR THE NUMBER OF CLUSTERS IS SMALL IT MAY NOT BE POSSIBLE TO IMPLEMENT PPS.
SOLUTION: DEFINE SKIP INTERVAL, k. DEFINE THE CRITICAL SIZE AS
![]()
PLACE ALL CLUSTERS OF SIZE GREATER THAN s IN A CERTAINTY
STRATUM. APPLY PPS TO NONCERTAINTY STRATUM. USE PROPORTIONAL SAMPLING FROM CERTAINTY CLUSTERS.
9. GENERAL RECOMMENDATIONS REGARDING CLUSTER SAMPLING
· PPS OR STRATIFY BY SIZE (AND SELECT WITH EQUAL PROBABILITIES)
· CERTAINTY STRATUM FOR LARGE CLUSTERS
· SEVERAL ESTIMATES OF INTEREST (CHECK TEXTBOOK FOR FORMULAS)
· BE CAREFUL – IF CLUSTERS ARE HIGHLY INTERNALLY HOMOGENEOUS, THE "EFFECTIVE" SAMPLE SIZE EQUALS NUMBER OF CLUSTERS, NOT TOTAL NUMBER OF UNITS
· USUAL CROSSTABS, TESTS OF SIGNIFICANCE NOT APPLICABLE
IN CLUSTER SAMPLING, A KEY PARAMETER IS THE INTRACLUSTER CORRELATION COEFFICIENT (“ICC”). IT IS THE CORRELATION COEFFICIENT BETWEEN PAIRS OF UNITS WITHIN THE SAME CLUSTER, DEFINED AS
ρ = E(yij – μ)(yik – μ) / E(yij –μ)2
WHERE THE NUMERATOR IS AVERAGED OVER ALL DISTINCT PAIRS OF ELEMENTS (SUBUNITS) WITHIN THE SAME CLUSTER, AND THE DENOMINATOR IS AVERAGED OVER ALL ELEMENTS. THE ICC IS A MEASURE OF THE INTERNAL HOMOGENEITY OF CLUSTERS.
IN CLUSTER SAMPLING THERE ARE TWO MEANS OF INTEREST – THE MEAN PER UNIT (CLUSTER) AND THE MEAN PER ELEMENT. THE MEAN PER UNIT IS THE MEAN OF THE CLUSTER TOTALS, Σyi / N, AND THE MEAN PER ELEMENT IS THE MEAN OF THE ELEMENTS, μ = Σyi/NM.
AN APPROXIMATE EXPRESSION FOR THE VARIANCE OF THE SAMPLE MEAN PER ELEMENT IS
var (sample mean per element) = [(1 – f) S2 / n ] (1 + (M – 1) ρ)
THE FIRST TERM, IN BRACKETS, IS THE VARIANCE OF THE SAMPLE MEAN IN SIMPLE RANDOM SAMPLING (SRS). THE SECOND TERM, 1 + (M – 1) ρ, IS A FACTOR THAT SHOWS HOW MUCH THE VARIANCE OF THE SAMPLE MEAN CHANGES IN CLUSTER SAMPLING, FROM THAT FOR SRS. THE TERM 1 + (M – 1) ρ IS KISH’S “DESIGN EFFECT,” OR “DEFF” FOR SAMPLING CLUSTERS OF SIZE M.
THIS FACTOR, DEFF = 1 + (m – 1)ρ, INDICATES HOW MUCH THE VARIANCE OF THE SAMPLE MEAN DIFFERS IN CLUSTER SAMPLING FROM THE VARIANCE IN SIMPLE RANDOM SAMPLING. SINCE THE ESTIMATED SAMPLE SIZE FOR SRS IS PROPORTIONAL TO THE VARIANCE, DEFF ALSO INDICATES HOW MUCH THE SAMPLE SIZE OF CLUSTERS MUST BE INCREASED TO ACHIEVE THE SAME PRECISION AS A SRS OF THE SAME SIZE. THIS IS THE PRINCIPAL WAY IN WHICH THE SAMPLE SIZE IS ESTIMATED FOR CLUSTER SAMPLING (I.E., ESTIMATE THE SAMPLE SIZE FOR SRS AND MULTIPLY BY THE DEFF. SINCE M IS TYPICALLY GIVEN, ALL THAT IS NEEDED TO KNOW DEFF IS THE VALUE OF ρ. IF CLUSTERS ARE HIGHLY INTERNALLY HOMOGENEOUS, USE A LARGE VALUE OF ρ, SUCH AS .5 TO .9. IF THE ELEMENTS OF A CLUSTER VARY ABOUT AS MUCH AS IN THE GENERAL POPULATION, USE A SMALL VALUE OF ρ, SUCH AS 0 - .3. NOTE THAT THE VALUE OF ρ GENERALLY DECREASES AS THE CLUSTER SIZE (M) INCREASES. NOTE ALSO THAT THE VALUE OF ρ DIFFERS FOR EVERY VARIABLE OF INTEREST (I.E., FOR WHICH THE MEAN IS TO BE ESTIMATED). USE THE VALUE OF ρ CORRESPONDING TO THE MOST IMPORTANT VARIABLES OF INTEREST.
FOR MOST APPLICATIONS, ρ IS POSITIVE, SO THE FACTOR IS POSITIVE. (IT CAN BE NEGATIVE ONLY IF M IS VERY SMALL (FOR EXAMPLE, GENDER IN TWO-PERSON HOUSEHOLDS).) IF S2 DENOTES THE POPULATION VARIANCE, S12 DENOTES THE VARIANCE AMONG CLUSTER MEANS, AND S22 DENOTES THE WITHIN-CLUSTER VARIANCE, THEN THE FOLLOWING RELATIONSHIPS ARE APPROXIMATE:
ρ = (MS12 – S2)[(M -1)S2]; S22 = S2(1 – ρ); (1 – ρ)/ρ= S22 / (S12 – S22/M).
IF M IS LARGE, THE FOLLOWING RELATIONSHIPS ARE APPROXIMATE:
S2 = S12 + S22; S12 = ρ S2; S22 = (1 – ρ) S2.
8.6 When and How to Use Systematic Sampling
VI. WHEN AND HOW TO USE SYSTEMATIC SAMPLING
1. REASONS FOR USING SYSTEMATIC SAMPLING
· TO SELECT A SIMPLE RANDOM SAMPLE (FROM A RANDOMLY ORDERED LIST)
· FOR VARIANCE REDUCTION (SAMPLING FROM TREND DATA)
· TO SELECT A SAMPLE QUICKLY, WHEN IT DOESN'T MATTER IF WE CAN COMPUTE THE VARIANCE (E.G., SECOND-STAGE SAMPLING WHEN THE SAMPLING FRACTION (n/N) OF THE FIRST-STAGE UNITS IS SMALL)
· TO SELECT A SAMPLE QUICKLY IN GENERAL (BEST TO SELECT SEVERAL REPLICATED SAMPLES IN ORDER TO BE ABLE TO COMPUTE THE VARIANCE)
2. NATURE OF SITUATION WHICH WARRANTS USE OF SYSTEMATIC SAMPLING
· MANUAL RECORD SYSTEM (PHYSICAL LIST, CARD FILES)
· FILES IN RANDOM ORDER
· LIMITED TIME OR RESOURCES FOR SELECTING SAMPLE
· NO PERIODICITIES SUSPECTED IN DATA
3. HOW TO SELECT A SYSTEMATIC SAMPLE
· EVERY k-th, WITH RANDOM START
· EVERY k-th, WITH SEVERAL RANDOM STARTS
· INTEGER SAMPLING INTERVAL (k)
· NON-INTEGER SAMPLING INTERVAL
8.7 When and How to use Multistage Sampling
VII. WHEN AND HOW TO USE MULTISTAGE SAMPLING (TWO-STAGE)
1. NATURE OF SITUATION WHICH WARRANTS USE OF A MULTISTAGE DESIGN
AS FOR CLUSTER SAMPLING -- EXCEPT THAT IT IS IMPRACTICAL OR INEFFICIENT TO SAMPLE ALL OF THE CLUSTER (LARGE CLUSTER
SIZE, LARGE INTRACLUSTER CORRELATION COEFFICIENT)
EXAMPLE: SCHOOLS; SMSAs; HOSPITALS; CLINICS
2. ESTIMATED MEAN IN TWO-STAGE SAMPLING (EQUAL-SIZED PRIMARY
UNITS, WITHOUT REPLACEMENT)
NOTATION AND FORMULAS:
![]() = VALUE
FOR THE j-th ELEMENT IN THE i-th PRIMARY UNIT
= VALUE
FOR THE j-th ELEMENT IN THE i-th PRIMARY UNIT
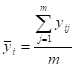 = SAMPLE
MEAN PER ELEMENT IN THE i-th PRIMARY UNIT
= SAMPLE
MEAN PER ELEMENT IN THE i-th PRIMARY UNIT
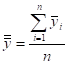 = OVERALL
SAMPLE MEAN PER ELEMENT
= OVERALL
SAMPLE MEAN PER ELEMENT
![]() =
VARIANCE AMONG PRIMARY UNIT MEANS
=
VARIANCE AMONG PRIMARY UNIT MEANS
![]() =
VARIANCE AMONG ELEMENTS WITHIN PRIMARY UNITS
=
VARIANCE AMONG ELEMENTS WITHIN PRIMARY UNITS
![]() IS AN
UNBIASED ESTIMATE OF THE POPULATION MEAN PER ELEMENT
IS AN
UNBIASED ESTIMATE OF THE POPULATION MEAN PER ELEMENT
![]()
![]()
NOTE: IF ![]() IS
SMALL, WE CAN USE SYSTEMATIC SAMPLING IN THE SECOND-STAGE UNITS, SINCE WE DON’T
NEED TO BE ABLE TO ESTIMATE
IS
SMALL, WE CAN USE SYSTEMATIC SAMPLING IN THE SECOND-STAGE UNITS, SINCE WE DON’T
NEED TO BE ABLE TO ESTIMATE ![]() .
.
3. OPTIMAL SAMPLING AND SUBSAMPLING FRACTIONS (EQUAL-SIZED PRIMARY UNITS)
![]()
![]()
THE OPTIMAL SECOND-STAGE SAMPLE SIZE IS
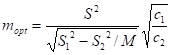
THE VALUE OF n IS DETERMINED BY SETTING EITHER THE COST OR THE VARIANCE, AND SOLVING THE RESPECTIVE EQUATION FOR n.
IF ρ DENOTES THE INTRACLUSTER CORRELATION COEFFICIENT (DEFINED EARLIER, IN THE CLUSTER-SAMPLING SECTION), THE FOLLOWING APPROXIMATION HOLDS, FOR ρ NOT EQUAL TO ZERO:
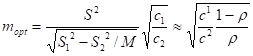
NOTE: IF ρ IS SMALL, mopt IS LARGE; IF ρ IS LARGE, mopt IS SMALL.
THE COMMENTS MADE ABOUT ρ IN CLUSTER SAMPLING GENERALLY APPLY TO MULTISTAGE SAMPLING.
THE EXPRESSION INVOLVING ρ IS USED BECAUSE THE VARIANCES ARE USUALLY NOT KNOWN, BUT ρ CAN BE APPROXIMATED. MOST SURVEYS ARE CONCERNED WITH COLLECTING DATA ON A NUMBER OF VARIABLES, AND THE VALUE OF ρ IS DIFFERENCT FOR EACH OF THEM. THE FIRST-STAGE SAMPLE UNITS (PRIMARY SAMPLING UNITS, OR PSUs) FOR A SURVEY ARE OFTEN DETERMINED BY ADMINISTRATIVE CONVENIENCE, E.G., AS CENSUS ENUMERATION AREAS, VILLAGES, OR DISTRICTS, FOR WHICH DATA EXIST TO FACILITATE SAMPLE DESIGN. THE OPTIMAL WITHIN-PSU SAMPLE SIZE IS DETERMINED BY CONSIDERING HOW HOMOGENEOUS THE PSUs ARE, ON AVERAGE, OVER ALL IMPORTANT VARIABLES. FOR EXAMPLE, IF THE PSUs ARE HIGHLY INTERNALLY HOMOGENEOUS, USE A LARGE VALUE FOR ρ (E.G., ρ = .5 TO .9), AND IF THE PSUs ARE NOT HIGHLY INTERNALLY HOMOGENEOUS, USE A SMALL VALUE FOR ρ (E.G., ρ = 0 TO .3). IN MANY SOCIO-ECONOMIC SURVEYS, THE VALUE OF m IS IN THE RANGE 15-30 (E.G., A SAMPLE OF 15 HOUSEHOLDS IS SELECTED FROM EACH VILLAGE (PSU). IN MANY APPLICATION, THE OPTIMUM IS “FLAT” (I.E., IS NOT HIGHLY SENSITIVE TO CHANGES IN THE VALUE OF ρ.)
ONCE THE VALUE OF m (WITHIN-FIRST-STAGE-UNIT SAMPLE SIZE) IS DETERMINED, IT REMAINS TO DETERMINE THE VALUE NUMBER, n, OF UNITS TO SELECT. THE PROCEDURE FOR DOING THIS IS THE SAME AS FOR CLUSTER SAMPLING. THE VARIANCE EXPRESSION PRESENTED ABOVE IS NOT USEFUL FOR ESTIMATING THE SAMPLE SIZE, SINCE THE VARIANCES ARE TYPICALLY NOT KNOWN PRIOR TO THE SURVEY.
IN TERMS OF ρ, AN APPROXIMATE EXPRESSION FOR THE VARIANCE, FOR N AND M LARGE, IS
![]()
WHERE S2 DENOTES THE POPULATION VARIANCE. AS IN THE CASE OF CLUSTER SAMPLING, THE TERM PRECEDING THE TERM IN BRACKETS IS THE VARIANCE FOR THE SAMPLE MEAN OF A SIMPLE RANDOM SAMPLE. THE TERM IN BRACKETS, 1 + (m-1)ρ, IS KISH’S DEFF. AS IN THE CASE OF CLUSTER SAMPLING, THE NUMBER OF FIRST-STAGE UNITS TO SELECT IS OBTAINED BY DETERMINING THE SAMPLE SIZE (FOR A SPECIFIED LEVEL OF PRECISION) FOR SIMPLE RANDOM SAMPLING AND MULTIIPLYING BY THE VALUE OF DEFF.
4. UNEQUAL-SIZED PRIMARY UNITS: SAMPLING WITH EQUAL PROBABILITIES
IF STRATIFY PRIMARY UNITS BY SIZE, USE SELECTION WITH EQUAL
PROBABILITIES
UNBIASED ESTIMATE:
![]()
THIS ESTIMATE IS SELF-WEIGHTING IF ![]() =
CONSTANT =
=
CONSTANT = ![]()
5. UNEQUAL-SIZED PRIMARY UNITS: PPS OR PPES SAMPLING
IF PRIMARY UNITS ARE NOT STRATIFIED BY SIZE, USE PPS OR PPES SAMPLING
UNBIASED ESTIMATE FOR PPES:
![]()
THIS ESTIMATOR IS SELF-WEIGHTING IF ![]() =
CONSTANT =
=
CONSTANT = ![]() ,
,
I.E., IF ![]() THEN
THEN
![]()
FOR PPS, ![]() ;
UNBIASED ESTIMATE IS:
;
UNBIASED ESTIMATE IS:
![]()
THIS ESTIMATOR IS SELF-WEIGHTING IF mi = CONSTANT = m:
![]()
6. UNEQUAL-SIZED PRIMARY UNITS: OPTIMAL SAMPLING AND SUBSAMPLING FRACTIONS, SAMPING WITH EQUAL PROBABILITIES
COST = ![]()
(THE LAST TERM IS THE LISTING COST).
FROM THE EXPRESSIONS FOR THE VARIANCE, WE CAN SHOW:
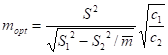
IF ![]() DENOTES
THE AVERAGE VALUE OF THE INTRA-UNIT CORRELATION COEFFICIENT (DEFINED AS IN THE
SECTION ON CLUSTER SAMPLING), THEN THE FOLLOWING APPROXIMATION HOLDS, FOR
DENOTES
THE AVERAGE VALUE OF THE INTRA-UNIT CORRELATION COEFFICIENT (DEFINED AS IN THE
SECTION ON CLUSTER SAMPLING), THEN THE FOLLOWING APPROXIMATION HOLDS, FOR ![]() NOT
EQUAL TO ZERO.
NOT
EQUAL TO ZERO.
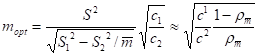
7. UNEQUAL-SIZED PRIMARY UNITS: OPTIMAL SAMPLING AND SUBSAMPLING FRACTIONS, WITH PPES SAMPLING
COST = AS ABOVE
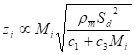
WHERE ![]() IS THE
VARIANCE AMONG ALL UNITS IN THE POPULATION.
IS THE
VARIANCE AMONG ALL UNITS IN THE POPULATION.
·
IF c3Mi IS SMALL AND ![]() IS
CONSTANT, PPS IS BEST (
IS
CONSTANT, PPS IS BEST (![]() )
)
·
IF c3Mi IS SMALL AND ![]() DECREASES
WITH INCREASING Mi, THEN OPTIMAL PROBABILITIES LIE BETWEEN
DECREASES
WITH INCREASING Mi, THEN OPTIMAL PROBABILITIES LIE BETWEEN ![]() AND
AND ![]() .
.
·
IF c3Mi IS LARGE, zi IS
BETWEEN ![]() AND
A CONSTANT (EQUAL PROBABILITIES)
AND
A CONSTANT (EQUAL PROBABILITIES)
·
IF c1 AND c3Mi ARE
COMPARABLE, ![]() IS
REASONABLE.
IS
REASONABLE.
8. STRATIFICATION
· AS IN CLUSTER SAMPLING, IF THERE ARE SOME VERY LARGE UNITS, PLACE THEM IN A CERTAINTY STRATUM
· FOR SELF-WEIGHTING ESTIMATES, USE PROPORTIONAL SAMPLING FROM THE UNITS IN THE CERTAINTY STRATUM (ρ WILL LIKELY BE LOW SINCE THE UNITS ARE LARGE)
· FOR SELF-WEIGHTING ESTIMATE, USE PPS SAMPLING FROM THE UNITS IN THE NONCERTAINTY STRATUM, WITH SELECTION OF AN EQUAL NUMBER OF ELEMENTS FROM EACH
9. SELECTION WITH UNEQUAL PROBABILITIES WITHOUT REPLACEMENT
· FOR FEW PRIMARY UNITS, USE REPLACEMENT SAMPLING
· TO ESTIMATE VARIANCE, USE RAO-HARTLEY-COCHRAN TECHNIQUE:
o ASSIGN UNITS TO GROUPS AT RANDOM, WITH NUMBER OF UNITS IN A GROUP AS NEARLY EQUAL AS POSSIBLE
o SELECT ONE UNIT PER GROUP, PPS
o UNBIASED ESTIMATE AVAILABLE FOR VARIANCE
10. GENERAL RECOMMENDATIONS REGARDING TWO-STAGE DESIGNS
IF MUST LIST WHOLE POPULATION TO IMPLEMENT PPS, FORGET IT (USE PPES OR EQUAL PROBABILITIES)
FORM CERTAINTY STRATUM OF LARGEST CLUSTERS (USE 2/3 k RULE, AS IN CLUSTER SAMPLING)
USE PROPORTIONAL SAMPLING FROM CERTAINTY CLUSTERS
FOR NONCERTAINTY STRATUM, USE EITHER:
- PPS, PLUS EQUAL NUMBER OF ELEMENTS PER UNIT; OR
- EQUAL PROBABILITIES, WITH PROPORTIONAL SAMPLING IN EACH UNIT
IF USE REPLACEMENT SAMPLING FOR PRIMARY UNITS, USE RHC METHOD OF SELECTION
IF ![]() IS
SMALL, CAN USE SYSTEMATIC SAMPLING IN SECOND-STAGE SELECTION (DON’T NEED
ESTlMATE OF WITHIN-CLUSTER VARIANCE)
IS
SMALL, CAN USE SYSTEMATIC SAMPLING IN SECOND-STAGE SELECTION (DON’T NEED
ESTlMATE OF WITHIN-CLUSTER VARIANCE)
CONSIDER ALTERNATIVE ESTIMATES (UNBIASED, SAMPLE MEAN, RATIO-TO-SIZE)
USE SELF-WEIGHTING DESIGN WITHIN STRATA, OVERALL UNLESS LOSE TOO MUCH PRECISION
DETERMINING THE FIRST-STAGE-UNIT SAMPLE SIZE BY ESTIMATING
THE SAMPLE SIZE FOR SIMPLE RANDOM SAMPLING AND MULTIPLYING THIS VALUE BY THE
VALUE OF THE DESIGN EFFECT, DEFF, CORRESPONDING TO THE VALUE OF THE INTRA-UNIT
CORRELATION COEFFICIENT, ρ, FOR THE MORE IMPORTANT SURVEY VARIABLES (FOR WHICH
THE MEAN IS TO BE ESTIMATED).
8.8 When and How to Use Double Sampling
VIII. WHEN AND HOW TO USE DOUBLE SAMPLING
1. NATURE OF SITUATION WHICH WARRANTS USE OF DOUBLE SAMPLING
· NEED INFORMATION ON COSTS, VARIANCES, AUXILIARY VARIABLE (STRATIFICATION)
· SCREENING
2. DETERMINATION OF SAMPLE SIZE IN DOUBLE SAMPLING
![]() = FIRST
PHASE SAMPLE SIZE
= FIRST
PHASE SAMPLE SIZE
![]() = SECOND
PHASE SAMPLE SIZE
= SECOND
PHASE SAMPLE SIZE
![]()
OPTIMAL ALLOCATION:
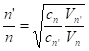
WHERE
Vn = WITHIN-STRATUM VARIANCE
Vn’ = BETWEEN-STRATUM VARIANCE
NOTES:
IF Vn’/Vn IS VERY LARGE, STRATIFICATION IS EFFECTIVE, AND IT PAYS TO HAVE A LARGE FIRST-PHASE SAMPLE, I.E., n’/n IS LARGE.
IF cn/cn’ IS VERY LARGE, THE FIRST-PHASE SAMPLE IS INEXPENSIVE, AND SO n’/n IS LARGE.
8.9 How to Resolve Conflicting Multiple Survey Design Objectives
IX. HOW TO RESOLVE CONFLICTING/MULTIPLE SURVEY DESIGN OBJECTIVES
· DETERMINE OPTIMAL ALLOCATIONS FOR VARIOUS OBJECTIVES, AND SELECT A GOOD COMPROMISE DESIGN.
· PLACE CONSTRAINTS ON THE VARIANCES OF KEY ESTIMATES, USE OPTIMIZATION METHODS TO DETERMINE AN ALLOCATION THAT SATISFIES THE CONSTRAINTS (E.G., NEYMAN ALLOCATION TO STRATA).
· MINIMIZE A LINEAR COMBINATION OF THE VARIANCES OF SEVERAL KEY ESTIMATES (NOT RECOMMENDED. IT IS DIFFICULT, AND MAY FAIL TO ADDRESS IMPORTANT CONSTRAINTS.)
· BEST APPROACH IS ITERATIVE: EXAMINE ALTERNATIVES. SEEK A DESIGN THAT SATSIFIES ALL IMPORTANT CONSTRAINTS, EVEN THOUGH IT MAY NOT BE “OPTIMAL” WITH RESECT TO A SINGLE OBJECTIVE FUNCTION.
PART TWO: HOW TO DESIGN ANALYTICAL SURVEYS
8.10 Review of Regression Analysis
I. REVIEW OF REGRESSION ANALYSIS (GENERAL LINEAR STATISTICAL MODEL, INCLUDING EXPERIMENTAL-DESIGN AND QUASI-EXPERIMENTAL DESIGN MODELS)
REFERENCE: SHARON L. LOHR, SAMPLING: DESIGN AND ANALYSIS 2ND ED., (CENGAGE LEARNING, 2009)
1. LINEAR REGRESSION MODEL (UNIVARIATE)
![]()
WHERE
![]() =
DEPENDENT (RESPONSE) VARIABLE
=
DEPENDENT (RESPONSE) VARIABLE
![]() =
INDEPENDENT (EXPLANATORY) VARIABLE
=
INDEPENDENT (EXPLANATORY) VARIABLE
![]() =
REGRESSION COEFFICIENT (PARAMETER)
=
REGRESSION COEFFICIENT (PARAMETER)
![]() = ERROR
TERM (MEAN = 0, VARIANCE = σ2)
= ERROR
TERM (MEAN = 0, VARIANCE = σ2)
(NOTE: IT IS COMMON TO WRITE REGRESSION EQUATIONS USING LOWER-CASE SYMBOLS FOR THE RANDOM VARIABLES, AND TO USE UPPER-CASE SYMBOLS FOR “CROSSPRODUCTS” MATRICES.)
ASSUMPTIONS:
THE ![]() ARE
UNCORRELATED WITH EACH OTHER AND WITH THE x's, AND HAVE ZERO MEAN AND
THE SAME VARIANCE.
ARE
UNCORRELATED WITH EACH OTHER AND WITH THE x's, AND HAVE ZERO MEAN AND
THE SAME VARIANCE.
OPTIONAL: IN MATRIX NOTATION:
![]()
WHERE
![]() =
OBSERVATION MATRIX (DESIGN MATRIX)
=
OBSERVATION MATRIX (DESIGN MATRIX)
![]() = VECTOR
OF OBSERVED
= VECTOR
OF OBSERVED ![]()
![]() = VECTOR
OF PARAMETERS
= VECTOR
OF PARAMETERS
![]() = ERROR
VECTOR
= ERROR
VECTOR
LEAST SQUARES ESTIMATE OF THE b’s:
![]()
WHERE
![]() =
CROSSPRODUCTS MATRIX
=
CROSSPRODUCTS MATRIX
![]() =
GENERALIZED (CONDITIONAL) INVERSE OF
=
GENERALIZED (CONDITIONAL) INVERSE OF ![]()
NOTE: THE MODEL IS LINEAR IN THE PARAMETERS, NOT IN THE x's.
SOME OF THE x's MAY BE NONLINEAR, E.G.,
![]()
DISCRETE INDEPENDENT VARIABLES (BINARY VARIABLES, DICHOTOMOUS VARIABLES, INDICATOR VARIABLES, DUMMY VARIABLES, CATEGORICAL VARIABLES, NOMINAL VARIABLES, QUALITATIVE VARIABLES)
X7 = 0 FOR MALE, 1 FOR FEMALE
X8 = 0 FOR WHITE, 1 FOR BLACK, 2 FOR NATIVE AMERICAN, 3 FOR HISPANIC, 4 FOR ASIAN, 5 FOR OTHER
X9 = -2 FOR VERY DISSATISFIED, -1 FOR DISSATISFIED, 0 FOR NEITHER SATISFIED NOR DISSATISFIED, 1 FOR SATISFIED, 2 VERY SATISFIED
CAN INCLUDE X7 AND X9 IN THE REGRESSION MODEL, BUT NOT X8, SINCE IT IS NOT ORDERED. DEFINE DUMMY VARIABLES:
X10 = 0 IF X8=0, 1 IF X8<>0
X11 = 0 IF X8=1, 1 IF X8<>1
X12 = 0 IF X8=2, 1 IF X8<>2
X13 = 0 IF X8=3, 1 IF X8<>3
X14 = 0 IF X8=4, 1 IF X8<>4
X15 = 0 IF X8=5, 1 IF X8<>5
MAY INCLUDE ANY FIVE OF THESE SIX DUMMY VARIABLES IN THE MODEL. SHOULD NOT INCLUDE ALL SIX, BECAUSE THEY SUM TO 1 (A PERSON MUST BE OF ONE RACE), AND THIS LINEAR DEPENDENCY WOULD CAUSE THE MODEL TO BE INDETERMINANT (IF NO LINEAR DEPENDENCIES, THEN CAN INVERT THE CROSSPRODUCTS MATRIX).
BINARY DEPENDENT VARIABLE
IF THE DEPENDENT VARIABLE IS BINARY, THEN THE ERROR TERMS WILL NOT ALL HAVE THE SAME VARIANCES. TWO PROBLEMS ARISE:
1. HOMOSCEDASTICITY (EQUAL-VARIANCE) ASSUMPTION IS VIOLATED
USE GENERALIZED LEAST SQUARES (GAUSS-MARKOV) ESTIMATION
PERFORM REGRESSION ITERATIVELY: E.G., USE FIRST ESTIMATE FOR E(y)=p, AND SET VARIANCE EQUAL TO p(1-p)
2. E(y) IS A PROBABILITY, BUT THE PREDICTIONS WILL FALL BEYOND THE (0, 1) INTERVAL
APPLY A LOGISTIC TRANSFORMATION (SUFFICIENT STATISTIC)
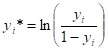
AND USE A REGRESSON MODEL FOR THE LOGISTIC VARIABLE:
![]()
INTERACTION TERMS; POOLED VS. SEPARATE REGRESSION MODELS
SEPARATE REGRESSION EQUATIONS:
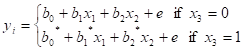
COMBINED (POOLED) REGRESSION EQUATIONS:
![]()
USE SEPARATE REGRESSION EQUATIONS IF A NEW VARIABLE IS INTERACTING WITH A LARGE NUMBER OF THE OLD VARIABLES
LINEAR DEPENDENCY
![]()
![]()
IF THERE IS A LINEAR DEPENDENCY AMONG THE x’s, E.G.,
![]()
THEN CAN’T USE A REGRESSION PACKAGE THAT CALCULATES ONLY MATRIX INVERSES (NOT GENERALIZED INVERSES).
SOLUTION: REMOVE LINEAR DEPENDENCIES (BY CHANGING THE VARIABLES INCLUDED IN THE MODEL).
MULTICOLLINEARITY
IF corr(x1, x2) IS HIGH, THEN corr(b1, b2) IS HIGH, AND THE STANDARD ERROR OF THE ESTIMATES b1 AND b2 WILL BE LARGE .
SOLUTIONS:
· REMOVE ONE OF THE x's
· TRANSFORM E.G., x3 = x1 - x2
· ORTHOGONALIZE THROUGH CONTROL OF x's (PRIOR TO DATA COLLECTION)
· ORTHOGONALIZE THROUGH FACTOR ANALYSIS OR PRINCIPAL COMONENTS ANALYSIS (LOSE NATURAL VARIABLES)
·
CATEGORICAL REPRESENTATIONS OF CONTINUOUS VARIABLES
![]()
OR
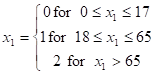
ADVANTAGES OF CATEGORICAL REPRESENTATION: SURVEY DESIGN (STRATIFICATION)
OTHER REGRESSION TOPICS
· MULTIVARIATE (EACH OBSERVATION CONSISTS OF A VECTOR OF OBSERVED y's)
· SIMULTANEOUS EQUATION MODELS (CAN'T USE ORDINARY LEAST SQUARES ESTIMATION PROCEDURE)
· AUTOCORRELATED RESIDUALS (USE GENERALIZED LEAST SQUARES, NONLINEAR REGRESSION)
· PATH ANALYSIS
· RIDGE REGRESSION
· STEPWISE REGRESSION
· HALF-NORMAL PLOTS
· WEIGHTED REGRESSION
· REGRESSION OVER FINITE POPULATION
· VARIANCE-STABILIZING TRANSFORMATIONS
· COMPUTATIONAL CONSIDERATIONS (STORED CROSSPRODUCTS MATRIX)
· ANALYSIS OF RESIDUALS
· ERRORS IN OBSERVED VARIABLES (x's)
· MISSPECIFIED MODEL
· TESTS OF SIGNIFICANCE OF REGRESSION COEFFICIENTS
· MULTIPLE CORRELATION COEFFICIENT
· PRINCIPLE OF CONDITIONAL ERROR
8.11 General Procedure for Designing an Analytical Survey
II. GENERAL PROCEDURES FOR DESIGNING AN ANALYTICAL SURVEY
1. SAMPLE SURVEY DESIGN FOR ANALYSIS
WANT:
· HIGH PRECISION ON ESTIMATES OF b’s
· LOW CORRELATION AMONG ESTIMATES OF b’s
IMPLIES NEED FOR:
· GOOD “BALANCE" (SPREAD) ON x's
· HIGH DEGREE OF ORTHOGONALITY (LOW CORRELATION) AMONG x's
![]()
2. PROBLEMS IN DESIGN OF AN ANALYTICAL SURVEY
WANT:
· BALANCE ON A LARGE NUMBER OF VARIABLES
· ORTHOGONALITY (OR LOW CORRELATION) AMONG LARGE NUMBER OF VARIABLES
IN ADDITION, CONSTRAINTS ON:
· COST
· PRECISION (SAMPLE SIZE)
· STRATIFICATION AND OTHER DESIGN CONSTRAINTS (E.G., CLUSTERS)
NOTE: ATTENTION CENTERS ON INDEPENDENT VARIABLES
· IN DESCRIPTIVE SURVEY, TRY TO STRATIFY ON PREMEASURE OF DEPENDENT VARIABLES
· IN ANALYTICAL SURVEY, TRY TO STRATIFY ON PREMEASURE OF INDEPENDENT VARIABLES
NOTES ON DETERMINING SAMPLE SIZE IN ANALYTICAL SURVEYS:
REGRESSION COEFFICIENTS ARE SIMILAR TO DIFFERENCES. DETERMINE THE SAMPLE SIZE REQUIRED TO ACHIEVE A SPECIFIED LEVEL OF PRECISION FOR A DIFFERENCE (OR POWER FOR A TEST INVOLVING A DIFFERENCE), USING THE SAMPLE-SIZE PROGRAM CITED EARLIER (POSTED AT INTERNET LOCATION http://www.foundationwebsite.org/SampleSize.exe ).
NOTE THAT THE STANDARD METHOD OF ESTIMATING SAMPLE SIZE FOR ANALYTICAL SURVEYS IS TO DETERMINE THE SAMPLE SIZE THAT PROVIDES A SPECIFIED LEVEL OF POWER FOR TESTS OF HYPOTHESIS ABOUT DIFFERENCES (E.G., ABOUT THE SIZE OF A DOUBLE-DIFFERENCE ESTIMATE OF PROGRAM IMPACT), RATHER THAN THE APPROACH (FOR DESCRIPTIVE SURVEYS) OF DETERMINING THE SAMPLE SIZE THAT PROVIDES A SPECIFIED LEVEL OF PRECISION FOR AN ESTIMATE (SUCH AS A MEAN OR TOTAL). THAT APPROACH (“POWER ANALYSIS”) IS NOT DESCRIBED IN THIS COURSE, BUT IS DESCRIBED IN THE CITED PROGRAM, AND ALSO IN THE ARTICLE “SAMPLE SURVEY DESIGN FOR EVALUATION,” POSTED AT http://www.foundationwebsite.org/SampleSurveyDesignForEvaluation.pdf .
PROGRAM EVALUATIONS OFTEN INVOLVE THE USE OF ANALYTICAL SURVEYS TO DETERMINE DOUBLE-DIFFERENCE (“DIFFERENCE-IN-DIFFERENCE”) ESTIMATES OF PROGRAM IMPACT, IN A PRETEST-POSTTEST-WITH-COMPARISON-GROUP DESIGN. (IN STATISTICAL TERMINOLOGY, THE DOUBLE-DIFFERENCE ESTIMATE IS THE INTERACTION EFFECT OF TREATMENT AND TIME.) THE CITED PROGRAM CAN DETERMINE SAMPLE SIZES EXPLICITLY FOR THIS TYPE OF DESIGN. (IT USES THE DEFF TO REPRESENT THE DESIGN EFFECT OF ALL FACTORS OTHER THAN THE PRETEST-POSTTEST-WITH-COMPARISON-GROUP STRUCTURE (SUCH AS STRATIFICATION AND MULTISTAGE SAMPLING).)
IF THE DESIGN IS HIGHLY STRUCTURED, THE FORM OF THE IMPACT ESTIMATE WILL BE SIMPLE (E.G., A DOUBLE DIFFERENCE)
IF THE DESIGN IS NOT HIGHLY STRUCTURED, A “GENERALIZED REGRESSION” (“GREG”) ESTIMATOR WILL BE USED (SEE SHARON L. LOHR, SAMPLING: DESIGN AND ANALYSIS 2ND ED., (CENGAGE LEARNING, 2009) FOR DISCUSSION), BY SUBSTITUTING MEAN VALUES OF THE EXPLANATORY VARIABLES IN A REGRESSION MODEL THAT RELATES IMPACT TO EXPLANATORY VARIABLES.
THE PROBLEM OF DETERMINING SAMPLE SIZES FOR COMPLEX SURVEYS IS NOT SIMPLE OR EASY, AND THE PROBLEM OF DETERMINING SAMPLE SIZES FOR ANALYTICAL SURVEYS IS EVEN MORE COMPLICATED AND DIFFICULT. REFER TO THE ARTICLE “SAMPLE SURVEY DESIGN FOR EVALUATION” FOR MORE INFORMATION ON THIS TOPIC, AT http://www.foundationwebsite.org/SampleSurveyDesignForEvaluation.pdf . THE SAMPLE-SIZE ESTIMATION SHOULD BE MATCHED TO THE SURVEY DESIGN, EITHER EXPLICITLY (AS IN THE CASE OF THE PRETEST-POSTTEST-WITH-COMPARISON-GROUP DESIGN TREATED IN THE CITED SAMPLE-SIZE PROGRAM) OR VIA THE DESIGN EFFECT, DEFF (OR A COMBINATION OF BOTH).
SIMPLE RANDOM SAMPLING IS NOT EFFICIENT FOR ESTIMATING REGRESSION-MODEL PARAMETERS OR DIFFERENCES. WITH A SIMPLE RANDOM SAMPLE, THE VARIANCE OF AN ESTIMATED DIFFERENCE BETWEEN TWO SAMPLE HALVES IS FOUR TIMES THE VARIANCE OF THE ESTIMATED MEAN, AND THE VARIANCE OF A DOUBLE DIFFERENCE INVOLVING FOUR EQUAL GROUPS IS 16 TIMES AS LARGE. THESE NUMBERS LEAD TO VERY LARGE SAMPLE SIZES. THE SAMPLE SIZE IS REDUCED TO REASONABLE LEVELS BY TWO METHODS: (1) INTRODUCTION OF CORRELATIONS INTO THE SAMPLE BY MEANS OF MATCHING (PAIRED COMPARISONS BETWEEN TREATMENT AND CONTROL UNITS) AND PANEL SAMPLING (REINTERVIEW OF THE SAME UNITS AT TIME 2); AND (2) THE USE OF POWER ANALYSIS TO DETERMINE SAMPLE SIZES (I.E., DETERMINING THE SAMPLE SIZE THAT DETECTS A SPECIFIED DIFFERENCE IN IMPACT WITH A SPECIFIED PROBABILITY (POWER)). THESE METHODS ARE DISCUSSED IN THE CITED ARTICLE.
3. TWO CONCEPTUAL APPROACHES TO DESIGN OF ANALYTICAL SURVEYS
OBJECTIVE-FUNCTION APPROACH (AS FOR THE NEYMAN ALLOCATION TO STRATA):
O.F. = LINEAR COMBINATION OF VARIANCES OF ESTIMATES OF
INTEREST
SELECT DESIGN TO MINIMIZE OBJECTIVE FUNCTION
CONSTRAINT-DRIVEN APPROACH:
SELECT DESIGN TO MEET A VARIETY OF CONSTRAINTS (CONSTRAINED OPTIMIZATION WITH NUMEROUS CONSTRAINTS)
OBJECTIVE FUNCTION APPROACH HAS NOT PROVED TO BE PRODUCTIVE
(CAN'T DETERMINE SUITABLE SCALAR UTILITY FUNCTION)
CONSTRAINT-DRIVEN APPROACH IS FEASIBLE
4. METHODS FOR DESIGNING ANALYTICAL SURVEYS
FOR “SMALL PROBLEMS” (FEW EXPLANATORY VARIABLES, SUCH AS AN EXPERIMENTAL DESIGN):
1. CROSS STRATIFICATION
2. MARGINAL STRATIFICATION
3. CONTROLLED SELECTION (GOODMAN, KISH)
4. EXPERIMENTAL DESIGN AND QUASI-EXPERIMENTAL DESIGNS
FOR LARGE PROBLEMS (MANY EXPLANATORY VARIABLES, SUCH AS A QUASI-EXPERIMENTAL DESIGN WITH MANY COVARIATES):
5. A GENERAL METHODOLOGY FOR DESIGNING ANALYTICAL SURVEYS (SETTING OF VARIABLE SELECTION PROBABILITIES TO OBTAIN DESIRED EXPECTED STRATUM ALLOCATIONS)
8.12 Illustration of Methods for the Design of Analytical Surveys
III. ILLUSTRATION OF METHODS FOR THE DESIGN OF ANALYTICAL SURVEYS
1. CROSS STRATIFICATION
CASE 1. CELL-BY-CELL STRATIFICATION (CROSS-STRATIFICATION)
SAMPLE SIZE EXCEEDS NUMBER OF CELLS
|
n1 |
n2 |
|||
ORDINARY STRATIFIED DESIGN
CASE 2. MARGINAL STRATIFICATION
NUMBER OF CELLS EXCEEDS SAMPLE SIZE; SAMPLE SIZE EXCEEDS EVERY NUMBER OF MARGINAL CATEGORIES
|
1 |
2 |
||||||
|
1 |
2 |
3 |
1 |
2 |
3 |
||
|
1 |
4 |
||||||
|
2 |
2 |
||||||
|
3 |
4 |
||||||
|
2 |
1 |
2 |
2 |
1 |
2 |
n=10 |
|
R = 6
C = 3
n = 10
(R x C = 18)
ROW AND COLUMN TOTALS ARE FIXED
CELLS ARE RANDOMLY SELECTED TO SATISFY THESE CONSTRAINTS
PROCEDURE:
|
x |
4 |
|||||||||
|
x |
||||||||||
|
x |
||||||||||
|
x |
||||||||||
|
x |
2 |
|||||||||
|
x |
||||||||||
|
x |
4 |
|||||||||
|
x |
||||||||||
|
x |
||||||||||
|
x |
||||||||||
|
2 |
1 |
2 |
2 |
1 |
2 |
10 |
||||
RANDOM PERMUTATION OF n=10
|
x |
x |
x |
x |
4 |
||
|
x |
x |
2 |
||||
|
x |
xx |
x |
4 |
|||
|
2 |
1 |
2 |
2 |
1 |
2 |
10 |
PROBLEM: LOW ORTHOGONALITY. PROCEDURE BETTER SUITED FOR DESCRIPTIVE SURVEYS, WHERE ORTHOGONALITY IS NOT AN ISSUE.
2. CONTROLLED SELECTION (CONTROLS BEYOND STRATIFICATION)
3 x 3 x 2 x 2 x 2 = 72 CELLS
SAMPLE SIZE (E.G., SMSAs) = 40
SOME CELLS HAVE NO POPULATION MEMBERS
PLACE FIVE SAMPLE PATTERNS OF 40 ON THE GRID, SO THAT THE MARGINAL AND CROSSTAB CONSTRAINTS ARE GENERALLY SATISFIED (BALANCE + ORTHOGONALITY), SO THAT ALL NONEMPTY CELLS ARE COVERED AT LEAST ONCE (TO ALLOW FOR ESTIMATION OF MEANS AND TOTALS), SO THAT THE PROBABILITY OF SELECTION OF INDIVIDUAL ELEMENTS IS AS EVEN AS POSSIBLE (TO ALLOW FOR PRECISE ESTIMATION OF MEANS AND TOTALS), WITH THE MORE DESIRABLE PATTERNS HAVING HIGHER PROBABILITIES OF SELECTION, SELECT ONE OF THE FIVE SAMPLES (PROBABILITY SAMPLE).
3. CONTROLLED SELECTION – SIMPLER EXAMPLE
|
1 |
2 |
|||||
|
1 |
2 |
3 |
1 |
2 |
3 |
|
|
1 |
* |
o |
xo |
x |
o |
x |
|
2 |
xo |
x |
* |
o |
x |
* |
|
3 |
xo |
o |
x |
xo |
o |
x |
TWO PATTERNS, DESIGNATED BY x AND o. ASTERISK (*) DENOTES NO POPULATION.
PATTERN x (MORE DESIRABLE): Prob = .6
PATTERN o (LESS DESIRABLE): Prob = .4
Prob = 1.0
ALL CELLS COVERED (EVERY POPULATION ELEMENT HAS A NONZERO PROBABILITY OF SELECTION, AND THE PROBABILITIES OF SELECTION ARE KNOWN – THE BASIC REQUIREMENT FOR A PROBABILITY SAMPLE).
NOTE: THIS EXAMPLE DOESN’T CONSIDER THE SIZE OF THE POPULATION IN EACH CELL, I.E., ADJUSTMENT OF THE PATTERNS TO MAINTAIN REASONABLY BALANCED PROBABILITIES.
CONTROLLED SELECTION -- ADVANTAGES AND DISADVANTAGES
ADVANTAGES:
· THE SAMPLE IS GUARANTEED TO BE "GOOD" FROM AN ANALYTICAL VIEWPOINT (GOOD BALANCE, HIGH LEVEL OF ORTHOGONALITY)
DISADVANTAGES:
· DIFFICULT TO APPLY (DETERMINING "PREFERRED" PATTERNS, THAT MEET CONTROLS)
· CORRELATED SAMPLE - MUST USE RESAMPLING METHODS TO COMPUTE VARIANCE ESTIMATES
4. EXPERIMENTAL DESIGNS AND QUASI-EXPERIMENTAL DESIGNS
SIMPLE “BLOCK” DESIGNS (ONE TREATMENT VARIABLE)
FACTORIAL DESIGNS (SEVERAL TREATMENT VARIABLES)
QUASI-EXPERIMENTAL DESIGNS (E.G., PRETEST / POSTTEST / COMPARISON-GROUP DESIGN WITH NUMEROUS COVARIATES)
5. A GENERAL METHODOLOGY FOR DESIGNING ANALYTICAL SAMPLE SURVEYS, WHEN THE NUMBER OF EXPLANATORY VARIABLES IS LARGE: EXPECTED MARGINAL STRATIFICATION USING VARIABLE SELECTION PROBABILITIES – OVERVIEW
- ESTIMATE THE TOTAL SAMPLE SIZE, BASED ON POWER CALCULATIONS FOR AN ASSUMED DESIGN (E.G., A PRETEST / POSTTEST / COMPARISON-GROUP DESIGN). (USE THE SAMPLE-SIZE PROGRAM CITED EARLIER; THE SAMPLE SIZE USUALLY REFERS TO THE NUMBER OF FIRST-STAGE UNITS. THE SAMPLE SIZE FOR SUBUNITS WITHIN THE FIRST-STAGE UNITS DEPENDS ON THE INTRA-UNIT CORRELATION COEFFICIENT; IT IS OFTEN 15-30 FOR SURVEYS OF HOUSEHOLDS WITHIN CENSUS ENUMERATION UNITS OR VILLAGES.)
- SPECIFY A DESIRED MARGINAL STRATIFICATION FOR ALL INDEPENDENT VARIABLES AND ANTICIPATED INTERACTIONS
- SET THE UNIT SELECTION PROBABILITIES SUCH THAT THE EXPECTED STRATUM SAMPLE SIZES ARE CLOSE TO THE DESIRED VALUES.
- DO MATCHING, AS REQUIRED, TO IMPROVE THE PRECISION OF ESTIMATES OF DIFFERENCES (AND INCLUDE THE CORRELATIONS IN THE SAMPLE-SIZE ESTIMATE).
- SELECT A SAMPLE ACCORDING TO THE VARIABLE SELECTION PROBABILIITES (WHEN MATCHING IS USED, INCLUDE THE MATCHING ITEM(S) IN THE SAMPLE, FOR EACH UNIT SELECTED).
- SINCE THE DESIGN IS COMPLEX, USE RESAMPLING METHODS TO CALCULATE VARIANCES OF ESTIMATES.
6. A GENERAL METHODOLOGY FOR DESIGNING ANALYTICAL SURVEYS (EXPECTED MARGINAL STRATIFICATION USING VARIABLE SELECTION PROBABILITIES) – BRIEF SUMMARY (OMITS CONSIDERATION OF MATCHING)
NOTE: THERE IS NO STANDARD REFERENCE TEXT FOR THE FOLLOWING MATERIAL ON THE DESIGN OF ANALYTICAL SURVEYS. THIS MATERIAL WAS DEVELOPED BY THE COURSE DEVELOPER (J. G. CALDWELL) DURING THE COURSE OF HIS CONSULTING IN THIS FIELD (IN THE 1970s). FOR DETAILS, REFER TO THE ARTICLE, “SAMPLE SURVEY DESIGN FOR EVALUATION,” AT http://www.foundationwebsite.org/SampleSurveyDesignForEvaluation.pdf .
(1) FOR EACH SUBSTANTIVE ISSUE TO BE ADDRESSED IN THE SURVEY ANALYSIS, IDENTIFY ALL DEPENDENT AND INDEPENDENT VARIABLES.
- IN LARGE SURVEYS, MAY BE SEVERAL HUNDRED VARIABLES
- SEPARATE DEPENDENT AND INDEPENDENT VARIABLES
- SKETCH ANALYTICAL MODELS FOR EACH DEPENDENT VARIABLE (FUNCTIONAL FORM NOT IMPORTANT)
(2) FOR EACH UNIT OF THE SAMPLE FRAME, IDENTIFY PREMEASURES OF THE MAJOR INDEPENDENT VARIABLES OF INTEREST. (THE FOLLOWING STEPS REFER ONLY TO THESE VARIABLES.)
- MAY BE MANY VARIABLES (E.G., FROM PREVIOUS SURVEYS, FROM GOVERNMENT REPORTING SYSTEMS, FROM GEOGRAPHIC INFORMATION SYSTEMS)
- TRY TO INCLUDE AS MANY IMPORTANT CONCEPTS AS POSSIBLE
- EVEN A CRUDE MEASURE IS BETTER THAN NO MEASURE
(3) CONVERT ALL CONTINUOUS VARIABLES AND ORDINAL VARIABLES TO ORDERED CATEGORICAL VARIABLES. COMPUTE MARGINAL FREQUENCY COUNTS OF ALL VARIABLES. RANK ALL INDEPENDENT VARIABLES IN ORDER OF IMPORTANCE.
- TWO OR THREE CATEGORIES PER VARIABLE
- USE NATURAL BREAK POINTS OR QUANTILES (PERCENTILES)
- COMBINE SIMILAR CATEGORIES INTO SINGLE CATEGORY
- COMPUTE MARGINAL FREQUENCY COUNTS FOR ALL VARIABLES
- RANK ALL VARIABLES IN ORDER OF IMPORTANCE (WILL HAVE TO MAKE COMPROMISES LATER)
- MOTIVATION: WANT TO ASSURE BALANCE ON ALL IMPORTANT VARIABLES
(4) CALCULATE CRAMER (NONPARAMETRIC) CORRELATION MATRIX OF ALL (CATEGORICAL) VARIABLES. IDENTIFY SETS OF CORRELATED VARIABLES (“EYEBALL,” NOT FACTOR ANALYSIS).
- MOTIVATION: WANT TO ASSURE HIGH LEVEL OF ORTHOGONALITY FOR VARIABLES IN A REGRESSION MODEL
- USE “EYEBALL” TO IDENTIFY SETS OF HIGHLY CORRELATED VARIABLES, NOT FACTOR ANALYSIS OR PRINCIPAL COMPONENTS ANALYSIS
- MOTIVATION: WITHIN EACH SET, NEED TO DECIDE WHETHER VARIABLES SHOULD BE ORTHOGONALIZED
(5) FOR EACH SET OF CORRELATED VARIABLES, DETERMINE WHETHER THEY REPRESENT A SIMILAR OR DIFFERENT CONCEPT, FROM THE POINT OF VIEW OF SUBSTANTIVE THEORY. FOR IMPORTANT VARIABLE PAIRS THAT ARE NOT CAUSALLY RELATED BUT HIGHLY CORRELATED, DEFINE PRODUCT VARIABLES (OR A CROSS-CLASSIFICATION). COMBINE OR DROP SIMILAR VARIABLES.
- IN REGRESSION ANALYSIS, WOULD COMBINE OR DROP SIMILAR VARIABLES. DON'T WANT TO ORTHOGONALIZE THESE VARIABLES. WANT TO COMBINE OR DROP THEM BEFORE CONSTRUCTING THE DESIGN, RATHER THAN LATER.
- IN REGRESSION ANALYSIS, WANT NON-CAUSALLY-RELATED VARIABLES TO HAVE LOW CORRELATIONS. WANT TO ORTHOGONALIZE THESE VARIABLES (TO THE EXTENT POSSIBLE).
- AFTER COMBINING OR DROPPING VARIABLES, WILL HAVE A MUCH SMALLER SET, E.G., 20 OR 30.
(6) FOR EACH OF THE RESULTANT VARIABLES (OR CROSS-CLASSIFICATION), SPECIFY A DESIRED ALLOCATION OF THE SAMPLE TO THE CATEGORIES (E.G., 50-50, 40-10-40).
- DECIDE ON DESIRED SAMPLE SIZE
- LOOK AT ACTUAL FREQUENCY COUNTS TO SEE WHAT ALLOCATIONS ARE POSSIBLE.
(7) SET THE UNIT SELECTION PROBABILITIES SUCH THAT THE EXPECTED SAMPLE SIZE FOR EACH CATEGORY IS CLOSE TO THE DESIRED SAMPLE SIZE FOR THE CATEGORY.
- CONSTRAINTS WILL GENERALLY BE INCONSISTENT
- USE IMPORTANCE ORDERING OF DEPENDENT VARIABLES TO RELAX CONSTRAINTS UNTIL FEASIBLE SOLUTION IS FOUND
- FOR LARGE PROBLEMS, USE COMPUTER OPTIMIZATION MODEL TO FIND FEASIBLE SOLUTION.
- FOR SMALL PROBLEMS, CAN DETERMINE A GOOD ALLOCATION BY HAND
- IN MOST APPLICATIONS, THERE WILL BE THE POSSIBILITY OF NUMEROUS EMPTY CELLS – NOT A PROBLEM.
- IN VIEW OF DESIRE TO ESTIMATE MEANS AND TOTALS, CONSTRAIN SOLUTION TO REPRESENT EACH CELL WITH SOME NONZERO PROBABILITY (SOME OF THE CATEGORIES MAY HAVE HAD ZERO DESIRE SAMPLE SIZES – THIS CHANGES THAT).
(8) SELECT A PROBABILITY SAMPLE FROM THE DESIGN
- SINCE THE DESIGN IS COMPLEX, USE RESAMPLING METHODS TO ESTIMATE VARIANCES
PART THREE. HOW TO ANALYZE SURVEY DATA
8.13 Standard Estimation Procedures for Descriptive Surveys
I. STANDARD ESTIMATION PROCEDURES FOR DESCRIPTIVE SURVEYS
A. SUMMARY OF PROCEDURES
1. PRELIMINARY ANALYSIS (LARGE DATA SETS)
DO THE FOLLOWING FOR THE ENTIRE SAMPLE AND FOR SUBPOPULATIONS OF INTEREST (E.G., BY STRATUM). THIS IS A STANDARD NONRESPONSE ANALYSIS AND “NONPARAMETRIC” SUMMARY OF THE SAMPLE DATA. (A “FIRST-CUT” LOOK AT THE SAMPLE DATA MAY IGNORE COMPLEXITIES OF THE SAMPLE DESIGN (AND TESTS OF SIGNIFICANCE), AND SIMPLY PRESENT ESTIMATES OF CHARACTERISTICS OF THE SAMPLE.)
UNIVARIATE ANALYSIS:
- UNIT (QUESTIONAIRE) NONRESPONSE. CALCULATE PROPORTION OF SAMPLE UNITS RESPONDING. CATEGORIZE BY REASON. NOTE VARIABLES CORRELATED WITH NONRESPONSE.
- ITEM NONRESPONSE. DEFINE A NO-RESPONSE INDICATOR VARIABLE FOR EACH VARIABLE. NOTE VARIABLES HAVING HIGH LEVEL OF NONRESPONSE, AND VARIABLES CORRELATED WITH NONRESPONSE.
- FOR INTERVAL-SCALE VARIABLES, COMPUTE MEAN OR PERCENTAGE, MEDIAN, MIN, MAX, RANGE, VARIANCE, STANDARD DEVIATION, HISTOGRAM.
- FOR CATEGORICAL VARIABLES COMPUTE MIN, MAX, RANGE AND HISTOGRAM.
- FOR GEOGRAPHIC DATA, PLOT ALL SAMPLE UNITS ON A MAP.
BIVARIATE ANALYSIS:
- RECODE ALL INTERVAL-SCALE VARIABLES BY QUINTILE
- RECODE ALL CATEGORICAL VARIABLES HAVING MORE THAN 10 CATEGORIES INTO TEN OR LESS CATEGORIES (PREFERABLY 5 OR LESS). DEFINE INDICATOR VARIABLES FOR HIGH-INTEREST CATEGORIES.
- CALCULATE CRAMER COEFFICIENT OF ASSOCIATION FOR ALL VARIABLES (I.E., EACH VARIABLE WITH EACH OTHER). NOTE STRONG CORRELATIONS.
- CONSTRUCT TABLES OR GRAPHS (SCATTER PLOTS, LOESS / LOWESS (LOCALLY WEIGHTED SCATTERPLOT SMOOTHING) CURVES) TO ILLUSTRATE STRONG RELATIONSHIPS.
2. PLANNED ANALYSIS
- FOR TOTAL POPULATION AND SUBPOPULATIONS OF INTEREST, SUMMARIZE NONRESPONSE PATTERNS
- ADJUST SAMPLE WEIGHTS FOR NONRESPONSE
- CALCULATE ESTIMATES INTEREST (USE APPROPRIATE FORMULAS OR PROCEDURES)
- CROSSTABS OF INTEREST (BY STRATUM OR WEIGHTED)
- COMPUTE EXPANSION ESTIMATES
- CONDUCT TESTS OF SIGNIFICANCE
3. SPECIAL ANALYSES
- ALTERNATIVE ESTIMATORS (RATIO, REGRESSION)
- POSTSTRATIFICATION
- ADDITIONAL SUBPOPULATIONS
- REDEFINE NONRESPONSE STRATA, RECOMPUTE ESTIMATES
- RESAMPLING ESTIMATES OF VARIANCES
- TABLES OF GENERALIZED VARIANCES
 (CHI-SQUARED)
TESTS FOR CLUSTER-SAMPLE CROSSTABS
(CHI-SQUARED)
TESTS FOR CLUSTER-SAMPLE CROSSTABS
B. STANDARD ESTIMATION PROCEDURES FOR DESCRIPTIVE STATISTICS – DETAILS
ESTIMATION
EXPANSION MULTIPLIERS FOR MEANS, TOTALS AND OTHER STATISTICS FOR SIMPLE RANDOM SAMPLING AND STRATIFIED SAMPLING, PPS SAMPLING.
POST-STRATIFICATION FOR INCREASING EFFICIENCY.
STRATIFIED SAMPLING:
ESTIMATED TOTALS:
![]()
ESTIMATED MEANS:
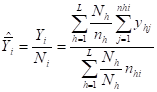
ALTERNATIVE ESTIMATES USING AUXILIARY INFORMATION
· RATIO OR REGRESSION ESTIMATES
· COMBINED RATIO ESTIMATES
VARIANCE ESTIMATION
· FOR SIMPLE DESIGNS, EXACT FORMULAS ARE AVAILABLE AND EASY TO COMPUTE
VARIOUS SHORT-CUT METHODS FOR ESTIMATING VARIANCES IN
COMPLEX SURVEYS
1. THE METHOD OF RANDOM GROUPS (REPLICATION) (INTERPENETRATING SAMPLES)
TWO OR MORE SAMPLES FROM THE SAME POPULATION. THESE SAMPLES MAY BE INDEPENDENT OR NOT. THE SAMPLING VARIANCE IS COMPUTED FROM THESE TWO OR MORE ESTIMATES
2. RESAMPLING METHODS: THE JACKKNIFE, BOOTSTRAP AND BALANCED REPEATED REPLICATION (BRR)
E.G., THE METHOD OF BALANCED HALF-SAMPLES:
FOR K STRATA THERE ARE 2K REPLICATES, A SAMPLE OF
L BALANCED REPLICATES SELECTED WITHOUT REPLACEMENT,
L < <2K.
4, GENERALIZED VARIANCE FUNCTIONS (GAT CURVES)
THE VARIANCE OR RELATIVE VARIANCE OF THE ESTIMATE IS ALGEBRAICALLY RELATED TO THE VALUE OF THE ESTIMATE.
SIMPLE ALGEBRAIC MODELS SUCH AS THE FOLLOWING ARE USED.
![]()
5. LINEARIZATION (TAYLOR-SERIES APPROXIMATION)
EXACT ALGEBRAIC EXPRESSIONS FOR THE SAMPLING VARIANCES FOR NONLINEAR ESTIMATORS (RATIO ESTIMATOR, REGRESSION ESTIMATOR, ETC.) ARE USUALLY NOT AVAILABLE. LINEAR FUNCTIONS OF OBSERVATIONS ARE EMPLOYED TO ESTIMATE APPROXIMATELY THE SAMPLING VARIANCE.
DOMAINS OF STUDY (SUBPOPULATIONS)
NOTATION (FROM COCHRAN, SAMPLING TECHNIQUES):
POPULATION SIZE N, SAMPLE SIZE n.
THE j-th DOMAIN CONTAINS Nj UNITS.
SAMPLE OF SIZE nj, OBSERVATIONS yjk, k=1,2,…,nj
SIMPLE RANDOM SAMPLING
ESTIMATED MEAN (FOR DOMAIN j):
![]()
ESTIMATED STANDARD ERROR OF THE ESTIMATED MEAN:
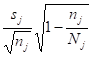 (USE
(USE ![]() if
if ![]() IS NOT
KNOWN)
IS NOT
KNOWN)
WHERE
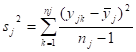
ESTIMATED TOTAL (FOR DOMAIN j):
![]()
(![]() USUALLY
WON’T WORK SINCE
USUALLY
WON’T WORK SINCE ![]() IS
USUALLY NOT KNOWN.)
IS
USUALLY NOT KNOWN.)
ESTIMATED STANDARD ERROR OF THE ESTIMATED TOTAL:
![]()
WHERE
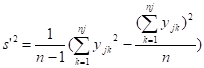
NOTE THAT IN THE ESTIMATED VARIANCES FOR THE TOTAL, THE DIVISORS INVOLVE n, NOT nj. THIS IS BECAUSE THE EXPANSION FACTOR IS N/n, NOT Nj/nj. HENCE, THE SAMPLE IS REGARDED AS A SAMPLE OF SIZE n IN WHICH nj UNITS (OF THE j-th DOMAIN HAVE VALUES yjk and n – nj HAVE VALUE ZERO.
C. ALTERNATIVE ESTIMATION PROCEDURES
1. SYNTHETIC ESTIMATES
UNBIASED ESTIMATE FROM A LARGE AREA
WANT ESTIMATE FOR A SMALL AREA
USE LARGE-AREA INFORMATION TO OBTAIN SMALL-AREA ESTIMATE
CASE 1. USE MEAN OF LARGE AREA FOR SMALL AREA
CASE 2. ESTIMATE, FROM LARGE AREA, THE VALUE FOR VARIOUS SUBPOPULATIONS (STRATA), FOR WHICH COUNTS ARE KNOWN FOR THE SMALL AREA. FORM A WEIGHTED AVERAGE FOR THE SMALL AREA.
EXAMPLE:
FOR THE LARGE AREA, IT IS KNOWN THAT:
WHITES: MEAN = 7
BLACKS: MEAN = 9
FOR THE SMALL AREA, IT IS KNOWN THAT:
WHITES = 60% (OF THE POPULATION OF THE SMALL AREA)
BLACKS = 40%.
THE SYNTHETIC ESTIMATE OF THE MEAN FOR THE SMALL AREA IS THE WEIGHTED AVERAGE OF THE MEANS FROM THE LARGE AREA, USING THE POPULATION PROPORTIONS FOR THE SMALL AREA: .6(7) + .4(9) = 7.8
2. RAKING
FROM A NEW SURVEY, ESTIMATE A CROSSTABULATION.
MAY KNOW MARGINAL TOTALS FROM A BETTER SOURCE (E.G., A CENSUS).
“RAKING” IS A PROCEDURE FOR ADJUSTING THE CROSSTAB TO MATCH THE MARGINALS (LEAST SQUARES PROCEDURE)
ITERATIVE PROCEDURE; SLOW IN MULTIVARIATE CASE.
8.14 Standard Estimation Procedures for Analytical Surveys
II. STANDARD ESTIMATION PROCEDURES FOR ANALYTICAL SURVEYS
1. PRELIMINARY ANALYSIS -- SAME AS FOR DESCRIPTIVE SURVEY
2. PLANNED ANALYSIS
· MODEL SPECIFICATION
o IF WELL-SPECIFIED, DON'T NEED TO USE WEIGHTS
o IF NOT SURE -- USE WEIGHTS
· CHOOSE BETWEEN SEPARATE VS, POOLED REGRESSIONS (WITH INTERACTION TERMS)
· DRAW SUBSAMPLES FOR PRELIMINARY ANALYSIS
· IMPUTE MISSING VALUES
o BY REGRESSION
o BY “HOT DECK” (CONDITIONED ON APPROPRIATE VARIABLES)
· REVISE WEIGHTS TO ACCOUNT FOR NONRESPONSE
· TRANSFORM VARIABLES (E.G., LOGISTIC MODEL)
· STORE CROSSPRODUCTS MATRIX
· RUN PRELIMINARY REGRESSIONS (ON STORED MATRIX)
· REDUCE MULTICOLLINEARITY (LOOK AT CORRELATIONS BETWEEN ESTIMATED COEFFICIENTS)
o DROP VARIABLES
o TRANSFORM VARIABLES
o USE FACTOR ANALYSIS AS LAST RESORT
· ELIMINATE INSIGNIFICANT VARIABLES BY DROPPING OR COMBINING
3. REVISE MODEL
· TESTS OF MODEL ADEQUACY
o PLOTS OF RESIDUALS
o REGRESSIONS ON DIFFERENT SUBPOPULATIONS
o SUBSTANTIVE CHECKS (ON COEFFICIENTS)
o IF MODEL USED FOR PREDICTION, CHECK ACCURACY WITH HISTORICAL DATA
· RESPECIFICATION OF MODEL / REESTIMATION OF COEFFICIENTS
· RUN MODEL WITH AND WITHOUT WEIGHTS, NOTE DIFFERENCES
4. TESTS OF SIGNIFICANCE
· USE ORDINARY LEAST SQUARES (OLS) FOR BULK OF ANALYSIS
o INFINITE POPULATION
o CORRECTLY SPECIFIED MODEL
· FOR ROUGH TESTS OF SIGNIFICANCE, USE "EFFECTIVE" SAMPLE SIZE (TAKING INTO ACCOUNT DESIGN EFFECT)
· USE RESAMPLING TO ESTIMATE VARIANCES
· USE PRINCIPLE OF CONDITIONAL ERROR TO TEST HYPOTHESES ABOUT VARIABLES (WITH JUDGMENT)
· GENERAL LINEAR MODEL CAN HANDLE INTRACLUSTER CORRELATIONS
· CHI-SQUARED FOR CROSSTABS IN CLUSTER SAMPLE
· CAUTION: CAN'T MAKE CAUSAL INFERENCES (GUIDANCE FOR EXPERIMENTAL DESIGN)
8.15 Computer Programs for Analysis of Survey Data; Outline of Topics for Day 3
III. COMPUTER PROGRAMS FOR ANALYSIS OF SURVEY DATA;
OUTLINE OF TOPICS FOR DAY 3
1. COMPUTER PROGRAMS FOR ANALYSIS OF SURVEY DATA
· SURVEY DATA ENTRY PROGRAMS: EPI-INFO (CDC), CSPro (CENSUS)
· STATISTICAL ANALYSIS PROGRAM PACKAGES: STATA, SPSS, SAS, S, S-PLUS, R, ZELIG, STATISTICA
· MANY STATISTICAL-PACKAGE PROGRAMS ARE DESIGNED PRIMARILY FOR DESCRIPTIVE SURVEYS (FINITE POPULATION CORRECTION) OR SIMPLE RANDOM SAMPLING (E.G., MODEL-BASED APPROACH TO REGRESSION ANALYSIS), NOT FOR DESIGN-BASED ANALSYIS OF COMPLEX SURVEY DATA
· CAN USE WEIGHTS TO OBTAIN ESTIMATES, BUT NOT TESTS OF SIGNIFICANCE
· FOR DESCRIPTIVE SURVEYS, CAN USE THESE PROGRAMS FOR ESTIMATION OF MEANS, AND CROSSTABULATION FOR NONCLUSTER SAMPLING WITHIN A STRATUM
· FOR ANALYTICAL SURVEYS, CAN USE THESE PROGRAMS FOR ESTIMATION OF REGRESSION COEFFICIENTS IN NONCLUSTER SAMPLING. FOR CLUSTER SAMPLING, USE "EFFECTIVE" SAMPLE SIZE (VIA DEFF) FOR ROUGH TESTS OF SIGNIFICANCE, OR GENERALIZED LEAST SQUARES, OR SELECT SINGLE SAMPLE UNIT FROM EACH CLUSTER.
· SOME COMPUTER PROGRAMS PERFORM ESTIMATION TAKING INTO ACCOUNT THE SURVEY SAMPLE STRUCTURE, AND INCLUDE RESAMPLING METHODS FOR VARIANCE ESTIMATION
· EXAMPLES OF COMPUTER-PROGRAM PACKAGES DESIGNED TO ANALYZE SURVEY DATA FROM THE DESIGN-BASED APPROACH (FINITE-POPULATION APPROACH) INCLUDE: SUDAAN, OSIRIS, PC CARP, Wes VarPC, CENVAR, CLUSTERS, AND VPLX. (SEE SHARON L. LOHR’S SAMPLING: DESIGN AND ANALYSIS 2ND ED., (CENGAGE LEARNING, 2009), PP.313-315 FOR DISCUSSION OF STATISTICAL SOFTWARE.)
DAY 3: SPECIAL TOPICS / PRACTICAL PROBLEMS IN SURVEY DESIGN
SURVEY DESIGN FOR MONITORING AND EVALUATION
INSTRUMENTATION, DATA COLLECTION AND SURVEY FIELD PROCEDURES
PREPARATION OF OMB CLEARANCE FORMS
LONGITUDINAL SURVEYS
SAMPLE FRAME PROBLEMS
SAMPLING FOR RARE ELEMENTS
TREATMENT OF NONRESPONSE
NONSAMPLING ERRORS (RELIABILITY/VALIDITY)
RANDOMIZED RESPONSE
RANDOM DIGIT DIALING
MAJOR NATIONAL AND INTERNATIONAL SURVEYS
QUESTIONS AND ANSWERS
SEE STEVEN K. THOMPSON’S SAMPLING (3RD EDITION) FOR DISCUSSION OF OTHER DESIGN TOPICS (E.G., NETWORK SAMPLING, CAPTURE-RECAPTURE, LINE-INTERCEPT SAMPLING, SPATIAL SAMPLING / KRIGING, ADAPTIVE SAMPLING)
9. Day 3: Special Topics / Practical Problems in Survey Design
SAMPLE SURVEY DESIGN AND ANALYSIS:
A COMPREHENSIVE THREE-DAY COURSE
LECTURE NOTES
DAY THREE: SPECIAL TOPICS / PRACTICAL PROBLEMS IN SURVEY DESIGN
Joseph George Caldwell, PhD (Statistics)
1432 N Camino Mateo, Tucson, AZ 85745-3311 USA
Tel. (001)(520)222-3446, E-mail jcaldwell9@yahoo.com
Updated November 9, 2016
Copyright © 1980 - 2016 Joseph George Caldwell. All rights reserved.
DAY 3: SPECIAL TOPICS / PRACTICAL PROBLEMS IN SURVEY DESIGN
SURVEY DESIGN FOR MONITORING AND EVALUATION
INSTRUMENTATION, DATA COLLECTION, AND SURVEY FIELD PROCEDURES
PREPARATION OF OMB CLEARANCE FORMS
LONGITUDINAL SURVEYS
SAMPLE FRAME PROBLEMS
SAMPLING FOR RARE ELEMENTS
TREATMENT OF NONRESPONSE
NONSAMPLING ERRORS
RANDOMIZED RESPONSE
RANDOM DIGIT DIALING
MAJOR NATIONAL AND INTERNATIONAL SURVEYS
STATISTICAL SOFTWARE
SURVEY DOCUMENTATION
QUESTIONS AND ANSWERS
SPECIAL TOPICS ADDRESSED IN SEPARATE PRESENTATIONS INCLUDE:
DESIGN AND ANALYSIS OF ANALYTICAL SURVEYS
SMALL AREA STATISTICS
CAUSAL INFERENCE AND MATCHING
MISSING VALUES AND WEIGHTING
9.1 Survey Design for Monitoring and Evaluation
I. SURVEY DESIGN FOR MONITORING AND EVALUATION
SURVEY DESIGN AND ANALYSIS FOR MONITORING INVOLVES DESCRIPTIVE SURVEYS, AND IS ADDRESSED BY THIS PRESENTATION. SURVEY DESIGN AND ANALYSIS FOR EVALUATION INVOLVES ANALYTICAL SURVEYS, AND IS ADDRESSED IN OTHER PRESENTATIONS, WITH ONE EXCEPTION. IMPLEMENTATION OF AN EXPERIMENTAL DESIGN MAY BE DONE USING SAMPLE SURVEY FOR DATA COLLECTION. EXPERIMENTAL DESIGN DATA COLLECTED BY SAMPLE SURVEY INVOLVES DESIGN-BASED ESTIMATES, AND MAY BE ANALYZED USING THE METHODOLOGY PRESENTED IN THIS PRESENTATION.
1. CONCEPTS IN MONITORING AND EVALUATION
ORGANISATION FOR ECONOMIC COOPERATION AND DEVELOPMENT (OECD, GLOSSARY OF KEY TERMS IN EVALUATION AND RESULTS-BASED MANAGEMENT, 2002):
MONITORING IS A CONTINUOUS FUNCTION THAT USES THE SYSTEMATIC COLLECTION OF DATA ON SPECIFIED INDICATORS TO PROVIDE MANAGEMENT AND THE MAIN STAKEHOLDERS OF AN ONGOING DEVELOPMENT INTERVENTION WITH INDICATIONS OF THE EXTENT OF PROGRESS AND ACHIEVEMENT OF OBJECTIVES AND PROGRESS IN THE USE OF ALLOCATED FUNDS.
EVALUATION IS THE SYSTEMATIC AND OBJECTIVE ASSESSMENT OF AN ONGOING OR COMPLETED PROJECT, PROGRAM, OR POLICY, INCLUDING ITS DESIGN, IMPLEMENTATION, AND RESULTS. THE AIM IS TO DETERMINE THE RELEVANCE AND FULFILLMENT OF OBJECTIVES, DEVELOPMENT EFFICIENCY, EFFECTIVENESS, IMPACT, AND SUSTAINABILITY. AN EVALUATION SHOULD PROVIDE INFORMATION THAT IS CREDIBLE AND USEFUL, ENABLING THE INCORPORATION OF LESSONS LEARNED INTO THE DECISIONMAKING PROCESS OF BOTH RECIPIENTS AND DONORS.
OTHER TERMS FOR EVALUATION: EVALUATION RESEARCH, EVALUATIVE RESEARCH, EFFECTIVENESS EVALUATION, SUMMATIVE EVALUATION.
OTHER TERMS FOR MONITORING: PROCESS EVALUATION, FORMATIVE EVALUATION.
MONITORING FOCUSES ON DIRECT OUTPUTS; EVALUATION FOCUSES ON OUTCOMES AND IMPACTS (RESULTS RELATING TO ACHIEVEMENT OF THE ULTIMATE GOALS).
WHAT WAS ACCOMPLISHED, FOR WHAT GROUPS, BY WHAT MEANS, AT WHAT COST?
IMPORTANCE OF INDICATORS: “WHAT GETS MEASURED GETS DONE.”
MONITORING IS CONCERNED MAINLY WITH MEASUREMENTS OF INPUTS, ACTIVITIES AND OUTPUTS. EVALUATION IS CONCERNED WITH OUTCOMES AND IMPACTS. BOTH ARE CONCERNED WITH EFFICIENCY AND EFFECTIVENESS.
MAJOR TYPES OF EVALUATION STUDIES
· PROCESS EVALUATION (FORMATIVE EVALUATION; EFFICIENCY)
· OUTCOME EVALUATION
· IMPACT EVALUATION (SUMMATIVE EVALUATION; EFFECTIVENESS)
SAMPLE SURVEY IS ESSENTIAL TO BOTH MONITORING AND EVALUATION, E.G., THE DEVELOPMENT OF SAMPLING PLANS FOR MONITORING AGENCY OPERATIONS AND COMPLIANCE WITH STANDARDS, AND FORMAL INVESTIGATIONS OF PROJECT OR PROGRAM IMPACT.
SAMPLE SURVEY CAN SUPPORT BOTH MONITORING (DESCRIPTIVE SURVEY DESIGN, TO PRODUCE DESCRIPTIVE STATISTICS ON A POPULATION AND SUBPOPULATIONS OF INTEREST) AND EVALUATION (ANALTYICAL SURVEY DESIGN, TO DEVELOP MODELS OF A PROCESS AND TEST HYPOTHESES ABOUT IT (E.G., GENERAL LINEAR STATISTICAL MODELS SUCH AS EXPERIMENTAL DESIGNS, QUASI-EXPERIMENTAL DESIGNS AND MULTIPLE REGRESSION MODELS).
THIS PRESENTATION IS CONCERNED MAINLY WITH DESCRIPTIVE SURVEY DESIGN, AND CONTAINS A VERY LIMITED DISCUSSION OF ANALYTICAL SURVEY DESIGN. IT DOES NOT ADDRESS SITUATIONS IN WHICH "SELECTION EFFECTS" MAY CAUSE THE PROBABILITIES OF SELECTION TO DEPART FROM THE DESIGN VALUES. MATERIAL ON THE DESIGN AND ANALYSIS OF ANALYTICAL SURVEYS IS PRESENTED IN A SEPARATE PRESENTATION.
EVALUATION -- MEASURING HOW WELL A PROGRAM HAS ACHIEVED ITS OBJECTIVES, OR WHAT CHANGES HAVE TAKEN PLACE AS A RESULT OF THE PROGRAM.
CAROL H. WEISS (EVALUATING ACTION PROGRAMS, ALLYN & BACON, 1972):
- FINDING OUT THE GOALS OF A PROGRAM
- TRANSLATING THE GOALS INTO MEASURABLE INDICATORS OF GOAL ACHIEVEMENT
- COLLECTING DATA ON THE INDICATORS FOR THOSE WHO HAVE BEEN EXPOSED TO THE PROGRAM
- COLLECTING SIMILAR DATA ON AN EQUIVALENT GROUP THAT HAS NOT GEEN EXPOSED TO THE PROGRAM (CONTROL GROUP)
- COMPARING THE DATA ON PROGRAM PARTICIPANTS AND CONTROLS IN TERMS OF GOAL CRITERIA
JOSEPH S. WHOLEY (FEDERAL EVALUATION POLICY, URBAN INSTITUTE, 1975):
EVALUATION (1) ASSESSES THE EFFECTIVENESS OF AN ON-GOING PROGRAM IN ACHIEVING ITS OBJECTIVES, (2) RELIES ON THE PRINCIPLES OF RESEARCH DESIGN TO DISTINGUISH A PROGRAM’S EFFECTS FROM THOSE OF OTHER FORCES WORKING IN A SITUATION, AND (3) AIMS AT PROGRAM IMPROVEMENT THROUGH A MODIFICATION OF CURRENT OPERATIONS.
REFERENCES:
- RUBIN, ALLEN AND EARL BABBIE, RESEARCH METHODS FOR SOCIAL WORK, 3rd EDITION, BROOKS/COLE, 1997
- JODY ZALL KUSEK & RAY C. RIST, TEN STEPS TO A RESULTS-BASED MONITORING AND EVALUATION SYSTEM (WORLD BANK, 2004)
EXAMPLES FROM KUSEK/RIST:
MONITORING AND EVALUATION ARE CONCERNED WITH:
· GOALS (LONG-TERM, WIDESPREAD IMPROVEMENTS IN SOCIETY)
· OUTCOMES (INTERMEDIATE EFFECTS OF OUTPUTS ON CLIENTS)
· OUTPUTS (PRODUCTS AND SERVICES PRODUCED)
· ACTIVITIES (TASKS PERSONNEL UNDERTAKE TO TRANSFORM INPUTS TO OUTPUTS)
· INPUTS (FINANCIAL, HUMAN AND MATERIAL RESOURCES)
MILLENNIUM DEVELOPMENT GOALS:
- ERADICATE EXTREME PROVERTY AND HUNGER
- ACHIEVE UNIVERSAL PRIMARY EDUCATION
- PROMOTE GENDER EQUALITY AND EMPOWER WOMEN
- REDUCE CHILD MORTALITY
- IMPROVE MATERNAL HEALTH
- COMBAT HIV/AIDS, MALARIA AND OTHER DISEASES
- ENSURE ENVIRONMENTAL SUSTAINABILITY
- DEVELOP A GLOBAL PARTNERSHIP FOR DEVELOPMENT
EXAMPLE OF MILLENNIUM DEVELOPMENT GOAL, TARGETS AND INDICATORS
GOAL: ERADICATE EXTREME POVERTY AND HUNGER
· TARGET 1: HALVE, BETWEEN 1990 AND 2015, THE PROPORTION OF PEOPLE WHOSE INCOME IS LESS THAN USD1 PER DAY
o INDICATOR 1: PROPORTION OF POPULATION BELOW USD1 PER DAY
o INDICATOR 2: POVERTY GAP RATIO (INCIDENCE X DEPTH OF POVERTY)
o INDICATOR 3: SHARE OF POORTEST QUINTILE IN NATIONAL CONSUMPTION
· TARGET 2: HALVE, BETWEEN 1990 AND 2015, THE PROPORTION OF PEOPLE WHO SUFFER FROM HUNGER
o INDICATOR 4: PREVALENCE OF UNDERWEIGHT CHILDREN (UNDER 5 YEARS OF AGE)
o INDICATOR 5: PROPORTION OF POPULATION BELOW MINIMUM LEVEL OF DIETARY ENERGY CONSUMPTION
EXAMPLE OF INPUTS, ACTIVITIES, OUTPUTS, OUTCOME AND GOAL (KUSEK/RIST)
· GOAL: REDUCE MORTALITY RATES FOR CHILDREN UNDER 5 YEARS OLD
· OUTCOME: IMPROVE USE OF ORAL REHYDRATION THERAPY (ORT) FOR MANAGING CHILDHOOD DIARRHEA
· OUTPUTS:
o 15 MEDIA CAMPAIGNS COMPLETED
o 100 HEALTH PROFESSIONALS TRAINED
o INCREASED MATERNAL KNOWLEDGE OF ORT SERVICES
o INCREASED ACCESS TO ORT
· ACTIVITIES:
o LAUNCH MEDIA CAMPAIGN TO EDUCATE MOTHERS
o TRAIN HEALTH PROFESSIONALS IN ORT
· INPUTS:
o TRAINERS
o ORT SUPPLIES
o FUNDS
o PARTICIPANTS
TYPES OF EVALUATIONS (KUSEK/RIST, WORLD BANK’S MONITORING AND EVAUATION: SOME TOOLS, METHODS AND APPROACHES):
· PERFORMANCE LOGIC CHAIN ASSESSMENT
o DETERMINE THE STRENGTH AND LOGIC OF THE CAUSAL MODEL BEHIND THE POLCY, PROGRAM OR PROJECT
· PRE-IMPLEMENTATION ASSESSMENT
o ARE THE OBJECTIVES WELL-DEFINED SO THAT OUTCOMES CAN BE STATED IN MEASURABLE TERMS?
o IS THERE A COHERENT AND CREDIBLE IMPLEMENTATION PLAN THAT PROVIDES CLEAR EVIDENCE OFHOW IMPLEMENTATIONIS TO PROCEED AND HOW SUCCESSFUL IMPLEMENTATION CAN BE DISTINGUISHED FROM POOR IMPLEMENTATION?
o IS THE RATIONALE FOR THE DEPLOYMENT OF RESOURCES CLEAR AND COMMENSURATE WITH THE REQUIREMENTS FOR ACHIEVING THE STATED OUTCOMES?
· PROCESS IMPLEMENTATION ASSESSMENT
o FOCUSES ON IMPLEMENTATION DETAILS
o WHAT WAS PLANNED TO BE IMPLEMENTED
o WHAT GOT IMPLEMENTED
o COST AND TIME EXPENDITURES, PROBLEMS
· RAPID APPRAISAL
o KEY INFORMANT SURVEYS
o FOCUS GROUP INTERVIEWS
o COMMUNITY INTERVIEWS
o STRUCTURED DIRECT OBSERVATION
o SURVEYS
· CASE STUDY
o IN-DEPTH INVESTIGATION
· IMPACT EVALUTION
o “CLASSIC” EVALUATION: WHAT CHANGES OCCURRED, AND TO WHAT CAN THOSE CHANGES BE ATTRIBUTED
· META-EVALUATION
o SUMMARIZE PREVIOUS EVALUATIONS
· COST-BENEFIT ANALYSIS AND COST-EFFECTIVENESS ANALYSIS
o COST-BENEFIT ANALYSIS REQUIRES BOTH INPUTS AND OUTPUTS IN MONETARY TERMS (E.G., COST-BENEFIT ANALYSIS OF DAY CARE FROM CLIENT, GOVERNMENT AND SOCIETAL VIEWPOINTS)
o COST-EFECTIVENESS ANALYSIS ESTIMATES INPUTS IN MONETARY TERMS AND OUTCOMES IN NONMONETARY QUANTITATIVE TERMS (E.G., IMPROVEMENS IN STUDENTS’ READING SCORES)
o DETAILED FINANCIAL/ECONOMIC/OPTIMIZATION MODELS. LAGRANGE MULTIPLIERS / SHADOW VALUES / SHADOW PRICES
o HIGHLY TECHNICAL: SKILLS IN FINANCE, ECONOMICS, PUBLIC FINANCE, OPTIMIZATION THEORY
ESSENTIAL ACTIONS IN BUILDING AN M&E SYSTEM (KUSEK/RIST):
· FORMULATE OUTCOMES AND GOALS
· SELECT OUTCOME INDICATORS TO MONITOR
· GATHER BASELINE INFORMATION ON THE CURRENT SITUATION
· SET SPECIFIC TARGETS TO REACH, AND DATES FOR REACHING THEM
· REGULARLY COLLECT DATA TO ASSESS WHETHER THE TARGETS ARE BEING MET
· ANALYZE AND REPORT THE RESULTS
KUSEK/RIST 10 STEPS TO BUILDING A RESULTS-BASED M&E SYSTEM:
- CONDUCT A READINESS ASSESSMENT (EVALUABILITY ASSESSMENT)
- AGREE ON OUTCOMES TO MONITOR AND EVALUATE
- SELECT KEY INDICATORS TO MONITOR OUTCOMES
- COLLECT BASELINE DATA ON INDICATORS
- PLAN FOR IMPROVEMENT (SELECT RESULTS TARGETS)
- MONITOR RESULTS
- CONDUCT EVALUATIONS
- REPORT FINDINGS
- USE FINDINGS
- IMPLEMENT SUSTAINABLE M&E SYSTEM WITHIN THE ORGANIZATION
CONSISTENT WITH QUALITY MANAGEMENT STANDARDS (DEMING, ISO 9000 QUALITY MANAGEMENT, CMU SEI CMM).
QUESTIONS TO ADDRESS IN BUILDING BASELINE INFORMATION (KUSEK/RIST):
- WHAT ARE THE SOURCES OF DATA?
- WHAT ARE THE DATA COLLECTION METHODS?
- WHO WILL COLLECT THE DATA?
- HOW OFTEN WILL THE DATA BE COLLECTED?
- WHAT IS THE COST AND DIFFICULTY TO COLLECT THE DATA?
- WHO WILL ANALYZE THE DATA?
- WHO WILL REPORT THE DATA?
- WHO WILL USE THE DATA?
COMPARISON OF MAJOR DATA COLLECTION METHODS (KUSEK/RIST)
|
Data collection method |
||||
|
Characteristic |
Review of program records |
Self-administered questionnaire |
Interview |
Rating by trained observer |
|
Cost |
Low |
Moderate |
Moderate to high |
Depends on availability of low-cost observers |
|
Amount of training required for data collectors |
Some |
None to some |
Moderate to high |
Moderate to high |
|
Completion time |
Depends on amount of data needed |
Moderate |
Moderate |
Short to moderate |
|
Response rate |
High, if records contain needed data |
Depends on how distributed |
Generally good to moderate |
High |
HISTORICAL BACKGROUND ON MONITORING AND EVALUATION
MUCH WORK IN METHODOLOGIES FOR EVALUATION SINCE THE 1920s (STATISTICS, EXPERIMENTAL DESIGN, SAMPLE SURVEY, ECONOMETRICS).
HEAVY GOVERNMENT INTEREST AND INVESTMENT IN MONITORING AND EVALUATION SINCE THE 1960s. E.G., PLANNING-PROGRAMMING-BUDGETING (PPB, 1965). GENERAL ACCOUNTING OFFICE (GAO). OFFICE OF MANAGEMENT AND BUDGET (OMB).
US GOVERNMENT STANDARDS FOR ACCOUNTABLE MANAGEMENT IN ALL FEDERAL AGENCIES. EVALUATION OF ALL MAJOR SOCIAL AND ECONOMIC PROGRAMS SINCE THE 1960S, WITH THE RENEWED ADVENT OF MASSIVE SOCIAL AND ECONOMIC PROGRAMS, SUCH AS THE “WAR ON POVETY”:
· MATERNAL AND CHILD HEALTH
· VOCATIONAL EDUCATION
· ELEMENTARY AND SECONDARY EDUCATION
· MODEL CITIES
· URBAN RENEWAL
· MANPOWER DEVELOPMENT AND TRAINING
· NEIGHBORHOOD YOUTH CORPS
· WORK INCENTIVE PROGAM
· HEAD START
· JOB CORPS
FOREIGN ASSISTANCE ACT OF 1961 (AS AMENDED). FORMAL EVALUATION REQUIRED FOR ALL MAJOR US FOREIGN ASSISTANCE PROJECTS
MUCH RESEARCH AND MANY PUBLICATIONS ON MONITORING AND EVALUATION SINCE THE 1960s.
EVALUATION GUIDELINES: A.I.D. EVALUATION HANDBOOK
RENEWED INTEREST IN MONITORING AND EVALUATION OF US FEDERAL AGENCIES: THE GOVERNMENT PERFOMANCE AND RESULTS ACT OF 1993 (GPRA) HOLDS FEDERAL AGENCIES ACCOUNTABLE FOR USING RESOURCES WISELY AND ACHIEVING PROGRAM RESULTS.
THE GOVERNMENT PERFORMANCE AND RESULTS ACT OF 1993
.
GPRA IS NOT LONG (11 PAGES). MAY BE VIEWED AT http://www.whitehouse.gov/omb/mgmt-gpra/gplaw2m.html .
UNDER GPRA, US FEDERAL AGENCIES (HAVING ANNUAL BUDGETS OVER USD20M) MUST:
· DEVELOP PLANS FOR WHAT THEY INTEND TO ACCOMPLISH
· MEASURE HOW WELL THEY ARE DOING
· MAKE APPROPRIATE DECISIONS BASED ON THE INFORMATION THEY HAVE GATHERED
· AND COMMUNICATE INFORMATION ABOUT THEIR PERFORMANCE TO CONGRESS AND THE PUBLIC
GPRA REQUIREMENTS:
· A LONG-RANGE (5-YEAR) STRATEGIC PLAN, WHICH INCLUDES A MISSION STATEMENT, LONG-TERM GOALS AND OBJECTIVES
· ANNUAL PERFORMANCE PLANS, WHICH PROVIDE ANNUAL PERFORMANCE COMMITMENTS TOWARD ACHIEVING THE GOALS AND OBJECTIVES PRESENTED IN THE STRATEGIC PLAN
· ANNUAL PERFORMANCE REPORTS, WHICH EVALUATE AN AGENCY’S PROGRESS TOWARD ACHIEVING PERFORMANCE COMMITMENTS
THE GPRA REQUIREMENTS FORGE LINKS BETWEEN SEVERAL ACTIVITIES:
· PLANNING, TO ACHIEVE GOALS AND OBJECTIVES
· BUDGETING, TO ENSURE THAT RESOURES ARE AVAILABLE TO CARRY OUT PLANS
· MEASURING, TO ASSESS PROGRESS AND LINK RESOURCES ACTUALLY USED TO RESULTS ACHIEVED
· REPORTING, TO PRESENT PROGRESS ACHIEVED AND IMPACTS ON FUTURE EFFORTS
GPRA WAS INITIATED WITH 10 PILOT PROJECTS IN 1994-96. FIVE AGENCIES SELECTED AS PILOT PROJECTS FOR PERFORMANCE BUDGETING FOR FISCAL YEARS 1998 AND 1999.
A PERFORMANCE BUDGET PRESENTS, FOR ONE OR MORE OF THE MAJOR FUNCTIONS AND OPERATIONS OF THE AGENCY, THE VARYING LEVELS OF PERFORMANCE, INCLUDING OUTCOME-RELATED PERFORMANCE, THAT WOULD RESULT FROM DIFFERENT BUDGETED AMOUNTS.
EXAMPLES OF GPRA ACTIVITIES ON THE INTERNET, E.G., US ENVIRONMENTAL PROTECTION AGENCY (EPA) AT http://www.epa.gov/ocfo/plan/plan.htm .
RECENT INCREASES OF INTEREST IN MONITORING AND EVALUATION BY INTERNATIONAL DEVELOPMENT AND ASSISTANCE AGENCIES
IN RECENT YEARS, INTERNATIONAL ORGANIZATIONS SUCH AS THE UNITED NATIONS, THE WORLD BANK, AND THE RED CROSS HAVE INVESTED HEAVILY IN MONITORING AND EVALUATION. IT IS NOW A MAJOR COMPONENT OF ALL PROGRAMS, AND PROJECTS OF SIGNIFICANT SIZE.
MUCH MORE EMPHASIS ON IMPACT EVALUATION.
REFERENCE: TEN STEPS TO A RESULTS-BASED MONITORING AND EVALUATION SYSTEM, BY JODY ZALL KUSEK AND RAY C. RIST (WORLD BANK, 2004).
DATA COLLECTION METHODS (FIGURE 4.3)
· CONVERSATION WITH CONCERNED INDIVIDUALS
· COMMUNITY INTERVIEWS
· FIELD VISITS
· REVIEWS OF OFFICIAL RECORDS (MANAGEMENT INFORMATION SYSTEM (MIS) AND ADMINISTRATIVE DATA)
· KEY INFORMANT INTERVIEWS
· PARTICIPANT OBSERVATION
· FOCUS-GROUP INTERVIEWS
· DIRECT OBSERVATION
· QUESTIONNAIRES
· ONE-TIME SURVEY
· PANEL SURVEYS
· CENSUS
· FIELD EXPERIMENTS
SAMPLE SURVEY ADDRESSES THE LAST FIVE METHODS
EVALUATION METHODOLOGIES
THE LOGICAL FRAMEWORK (“LOGFRAME”): AN ANALYTICAL TOOL USED TO PLAN, MONITOR AND EVALUATE PROJECTS.
ORIGINALLY DEVELOPED BY THE US DEPARTMENT OF DEFENSE, USED BY US AGENCY FOR INTERNATIONAL DEVELOPMENT SINCE THE 1960s. USED BY MANY INTERNATIONAL ASSISTANCE ORGANIZATIONS (US, CANADA, AUSTRALIA, UNITED KINGDOM, GERMANY, AND THE EUROPEAN UNION).
THE LOGFRAME IS A MATRIX:
|
Narrative Summary |
Objectively Verifiable Indicators |
Means of Verification |
Important Assumptions |
|
|
Goal |
||||
|
Purpose (or Objective) |
||||
|
Outputs |
||||
|
Activities |
Inputs |
(Source: “Engendering the Logical Framework,” by Helen Hambly Odame, International Service for National Agricultural Research (ISNAR), May 25, 2000.
THE BALANCED SCORECARD
PROPOSED BY ROBERT S. KAPLAN AND DAVID P. NORTON IN 1992: “THE BALANCED SCORECARD: MEASURES THAT DRIVE PERFORMANCE,” HARVARD BUSINESS REVIEW, JAN-FEB 1992, 71-79.
THE BALANCED SCORECARD (BSC) IS A MANAGEMENT SYSTEM (MANAGEMENT FRAMEWORK, PERFORMANCE MEASUREMENT SYSTEM), THAT BALANCES STRATEGIC OBJECTIVES / PERSPECTIVES:
· FINANCIAL PERSPECTIVE (“TO SUCCEED FINANCIALLY, HOW SHOULD WE APPEAR TO OUR SHAREHOLDERS”)
o RETURN ON CAPITAL
o RETURN ON SALES
o SALES GROWTH
o CUSTOMER VALUE ADDED
o HUMAN RESOURCES (EMPLOYEES)
· EXTERNAL CUSTOMER PERSPECTIVE (“TO ACHIEVE OUR VISION, HOW SHOULD WE APPEAR TO OUR CUSTOMERS”)
o CUSTOMER SATISFACTION
o CUSTOMER COMPLAINTS
o CUSTOMERS LOST / WON (MARKET SHARE)
o SALES FROM NEW PRODUCTS
o ON-TIME DELIVERY
· INTERNAL BUSINESS PROCESS PERSPECTIVE (“TO SATISFY OUR SHAREHOLDERS AND CUSTOMERS, WHAT BUSINESS PROCESSES MUST WE EXCEL AT?)
o ORDER CONVERSION RATE
o ON-TIME DELIVERY FROM SUPPLIERS
o COST OF NON-CONFORMANCE
o LEAD TIME REDUCTION
o QUALITY MANAGEMENT (STANDARDS, E.G., ISO 9000, CMM)
· LEARNING, GROWTH AND INNOVATION (“TO ACHIEVE OUR VISION, HOW WILL WE SUSTAIN OUR ABILITY TO CHANGE AND IMPROVE?)
o APPRAISALS COMPLETED ON TIME
o TRAINING PLANS COMPLETED
o NEW PRODUCT DEVELOPMENT ON TIME
THE BSC RECOGNIZES THAT MOST ASSETS OF ORGANIZATIONS TODAY ARE NOT FINANCIAL (PHYSICAL ASSETS), AND THAT CONCENTRATING ON FINANCIAL ACCOUNTING WILL NOT GUIDE MOST FIRMS TO WHERE THEY WANT TO GO.
THE CRITICAL MANAGEMENT PROCESSES ARE:
· CLARIFY AND TRANSLATE VISION AND STRATEGY
· COMMUNICATE AND LINK STRATEGIC OBJECTIVES AND MEASURES
· PLAN, SET TARGETS, AND ALIGN STRATEGIC OBJECTIVES
· ENHANCE STRATEGIC FEEDBACK AND LEARNING
ORIGINALLY DEVELOPED TO ASSIST COMMERCIAL BUSINESSES IN TRANSLATING STRATEGIC GOALS INTO ACTION, IT HAS NOW BEEN EMBRACED BY MANY PUBLIC INSTITUTIONS, INCLUDING STATE AND LOCAL GOVERNMENTS AND INTERNATIONAL ORGANIZATIONS.
REFERENCES ON THE BALANCED SCORECARD:
Kaplan, Robert S. and David P. Norton, The Balanced Scorecard: Translating Strategy into Action, Harvard Business School Press, 1996
Niven, Paul R., Balanced Scorecard Step-by-Step, John Wiley & Sons, 2002 (2nd edition 2006)
Niven, Paul R., Balanced Scorecard Step-by-Step for Government and Nonprofit Agencies, John Wiley & Sons, 2003
Nair, Mohan, Essentials of Balanced Scorecard, John Wiley & Sons, 2004
Bourne, Mike and Pippa Bourne, Balanced Scorecard in a Week, Hodder Arnold, 2000, 2002
EVALUATION GUIDELINES
THERE ARE MANY SOURCES OF INFORMATION ABOUT MONITORING AND EVALUATION ON THE INTERNET, INCLUDING:
http://www.cpc.unc.edu/measure
MAJOR EVALUATION GUIDELINES THAT MAY BE DOWNLOADED FROM THE INTERNET INCLUDE:
Monitoring and Evaluation: Some Tools, Methods and Approaches, The World Bank, 2004
National AIDS Councils’ Monitoring and Evaluation Operations Manual, The World Bank and United Nations, 2002
Handbook on Monitoring and Evaluating for Results, United Nations Development Programme, 2002
Handbook for Monitoring and Evaluation, International Federations of Red Cross and Red Crescent Societies, 2002
Many additional Internet sources for M&E guidelines are listed at the UNDP website, http://stone.undp.org/undpweb/eo/evalnet/docstore3/yellowbook/template/bibliography/bib_c.htm
THE VARIOUS MONITORING AND EVALUATION GUIDELINES DESCRIBE FRAMEWORKS FOR CONDUCTING EVALUATIONS. THEY IDENTIFY VARIOUS METHODOLOGIES, AND DISCUSS WHEN IT IS APPROPRIATE TO USE THEM. THEY PRESENT LITTLE METHODOLOGICAL INFORMATION ON HOW TO USE THEM (SUCH AS IS ADDRESSED IN THIS COURSE ON SAMPLE SURVEY).
2. MEASURES OF EFFECTIVENESS (MOEs)
· MISSION → GOALS → OBJECTIVES → MOEs
· PROBLEM IN MEASURING THE EFFECTIVENESS OF A PROGRAM:
o VALIDITY OF MEASURE (E.G., CHILDREN RETURNED HOME,
o CHANGE IN EARNINGS BEFORE AND AFTER PROGRAM)
o HAWTHORNE EFFECT
o SURVEY DESIGN PROBLEMS
· NEED CONTROLLED EXPERIMENT
· CONTROL OFTEN NOT POSSIBLE
o DENIAL OF SERVICES
o AWARENESS OF "TEST"
o NO CONTROL OVER EXOGENOUS VARIABLES
· INTERACTION VARIABLE OFTEN USED AS MEASURE OF EFFECTIVENESS
·
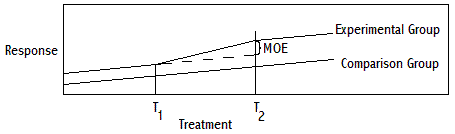
MOE = DIFFERENCE IN RESPONSE FOR EXPERIMENTAL AND COMPARISON GROUPS (INTERACTION OF TREATMENT WITH GROUP)
PRE-POST MEASURES OFTEN SUSPECT
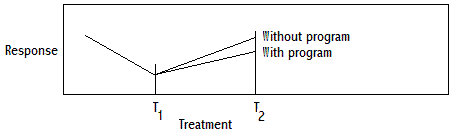
FOLLOW-UP MEASURES OFTEN SUSPECT
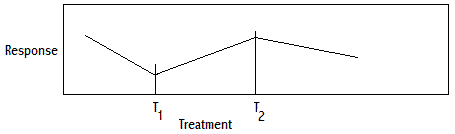
A KEY ASSUMPTION IS THAT THE UNIT RESPONSES ARE INDEPENDENT. ALSO REFERRED TO AS THE STABLE UNIT TREATMENT VALUE ASSUMPTION, THE PARTIAL-EQUILIBRIUM ASSUMPTION, THE NO-MACRO-EFFECTS ASSUMPTION, OR THE NO-DISPLACEMENT-EFFECTS ASSUMPTION
EXAMPLE: CLIENT GETS JOB, DISPLACES SOMEONE ELSE IN THE LABOR MARKET, NET IMPACT IS ZERO.
EXAMPLE: WAL-MART COMES TO TOWN, AND IT IS ADVERTISED AS SAVING EVERY FAMILY SEVERAL THOUSAND DOLLARS A YEAR, AND GENERATING EMPLOYMENT – BUT WHAT ABOUT THE EMPLOYEES OF ALL OF THE LOCAL HARDWARE STORES WHO NOW HAVE NO JOBS, OR WORK AT A FRACTION OF THEIR PREVIOUS SALARIES / WAGES.
EXAMPLE: EARLY MAMMOGRAMS CAUSED MORE BREAST CANCER THAN THEY DETECTED.
EXAMPLE: BETTER CRIME REPORTING / MONITORING SYSTEM APPEARS TO LEAD TO INCREASE IN CRIME.
3. RESEARCH DESIGN IN EVALUATION RESEARCH
· EXPERIMENTAL DESIGN IS RECOMMENDED (RANDOM ASSIGNMENT OF TREATMENTS TO UNITS)
· QUASI-EXPERIMENTAL DESIGNS AND NON-EXPERIMENTAL DESIGNS OFTEN USED IN SOCIAL SCIENCES RESEARCH FOR "PRACTICAL" REASONS:
o DENIAL OF TREATMENT OR SERVICES CONSIDERED UNETHICAL OR POLITICALLY INEXPEDIENT
o NO ADDITIONAL PEOPLE TO SERVE AS CONTROLS (PROGRAM SERVES ALL INTERESTED PERSONS)
o PARTICIPANTS MAY DROP OUT OF PROGRAM
o TREATMENT AND CONTROL GROUPS ARE LIKELY TO KNOW THEIR STATUS
· SAMPLE SURVEY OFTEN USED TO IMPLEMENT QUASI-EXPERIMENTAL DESIGNS -- AN "ANALYTICAL SURVEY"
o DESCRIBE RELATIONSHIPS BETWEEN NUMEROUS INTERVENING VARIABLES (E.G„ EDUCATION, AGE, EXPERIENCE, AND QUALITY OF SCHOOL ON EARNINGS)
o FPC IS IRRELEVANT -- WE WISH TO EVALUATE THE PROCESS GENERATING THE POPULATION NOT DESCRIBE THE CURRENT POPULATION
4. EXPERIMENTAL DESIGN vs SAMPLE SURVEY DESIGN
EXPERIMENTAL DESIGN IS CONCERNED WITH ESTABLISHING CAUSAL RELATIONSHIPS BETWEEN VARIABLES -- THE POPULATION UNDER STUDY IS FORMED BY THE EXPERIMENTER.
DESCRIPTIVE SURVEY DESIGN IS CONCERNED WITH DESCRIPTION OF A GIVEN POPULATION, AND THE MEASUREMENT OF ASSOCIATIONS BETWEEN CHARACTERISTICS IN THE POPULATION. IT IS CONCERNED WITH ESTIMATION OF POPULATION AND SUBPOPULATION CHARACTERISTICS OF INTEREST, SUCH AS MEANS AND TOTALS, NOT WITH TESTS OF HYPOTHESIS.
ANALYTICAL SURVEY DESIGN (“MODEL-BASED,” OR “MODEL-ASSISTED” DESIGN) IS CONCERNED WITH DEVELOPING A MODEL OF THE PROCESS THAT (HYPOTHETICALLY) GENERATED THE POPULATION AT HAND. IT IS CONCERNED WITH ESTIMATION OF RELATIONSHIPS AND TESTS OF HYPOTHESIS.
5. CHARACTERISTICS OF A GOOD EXPERIMENTAL DESIGN
HIGH INTERNAL VALIDITY: DID THE EXPERIMENTAL TREATMENTS MAKE A DIFFERENCE IN THE SPECIFIC EXPERIMENT?
HIGH EXTERNAL VALIDITY (GENERALIZABILITY): TO WHAT EXTENT CAN THE RESULTS OF THE EXPERIMENT BE GENERALIZED (TO OTHER POPULATIONS, SETTINGS, CONDITIONS)?
6. THREATS TO INTERNAL VALIDITY
(REFERENCE: DONALD T. CAMPBELL AND JULIAN C. STANLEY, EXPERIMENTAL AND QUASI-EXPERIMENTAL DESIGNS FOR RESEARCH, RAND McNALLY, 1963)
LACK OF CONTROL OF EXTRANEOUS VARIABLES
· HISTORY (EVENTS OCCURRING DURING THE COURSE OF THE EXPERIMENT)
· MATURATION (AGING)
· TESTING (EFFECTS OF TAKING ONE TEST ON SCORE OF A SECOND TEST)
· INSTRUMENTATION (CHANGES IN CALIBRATION, SCORERS)
· STATISTICAL REGRESSION EFFECTS (MOVEMENT OF GROUP MEAN SCORES CAUSED BY SELECTION 0N THE BASIS OF EXTREME SCORES)
· SELECTION BIAS (CHOOSING TREATMENT AND CONTROL GROUPS WITH DIFFERENT CHARACTERISTICS)
· EXPERIMENTAL MORTALITY (DIFFERENTIAL LOSSES FROM TREATMENT AND COMPARISON GROUPS)
· SELECTION - HISTORY (OR -MATURATION OR -TESTING) INTERACTION (EVENTS OCCURRING DURING THE COURSE OF THE EXPERIMENT FOR ONE OF THE COMPARISON GROUPS (E.G., THE EXPERIMENTAL AND QUASI-EXPERIMENTAL GROUPS) BUT NOT THE OTHERS
RANDOMIZATION OFFERS PROTECTION AGAINST ALL OF THESE THREATS TO INTERNAL VALIDITY.
7. REGRESSION EFFECT (MATCHING)
TEMPTATION: SELECT A COMPARISON GROUP THAT IS SIMILAR TO THE TREATMENT GROUP ON A NUMBER OF VARIABLES, AND COMPARE PERFORMANCE OF TWO GROUPS AT END OF PROJECT.
PROBLEM: IF THE SELECTION VARIABLES ARE UNRELIABLE PRE-MEASURES OF OUTCOME (E.G., A PRE-PROJECT READING SCORE), A COMPARISON GROUP SELECTED FROM THE GENERAL (MORE ABLE) POPULATION WILL AUTOMATICALLY IMPROVE, INDEPENDENT OF THE PROGRAM.
NOTE:
IN MATCHING IN AN EXPERIMENTAL DESIGN (PAIRED COMPARISONS) THE UNITS ARE MATCHED AND THEN RANDOMLY ASSIGNED TO THE TREATMENT AND CONTROL GROUPS.
REASON: THE PRETEST MEASURE CONTAINS AN ERROR TERM. 0N ANY PARTICULAR TESTING, SOME INDIVIDUALS WILL SCORE PARTICULARLY HIGH OR LOW. ON A RETEST, THE SCORES WILL TEND TO BE NEARER THE MEAN, HENCE, A COMPARISON GROUP SELECTED ON THE BASIS OF EXTREME SCORES WILL REGRESS TO THE MEAN.' INDEPENDENT OF THE PROGRAM EFFECT,
ILLUSTRATION OF THE REGRESSION EFFECT:
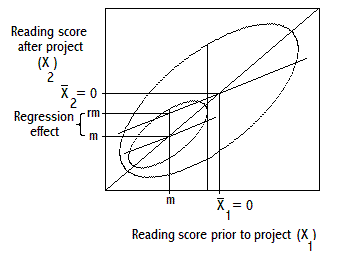
IN STANDARDIZED UNITS,
E(X2|X1) = rX1
IF r<1 AND X1<0 (THE MEAN, IN THIS EXAMPLE), THEN
E(X2|X1)>X1
REGRESSION EFFECT: A GROUP SELECTED ON THE BASIS OF AN IMPRECISE (UNRELIABLE) TEST SCORE (I.E., A SCORE CONTAINING RANDOM ERROR, THAT IS NOT PERFECTLY REPEATABLE) WILL TEND TO “REGRESS” TO THE MEAN UPON RETESTING, EVEN THOUGH NO CHANGE HAS OCCURRED IN THEIR ABILITIES OR THE ABILITIES OF THE GENERAL POPULATION. IF THE GROUP HAS BEEN SELECTED BASED ON LOW TEST SCORES, IT WILL TEND TO PERFORM BETTER (ON AVERAGE) UPON RETESTING. IF THE GROUP HAS BEEN SELECTED BASED ON HIGH TEST SCORES, IT WILL TEND TO PERFORM WORSE (ON AVERAGE) UPON RETESTING.
8. THREATS TO EXTERNAL VALIDITY
LACK OF "REPRESENTATIVENESS," OR GENERALIZABILITY:
· INTERACTION EFFECT OF PRETESTING (PRETEST MIGHT INCREASE OR DECREASE SENSITIVITY TO TREATMENT vs, UNPRETESTED POPULATION)
· INTERACTION EFFECTS OF SELECTION BIASES AND THE EXPERIMENAL VARIABLE (SELECTION BIASES DIFFERENT FOR DIFFERENT TREATMENT GROUPS)
· INTERACTION EFFECTS OF EXPERIMENTAL SETTING (EFFECTS DIFFERENT IN EXPERIMENTAL AND NON-EXPERIMENTAL SETTINGS)
· MULTIPLE TREATMENT INTERFERENCE (CARRY-OVER EFFECTS)
· LACK OF INDEPENDENCE OF UNIT RESPONSES MAY PREVENT THE EXTENSION OF THE SURVEY RESULTS TO THE ENTIRE POPULATION (STABLE UNIT TREATMENT VALUE ASSUMPTION, PARTIAL EQUILIBRIUM ASSUMPTION)
9. NON-EXPERIMENTAL DESIGN
ONE-SHOT CASE STUDY
X O
ONE-GROUP PRETEST-POSTTEST DESIGN
O X O
STATIC GROUP COMPARISON
X O
O
10. EXPERIMENTAL DESIGN
USES RANDOMIZATION TO ASSIGN MEMBERS TO EXPERIMENTAL AND CONTROL GROUPS
POSTTEST-ONLY CONTROL GROUP DESIGN:
![]()
PRETEST-POSTTEST CONTROL GROUP DESIGN:
![]()
(CAN’T MEASURE INTERACTION EFFECT OF TESTING WITH X)
SOLOMON FOUR-GROUP DESIGN:

(CAN MEASURE MAIN EFFECT OF TESTING AND INTERACTION OF TESTING WITH X)
PLUS MANY OTHERS.
11. QUASI-EXPERIMENTAL DESIGNS
TIME SERIES DESIGN
O O O O X O O O O
MULTIPLE TIME SERIES DESIGN
O O O X O O O O
O O O O O O O O
NONEQUIVALENT CONTROL GROUP
O X O
O O
· NO ATTEMPT TO MATCH ON PRETEST
· POSSIBLE MATCH ON BROAD RANGE OF SOCIO-DEMOGRAPHIC CHARACTERISTICS
PLUS MANY OTHERS.
12. SOURCES OF INVALIDITY FOR RESEARCH DESIGNS (REFERENCE: CAMPBELL AND STANLEY, OP. CIT.)
|
Sources of Invalidity for Research Designs |
|||||||||||||||||||||||
|
Sources of Invalidity |
|||||||||||||||||||||||
|
Internal |
External |
||||||||||||||||||||||
|
History |
Maturation |
Testing |
Instrumentation |
Regression |
Selection |
Mortality |
Interaction of Selection and Maturation, etc. |
Interaction of Testing and Treatment |
Interaction of Selection and Treatment |
Reactive Arrangements |
Multiple-Treatment Interference |
||||||||||||
|
Research Design |
|||||||||||||||||||||||
|
Pre-Experimental Designs |
|||||||||||||||||||||||
|
One-Shot Case Study X O |
x |
x |
x |
x |
x |
||||||||||||||||||
|
One-Group Pretest-Posttest Design O X O |
x |
x |
x |
x |
(x) |
x |
x |
x |
(x) |
||||||||||||||
|
Static-Group Comparison X O O |
(x) |
x |
x |
x |
x |
||||||||||||||||||
|
Experimental Designs |
|||||||||||||||||||||||
|
Pretest-Posttest Control Group Design R O X O R O O |
x |
(x) |
(x) |
||||||||||||||||||||
|
Solomon Four-Group Design R O X O R O R X O R O |
(x) |
(x) |
|||||||||||||||||||||
|
Posttest-Only Control Group Deisgn R X O R O |
(x) |
(x) |
|||||||||||||||||||||
|
Quasi-Experimental Designs |
|||||||||||||||||||||||
|
Time Series O O O O X O O O O |
x |
(x) |
x |
(x) |
(x) |
||||||||||||||||||
|
Multiple Time Samples Design O O O O X O O O O O O O O O O |
x |
x |
(x) |
x |
|||||||||||||||||||
|
Nonequivalent Control Group Design O X O O O |
(x) |
x |
x |
(x) |
(x) |
||||||||||||||||||
13. ANALYSIS OF DATA FROM QUASI-EXPERIMENTAL DESIGNS (NONRANDOMIZED COMPARISON GROUP)
1. STRAIGHTFORWARD COMPARISON OF MEANS -- NO GOOD ( REGRESSION .EFFECT)
2. ADJUSTMENT OF MEANS BY REGRESSION ANALYSIS OR ANALYSIS
OF COVARIANCE -- NO GOOD (USUALLY UNDERADJUSTS)
3. USE OF INTERACTION TERM TO REPRESENT TREATMENT EFFECT --
BEST PROCEDURE
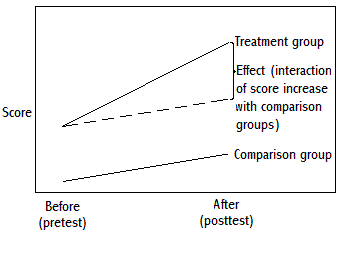
THIS APPROACH ESSENTIALLY AVOIDS THE ISSUE OF ATTEMPTING TO EXPLAIN THE LARGE DIFFERENCES IN MEANS BETWEEN THE TREATMENT AND COMPARISON GROUPS (WHETHER MATCHED OR NOT), AND USES THE DIFFERENCE IN CHANGES IN PERFORMANCE AS THE MEASURE OF EFFECTIVENESS.
STATISTICAL TERMINOLOGY: INTERACTION EFFECT OF TREATMENT AND TIME.
EVALUATION TERMINOLOGY: DOUBLE-DIFFERENCE ESTIMATE OF PROGRAM IMPACT; DIFFERENCE-IN-DIFFERENCE ESTIMATE OF PROGRAM IMPACT.
References on Monitoring and Evaluation
Streuning, Elmer L. and Marcia Guttentag, Handbook of Evaluation Research, vols. I and II, Sage Publications, 1975
Weiss, Carol H., Evaluation Research, Prentice-Hall, 1972
Suchman, Edward A., Evaluative Research, Russell Sage Foundation, 1967
Campbell, D. T. and J. C. Stanley, Experimental and Quasi-Experimental Designs for Research, Rand McNally, 1966
Cook, Thomas D. and Donald T. Campbell, Quasi-Experimentation: Design and Analysis Issues for Field Settings, Houghton Mifflin Company, 1979
Rubin, Allen and Earl Babbie, Research Methods for Social Work, 3rd edition, Brooks/Cole, 1997
Cochran, William G. and Gertrude Cox, Experimental Designs, 2nd edition, John Wiley and Sons, 1950, 1957
Kusek, Jody Zall and Ray C. Rist, Ten Steps to a Results-Based Monitoring and Evaluation System, World Bank, 2004
Klein, Robert E., et al., editors, Evaluating the Impact of Nutrition and Health Programs, Plenum Press, 1979
Schmidt, Richard E. Schmidt, John W. Scanlon and James B. Bell, Evaluability Assessment: Making Public Programs Work Better, Project Share Human Services Monograph Series Number 14, November 1979, Project Share, PO Box 2309, Rockville, MD 20852, US Department of Health, Education and Welfare, Office of the Secretary, Office of Assistant Secretary for Planning and Evaluation, DHEW Publication Number OS-76-130.
References on Econometric Analysis in Evaluation
Imbens, Guido W. and Jeffrey M. Wooldridge, “Recent Developments in the Econometrics of Program Evaluation,” Journal of Economic Literature, 2009, 47:1, pp 5-86.
Holland, Paul W. “Statistics and Causal Inference,” Journal of the American Statistical Association, Dec. 1986, Vol. 81, No. 396, Theory and Methods.
Rosenbaum, Paul R. and Donald B. Rubin, “The central role of the propensity score in observational studies for causal effects, Biometrika (1983), Vol. 70, No. 1, pp. 41-55.
Angrist, Joshua D. and Jörn-Steffen Pischke, Mostly Harmless Econometrics: An Empiricist’s Companion, Princeton University Press, 2009.
Lee, Myoung-Jae, Micro-Econometrics for Policy, Program and Treatment Effects, Oxford University Press, 2005.
Morgan, Stephen L. and Christopher Winship, Counterfactuals and Causal Inference: Methods and Principles for Social Research, Cambridge University Press, 2007
Pearl, Judea, Causality: Models, Reasoning and Inference, Cambridge University Press, 2000.
Wooldridge, Jeffrey M., Econometric Analysis of Cross Section and Panel Data, The MIT Press, 2002.
Rosenbaum, Paul. R., Observational Studies, 2nd edition, Springer, 2002, 1995.
Rubin, Donald B., Matched Sampling for Causal Effects, Cambridge University Press, 2006.
Additional Material on Sample Survey Design for Evaluation
Caldwell, Joseph George, “Sample Survey Design for Evaluation,” posted at http://www.foundationwebsite.org/SampleSureyDesignForEvaluation.pdf .
9.2 Instrumentation, Data Collection, and Survey Field Procedures
II. INSTRUMENTATION, DATA COLLECTION AND SURVEY FIELD PROCEDURES
A. SELECTION OF DATA COLLECTION PROCEDURES
TELEPHONE VS. MAIL VS. PERSONAL INTERVIEW
· INEXPENSIVE
· LOW RESPONSE RATES (OFTEN LESS THAN 50%)
TELEPHONE
· MODERATE COST
· SOME NONCOVERAGE
PERSONAL INTERVIEW
· USUALLY MOST VALID (NOT ALWAYS, E.G., CLIENT SATISFACTION SURVEY)
· VERY EXPENSIVE (E.G., $100 PER INTERVIEW)
DATA COLLECTION FORM APPLIED TO RECORDS
· HIGH COST, IF MANUAL SEARCH REQUIRED
USE OF SERVICE WORKERS NOT RECOMMENDED AS INTERVIEWERS
ON-LINE, OR WEB-BASED, SURVEYS (SURVEYS DISPLAYED ON THE INTERNET / WORLD WIDE WEB. FOR MUCH INFORMATION ON THIS TOPIC, SEE THE ONLINE SURVEY DESIGN GUIDE AT http://lap.umd.edu/survey_design/ . THIS IS A PROJECT OF THE LABORATORY OF AUTOMATION PSYCHOLOGY AND DECISION PROCESSES (LAP), FOUNDED IN 1983 BY DRS. KENT NORMAN AND NANCY ANDERSON AT THE UNIVERSITY OF MARYLAND. THIS GUIDE PROVIDES GOOD INFORMATION ABOUT QUESTIONNAIRE DESIGN IN GENERAL, NOT JUST FOR ON-LINE SURVEYS.
B. QUESTIONNAIRE DEVELOPMENT
1. QUESTION CONTENT
· SUBSTANTIVE THEORY GUIDES QUESTION CONTENT
· IN MANY SURVEYS, QUESTIONS HAVE HIGH FACE VALIDITY ("HOW OLD ARE YOU")
· IN SOME SURVEYS (E.G., LEVEL OF FUNCTIONING), MANY RELATED QUESTIONS ("DO YOU FEEL LONELY") "HOW OFTEN DOES SOMEONE VISIT YOU," ETC.)
· PERFORM ISSUES ANALYSIS; RELATE QUESTIONS TO ISSUES AND VICE VERSA
2. QUESTION ORDER
· LOGICAL FLOW
· GROUP SIMILAR QUESTIONS
· BREAK UP ALONG INTERVIEW INTO PARTS
· RAPPORT-BUILDING QUESTIONS FIRST
· SENSITIVE QUESTIONS LAST
3. QUESTION WORDING
· LEADING
· BIASED
· DIFFICULT TO UNDERSTAND
· AMBIGUOUS
· INFLAMMATORY
· PREVIOUSLY USED
4. QUESTION STRUCTURE/FORMAT
· OPEN VS, CLOSED
· NUMBER OF CATEGORIES
· OPINIONS - ODD OR EVEN?
· COMPARABILITY OF CATEGORIES WITH TRADITIONAL GOVERNMENT RESPONSE CATEGORIES
5. QUESTIONNAIRE LENGTH
· BURDEN
· NONRESPONSE
· VALIDITY
6. QUESTIONNAIRE LAYOUT
· SELF-CODING, IDENTIFIABLE
· CLEAR SKIP PATTERNS
· RESPONSE SHEETS
7. QUESTIONNAIRE INSTRUCTIONS
· INSTRUCTIONS/PROCEDURES
· PROBES
8. OPPORTUNITIES FOR INTERVIEWER COMMENT ON VALIDITY OF RESPONSE
9. RELIABILITY ANALYSIS (PSYCHOLOGICAL-TYPE QUESTIONNAIRES)
· ITEM-ITEM CORRELATIONS
· ITEM-TOTAL CORRELATIONS
· SPLIT-HALF RELIABILITY
· FACTOR ANALYSIS TO VERIFY GROUPING
· INTER-RATER RELIABILITY
· TIME-RELIABILITY
10. VALIDITY ANALYSIS
· CONSTRUCT VALIDITY
· COMPARISON TO “STANDARD”
· WHO PROVIDED ANSWERS
11. RELATE TO ANALYSIS PLAN
· ALL REQUIRED DATA ARE AVAILABLE
· NO UNUSED DATA
12. REVIEW
· BY INDEPENDENT PANEL (SUBSTANTIVE)
· BY DATA PROCESSING PERSONNEL
· BY CODING/EDITING PERSONNEL
C. DEVELOPMENT OF FIELD PROCEDURES
1. TREATMENT OF NONRESPONSE
· ENDORSEMENTS
· CONTACT BY HIGH-LEVEL PERSONNEL
· CALL-BACKS
· INCENTIVES FOR INTERVIEW TEAM
· DYNAMIC REVIEW OF RESPONSE RATES
2. IN-PLACE INTERVIEWERS OR TRAVELING TEAM
· INPLACE: LESS EXPENSIVE; LESS CONTROL
· TRAVELING TEAM: MORE EXPENSIVE; NOT ALWAYS SKILLED IN INTERVIEWING
D. PRETESTING AND PILOT TESTING
1. PRETESTING
CHECK FOR:
· AVAILABILITTY OF INFORMATION
· UNDERSTANDABILITY OF QUESTIONS
· CORRECT RESPONSE CATEGORIES
· LENGTH OF TIME TO ADMINISTER
· SMOOTHNESS OF FLOW
2. PILOT TEST
TEST OF:
· OPERATIONAL PROCEDURES (SAMPLE ASSIGNMENTS, TRANSMITTAL, LOGGING, CODING, EDITING)
· RESPONSE CATEGORIES
· RELIABILITY/VALIDITY TEST
E. EDITING, CODING, DATA BASE DESIGN AND DEVELOPMENT
1. MANUAL EDIT
CHECK FOR:
· IDENTIFICATION
· RESPONSE
· DATA TYPE (ALPHA OR NUMERIC)
· RANGE CHECKS
· REASONABLENESS
· CODE OPEN-ENDED QUESTIONS
2. CODING
· SELF-CODING FORM
· VERIFICATION
· MACHINE EDIT (CONSISTENCY CHECKS, RANGE CHECKS)
3. DATA BASE DESIGN AND DEVELOPMENT
· UPDATE FILE
· AUDIT TRAIL
· NONRESPONSE INDICATORS
· IMPUTATION (NOT RECOMMENDED)
· SAMPLE WEIGHTS
· MERGING WITH OTHER DATA
· HIERARCHICAL FILE (DISTRICTS, SCHOOLS)
· DATA DICTIONARY, CODE BOOK, TABLE KEYS (UNIQUE IDENTFIERS) AND RELATIONSHIPS
· DOCUMENTATION
9.3 Preparation of OMB Clearance Forms, Confidentiality and Privacy Issues
III. PREPARATION OF OMB CLEARANCE FORMS; CONFIDENTIALITY AND PRIVACY ISSUES
1. OMB CLEARANCE
· COLLECTION OF DATA FROM MORE THAN 9 RESPONDENTS
· GRANTS EXEMPTED
· TIME DELAY – 4 MONTHS
· PROCESS
· PROJECT OFFICER → AGENCY CLEARANCE → OMB CLEARANCE
· LEGAL CLEARANCES
· PRIOR CONTACT HELPFUL
· CLEARANCES FOR PRETEST INSTRUMENT AND FINAL INSTRUMENT, IF REVISED
ITEMS REQUESTED IN OMB CLEARANCE REQUEST PACKAGE
A. STANDARD FORM 83 A (2 COPIES)
B. CERTIFICATION BY AUTHORIZED OFFICIALS SUBMITTING REQUEST (3 COPIES OF THIS, AND THE FOLLOWING ITEMS)
C. SUMMARY OF SUPPORTING STATEMENT
D. SUPPORTING STATEMENT
1. JUSTIFICATION
· NATURE OF REQUIREMENT FOR DATA
· INTENDED USE OF DATA
· AVAILABILITY OF SIMILAR EXISTING DATA
2. DESCRIPTION OF SURVEY PLAN
· DESCRIPTION OF RESPONDENT UNIVERSE
· SURVEY DESIGN AND SAMPLING PLAN
· NAME OF AGENCY OR CONSULTING STATISTICIAN
· NAME AND ROLE OF CONTRACTOR, AND PROVISIONS FOR PROTECTING AND DISPOSING OF DATA FORMS
3. TABULATION AND PUBLICATION PLANS
· PLANS FOR PUBLICATION (TIME, TYPE, AND CONTENT)
· SUMMARY OF TABULATION PLANS
4. TIME SCHEDULE FOR DATA COLLECTION AND PUBLICATION
· PROJECT SCHEDULE
· TIME BETWEEN COMPLETION OF DATA COLLECTION AND ISSUANCE OF FINAL PUBLISHED RESULTS
5. CONSULTATIONS OUTSIDE THE AGENCY
· NAMES OF OUTSIDE CONSULTANTS, SUMMARY OF PROBLEMS
· DATA AVAILABILITY LEARNED FROM CONSULTATIONS
· CONSULTATION WITH STATE AND LOCAL GOVERNMENT OFFICIALS
6. ESTIMATION OF RESPONDENT REPORTING BURDEN
· BASIS FOR ESTIMATE OF RESPONDENT BURDEN
· TIME FOR COLLECTION AND COMPILATION OF DATA
· RANGE OF ESTIMATED BURDEN
7. SENSITIVE QUESTIONS
8. ESTIMATE OF COST TO FEDERAL GOVERNMENT
E. RELATED BACKGROUND AND DOCUMENTS
F. COPIES OF INSTRUMENTS AND FORMS (INCLUDING INSTRUCTIONS)
2. HINTS
· CAREFUL DEVELOPMENT OF SURVEY INSTRUMENTS
· CAREFUL DEVELOPMENT OF SURVEY DESIGN
· METICULOUS ATTENTION TO "INSTRUCTIONS FOR REQUESTING OMB APPROVAL UNDER THE FEDERAL REPORTS ACT"
· CONSIDERATION OF TERMS OF RELEVANT LEGISLATION, SUCH AS PRIVACY ACT OF 1974, FREEDOM OF INFORMATION ACT, AGENCY REGULATIONS
· COORDINATION WITH OMB CLEARANCE STAFF AND AGENCY CLEARANCE STAFF, BEFORE SUBMISSION OF CLEARANCE REQUEST FORM
· JUSTIFY THE STUDY
· JUSTIFY EACH DATA ELEMENT USED
PRIVACY ACT OF 1974
· RESTRICTIONS ON RELEASE OF INFORMATION
· NO SYSTEM OF RECORDS BASED ON SSN (EXCEPT FOR GRANTS)
· GUARANTEES OF CONFIDENTIALITY -- GET WORDING FROM LEGAL COUNSEL
9.4 Longitudinal Surveys
IV. LONGITUDINAL SURVEYS
1. REASON FOR LONGITUDINAL SURVEYS
· DIFFERENCE BETWEEN A LONGITUDINAL SURVEY AND A SERIES OF CROSS-SECTIONAL SURVEYS
· PURPOSE OF LONGITUDINAL SURVEY
o MEASUREMENT ON THE SAME INDIVIDUAL
§ PRECISE MEASURE OF CHANGE (CORRELATED OBSERVATIONS)
§ PRECISE ESTIMATES OF RELATIONSHIPS (DISAGGREGATED)
o ANALYSIS ON VARIABLES THAT CAN BE DEFINED ONLY BY HAVING MEASUREMENTS ON THE SAME INDIVIDUAL
2. PRECISION IMPROVEMENT FROM LONGITUDINAL SURVEYS
CORRELATION:
![]()
![]()
IF INDEPENDENT SAMPLES:
![]()
IF CORRELATED:
![]()
SO, VARIANCE OF CHANGES IS REDUCED.
BUT, VARIANCE OF MEAN LEVEL (OR TREND) IS LARGER, SINCE
![]()
3. ALLOCATION PROBLEM (PANEL SURVEY)
Q: HOW MANY INDIVIDUALS TO REPLACE IN SECOND SURVEY?
MAXIMUM PRECISION FOR ESTIMATING CHANGES/TRENDS: NONE
MAXIMUM PRECISION FOR ESTIMATING LEVEL: ALL
“BEST” SOLUTION MAY FALL SOMEWHERE IN BETWEEN, E.G., REPLACE 1/3 OF PANEL EACH TIME
4. BAYESIAN ESTIMATION
PRIOR DISTRIBUTION OF THE PARAMETER: ![]()
SAMPLING DISTRIBUTION: ![]()
POSTERIOR DISTRIBUTION OF THE PARAMETER:
![]()
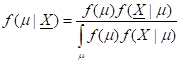
BAYES ESTIMATE: MEAN OF POSTERIOR DISTRIBUTION
5. TIME SERIES DESIGN
· MEASUREMENT OF POLLUTION LEVELS
· SPACING OF MEASUREMENTS
· TIME SERIES MODELS (ARIMA, BOX-JENKINS), INTERVENTION ANALYSIS
· OPTIMAL DESIGN OF CONTROL VARIABLE
· SPECTRAL ANALYSIS OF RESIDUALS
6. PROBLEMS IN LONGITUDINAL SURVEYS
· NONRESPONSE – CAN DESTROY THE VALUE OF OBSERVATIONS AT SEVERAL TIME PERIODS
· NONRESPONSE INCREASES IN TIME (LOCATION PROBLEMS)
· SAMPLE UNITS MAY CHANGE (E.G., SCHOOL DISTRICTS, CONGRESSIONAL DISTRICTS)
9.5 Sample Frame Problems
V. SAMPLE FRAME PROBLEMS
· INCOMPLETE
· DUPLICATION
· EXTRANEOUS ELEMENTS IN THE FRAME
· SAMPLING FROM MULTIPLE OVERLAPPING FRAMES
9.6. Sampling for Rare Elements
VI. SAMPLING FOR RARE ELEMENTS
· SCREENING
· CANVASS PRIMARY SAMPLING UNITS COMPLETELY
· NETWORK SAMPLING
· “SNOWBALL” SAMPLING OR REFERRAL SAMPLING (NONPROBABILITY)
9.7 Treatment of Nonresponse
VII. TREATMENT OF NONRESPONSE
A. DESIGN FOR NONRESPONSE
· NONRESPONSE BIAS
o NONRESPONDENTS MAY DIFFER FROM RESPONDENTS WITH RESPECT TO VARIABLES OF INTEREST, INTRODUCING A BIAS.
· SOURCES OF NONRESPONSE
o NOT AT HOME
o REFUSAL
o ILLNESS / INCAPACITY
o NOT LOCATED
o LOST INTERVIEW FORMS
· DESIGN PROCEDURES TO CONTROL FOR NONRESPONSE
o CALL-BACKS
o NONRESPONDENT SUBSAMPLING (E.G., TELEPHONE CALLS TO A SUBSAMPLE OF MAIL NONRESPONDENTS) (USE TWO-PHASE SAMPLING TO ADJUST RESULTS)
o POLITZ-SIMMONS’ PROCEDURE (ESTIMATE PROBABILITY OF BEING AT HOME)
o SUBSTITUTION: GENERALLY NOT RECOMMENDED (SUBSTITUTES RESEMBLE THE RESPONDENTS, NOT THE NONRESPONDENTS.)
o OVERSAMPLE TO COMPENSATE FOR LOSS OF SAMPLE (AND ASSOCIATED LOSS IN PRECISION)
B. ANALYSIS OF NONRESPONSE
· TYPES OF NONRESPONSE:
o MISSING OBSERVATIONS (OBSERVATION NONRESPONSE)
o MISSING VALUES (ITEM NONRESPONSE)
· FOR MISSING OBSERVATIONS:
o IF NONRESPONDENT SUBSAMPLING WAS USED, USE TWO-PHASE ESTIMATION PROCEDURE TO OBTAIN UNBIASED ESTIMATE
o FOR HARD-CORE NONRESPONSE, DETERMINE NONRESPONSE STRATA, RESPONSE RATES, MODIFY WEIGHTS
· FOR ITEM NONRESPONSE:
o DELETE INCOMPLETE ITEMS (NOT SATISFACTORY, UNLESS MOST OF ITEMS ARE MISSING)
o SUBSTITUTE MEAN VALUES (NOT RECOMMENDED)
o REGRESSION METHODS (ESTIMATE MISSING VALUE BASED ON OBSERVED RELATIONSHIPS TO USUALLY-AVAILABLE ITEMS)
o HOT-DECK PROCEDURES: REPLACE THE MISSING VALUE BY THE VALUE FROM A PREVIOUS RECORD (DISTRIBUTIONAL ROPERTIES PRESERVED)
NOTE: IN AN ANALYTICAL MODEL, COEFFICIENT ESTIMATES ARE UNBIASED IF NONRESPONSE EVENT IS INDEPENDENT OF MODEL ERROR TERM,
9.8 Nonsampling Errors
VIII. NONSAMPLING ERRORS
· TRUE VALUE
· OBSERVATIONAL ERROR
· REPORTING ERROR: RANDOM, SYSTEMATIC
· INTERVIEWER BIAS
· RELATIVE MAGNITUDE OF SAMPLING AND NONSAMPLING ERROR
· DIFFERENT MODELS FOR ESTIMATING AND TESTING FOR MEASUREMENT ERRORS
9.9 Randomized Response
IX. RANDOMIZED RESPONSE
USED FOR SENSITIVE QUESTIONS. THE INTERVIEWER DOES NOT KNOW IF THE RESPONDER IS ANSWERING THE SENSITIVE QUESTION OR ANSWERING AN INNOCUOUS QUESTION. THE QUESTION IS CHOSEN AT RANDOM.
9.10 Random Digit Dialing
X. RANDOM DIGIT DIALING
· UNRESTRICTED
· PLUS 1 METHOD
· WORKING BANK METHOD
· PPS METHODS
9.11 Major National and International Surveys
XII. MAJOR NATIONAL AND INTERNATIONAL SURVEYS
A. CURRENT POPULATION SURVEY (CPS)
THE CURRENT POPULATION SURVEY (CPS) IS A MONTHLY SURVEY OF HOUSEHOLDS CONDUCTED BY THE BUREAU OF CENSUS FOR THE BUREAU OF LABOR STATISTICS. IT PROVIDES A COMPREHENSIVE BODY OF DATA ON THE LABOR FORCE, EMPLOYMENT, UNEMPLOYMENT, PERSONS NOT IN THE LABOR FORCE, HOUSEHOLD CHARACTERISTICS.
THE CPS USES A SAMPLE OF 60,000 HOUSEHOLDS; DATA ARE COLLECTED BY PERSONAL AND TELEPHONE INTERVIEWS. BASIC LABOR FORCE DATA ARE GATHERED MONTHLY; DATA ON SPECIAL TOPICS ARE GATHERED IN PERIODIC SUPPLEMENTS.
CPS USES THE ROTATING PANEL METHOD OF INTERVIEWS. IT IS A MULTISTAGE CLUSTER SAMPLE.
B. NATIONAL HEALTH INTERVIEW SURVEY (NHIS)
OBTAINS COMPREHENSIVE STATISTICS ON DISEASES, INJURIES AND IMPAIRMENTS IN THE GENERAL POPULATION, DATA OBTAINED FROM HOUSEHOLD INTERVIEWS
THE NATIONAL HEALTH INTERVIEW SURVEY (NHIS) IS THE PRINCIPAL SOURCE OF INFORMATION ON THE HEALTH OF THE CIVILIAN NONINSTITUTIONALIZED POPULATION OF THE UNITED STATES AND IS ONE OF THE MAJOR DATA COLLECTION PROGRAMS OF THE NATIONAL CENTER FOR HEALTH STATISTICS (NCHS). THE NATIONAL HEALTH SURVEY ACT OF 1956 PROVIDED FOR A CONTINUING SURVEY AND SPECIAL STUDIES TO SECURE ACCURATE AND CURRENT STATISTICAL INFORMATION ON THE AMOUNT, DISTRIBUTION, AND EFFECTS OF ILLNESS AND DISABILITY IN THE UNITED STATES AND THE SERVICES RENDERED FOR OR BECAUSE OF SUCH CONDITIONS. THE SURVEY REFERRED TO IN THE ACT, NOW CALLED THE NATIONAL HEALTH INTERVIEW SURVEY, WAS INITIATED IN JULY 1957. SINCE 1960, THE SURVEY HAS BEEN CONDUCTED BY NCHS, WHICH WAS FORMED WHEN THE NATIONAL HEALTH SURVEY AND THE NATIONAL VITAL STATISTICS DIVISION WERE COMBINED.
WHILE THE NHIS HAS BEEN CONDUCTED CONTINUOUSLY SINCE 1957, THE CONTENT OF THE SURVEY HAS BEEN UPDATED ABOUT EVERY 10-15 YEARS. IN 1996 A SUBSTANTIALLY REVISED NHIS CONTENT BEGAN FIELD TESTING. THIS NEW QUESTIONNAIRE, DESCRIBED IN DETAIL BELOW, BEGAN IN 1997 AND IMPROVES THE ABILITY OF THE NHIS TO PROVIDE IMPORTANT HEALTH INFORMATION.
SAMPLE DESIGN. THE NATIONAL HEALTH INTERVIEW SURVEY IS A CROSS-SECTIONAL HOUSEHOLD INTERVIEW SURVEY. SAMPLING AND INTERVIEWING ARE CONTINUOUS THROUGHOUT EACH YEAR. THE SAMPLING PLAN FOLLOWS A MULTISTAGE AREA PROBABILITY DESIGN THAT PERMITS THE
REPRESENTATIVE SAMPLING OF HOUSEHOLDS. THE SAMPLING PLAN WAS REDESIGNED IN 1995. INFORMATION ABOUT THE SAMPLING PLAN GIVEN HERE COVERS THE DESIGN YEARS OF 1995-2004. THE FIRST STAGE CONSISTS OF A SAMPLE OF 358 PRIMARY SAMPLING UNITS (PSU'S) DRAWN FROM APPROXIMATELY 1,900 GEOGRAPHICALLY DEFINED PSU'S THAT COVER THE 50 STATES AND THE DISTRICT OF COLUMBIA. A PSU CONSISTS OF A COUNTY, A SMALL GROUP OF CONTIGUOUS COUNTIES, OR A METROPOLITAN STATISTICAL AREA.
WITHIN A PSU, TWO TYPES OF SECOND-STAGE UNITS ARE USED: AREA SEGMENTS AND PERMIT AREA SEGMENTS. AREA SEGMENTS ARE DEFINED GEOGRAPHICALLY AND CONTAIN AN EXPECTED EIGHT OR TWELVE ADDRESSES. PERMIT AREA SEGMENTS COVER GEOGRAPHICAL AREAS CONTAINING HOUSING UNITS BUILT AFTER THE 1990 CENSUS. THE PERMIT AREA SEGMENTS ARE DEFINED USING UPDATED LISTS OF BUILDING PERMITS ISSUED IN THE PSU SINCE 1990 AND CONTAIN AN EXPECTED FOUR ADDRESSES. WITHIN EACH SEGMENT ALL OCCUPIED HOUSEHOLDS AT THE SAMPLE ADDRESSES ARE TARGETED FOR INTERVIEW.
C. DEMOGRAPHIC AND HEALTH SURVEYS (DHS)
PROVIDES DATA FOR A WIDE RANGE OF MONITORING AND IMPACT EVALUATION INDICATORS IN THE AREAS OF POPULATION, HEALTH, AND NUTRITION.
DEMOGRAPHIC AND HEALTH SURVEYS (DHS) ARE NATIONALLY-REPRESENTATIVE HOUSEHOLD SURVEYS WITH LARGE SAMPLE SIZES (USUALLY BETWEEN 5,000 AND 30,000 HOUSEHOLDS). DHS SURVEYS PROVIDE DATA FOR A WIDE RANGE OF MONITORING AND IMPACT EVALUATION INDICATORS IN THE AREAS OF POPULATION, HEALTH, AND NUTRITION.
TYPICALLY, DHS SURVEYS ARE CONDUCTED EVERY 5 YEARS, TO ALLOW COMPARISONS OVER TIME. INTERIM SURVEYS FOCUS ON THE COLLECTION OF INFORMATION ON KEY PERFORMANCE MONITORING INDICATORS BUT MAY NOT INCLUDE DATA FOR ALL IMPACT EVALUATION MEASURES (SUCH AS MORTALITY RATES). THESE SURVEYS ARE CONDUCTED BETWEEN ROUNDS OF DHS SURVEYS AND HAVE SHORTER QUESTIONNAIRES THAN DHS SURVEYS. ALTHOUGH NATIONALLY REPRESENTATIVE, THESE SURVEYS HAVE SMALLER SAMPLES THAN DHS SURVEYS (2,000–3,000 HOUSEHOLDS).
SURVEY TYPES. DHS SUPPORTS A RANGE OF DATA COLLECTION OPTIONS THAT CAN BE TAILORED TO FIT SPECIFIC MONITORING AND EVALUATION NEEDS OF HOST COUNTRIES. LEARN MORE ABOUT THE TYPES OF SURVEYS, SECONDARY DATA ANALYSIS, AND SPECIALIZED STUDIES THAT MEASURE DHS PERFORMS.
DEMOGRAPHIC AND HEALTH SURVEYS (DHS): PROVIDES DATA FOR A WIDE RANGE OF MONITORING AND IMPACT EVALUATION INDICATORS IN THE AREAS OF POPULATION, HEALTH, AND NUTRITION.
AIDS INDICATOR SURVEYS (AIS): PROVIDE COUNTRIES WITH A STANDARDIZED TOOL TO OBTAIN INDICATORS FOR THE EFFECTIVE MONITORING OF NATIONAL HIV/AIDS PROGRAMS.
SERVICE PROVISION ASSESSMENT (SPA) SURVEYS: PROVIDES INFORMATION ABOUT THE CHARACTERISTICS OF HEALTH AND FAMILY PLANNING SERVICES AVAILABLE IN A COUNTRY.
KEY INDICATORS SURVEY (KIS): PROVIDES MONITORING AND EVALUATION DATA FOR POPULATION AND HEALTH ACTIVITIES IN SMALL AREAS—REGIONS, DISTRICTS, CATCHMENT AREAS—THAT MAY BE TARGETED BY AN INDIVIDUAL PROJECT, ALTHOUGH THEY CAN BE USED IN NATIONALLY REPRESENTATIVE SURVEYS AS WELL.
9.12 Statistical Software
XI. STATISTICAL SOFTWARE
AS MENTIONED IN THE INTRODUCTION, THIS PRESENTATION PRESENTS VERY LITTLE INFORMATION ABOUT STATISTICAL SOFTWARE PACKAGES. THE PRIMARY REQUIREMENT OF A STATISTICAL SOFTWARE PACKAGE FOR USE IN ANALYSIS OF SAMPLE SURVEY DATA IS THAT IT IN FACT BE ABLE TO PERFORM THE PROPER PROCEDURES FOR ANALYZING SURVEY DATA. THERE IS A LARGE NUMBER OF STATISTICAL PACKAGES AVAILABLE, AND SOME OF THEM ARE DESIGNED ONLY FOR ANALYSIS OF SIMPLE RANDOM SAMPLES, NOT FOR ANALYSIS OF COMPLEX SURVEY DATA.
THE MAJOR STATISTICAL PROGRAM PACKAGES THAT INCLUDE CAPABILITIES FOR ANALYSIS OF SAMPLE SURVEY DATA ARE:
R
Stata
SAS
SPSS (COMPLEX SAMPLES MODULE)
SUDAAN
THE FIRST FOUR SYSTEMS ARE GENERAL STATISTICAL PROGRAM PACKAGES THAT INCLUDE CAPABILITIES TO ANALYZE COMPLEX SURVEY DATA. R IS AVAILABLE FREE (GNU GENERAL PUBLIC LICENSE). SAS AND SPSS ARE VERY EXPENSIVE. Stata IS REASONABLY PRICED. SUDAAN IS SPECIFIC TO COMPLEX SURVEYS.
TWO MAJOR FREE PROGRAMS FOR DATA ENTRY OF SURVEY DATA ARE THE CENSUS AND SURVEY PROCESSING SYSTEM (CSPro, DEVELOPED BY THE US BUREAU OF THE CENSUS) AND EPI Info (DEVELOPED BY THE US CENTERS FOR DISEASE CONTROL AND PREVENTION. BOTH PROGRAMS INCLUDE DATA PROCESSING AND ANALYSIS CAPABILITIES.
9.13 Survey Documentation
XII. SURVEY DOCUMENTATION
SURVEY DOCUMENTATION INVOLVES MUCH MORE THAN PRESENTATION OF THE STATISTICAL ANALYSIS OF THE COLLECTED DATA. IT REQUIRES DETAILED DOCUMENTATION OF THE SURVEY PROCESS, AND ARCHIVING AND DOCUMENTATION OF THE COLLECTED DATA IN A WAY THAT ENABLES OTHER RESEARCHERS TO VERIFY, VALIDATE AND EXPAND THE ANALYSIS.
GOOD EXAMPLES OF SURVEY DOCUMENTATION ARE THE REPORT PRESENTED BY THE NATIONAL CENTER FOR HEALTH STATISTICS AND THE DEMOGRAPHIC AND HEALTH SURVEYS FUNDED BY THE US AGENCY FOR INTERNATIONAL DEVELOPMENT.
HERE FOLLOWS AN EXAMPLE OF ITEMS THAT SHOULD, AT A MINIMUM, BE INCLUDED IN SURVEY DOCUMENTATION. THIS EXAMPLE IS TAKEN FROM A SURVEY FUNDED BY THE MILLENNIUM CHALLENGE CORPORATION (IN THE PUBLIC DOMAIN).
Documentation of Analysis
The questionnaires for the FTDA and transportation surveys are similar, and a single basic analysis plan will be presented for both surveys. The main difference between the evaluation designs is the fact that the model for the FTDA evaluation is a pretest-posttest / control-group design and the model for the Transportation evaluation is an analytical model in which changes in travel times to various points of interest are the principal measures of program intervention (indication of treatment level). The analysis procedures will be similar for both surveys, but the variables included in the models and the model structural specification will be different.
The Stata statistical analysis program package (Version 10.0) will be used for the analysis. The data for the FTDA and Transportation surveys were provided to NORC by the Honduran Instituto Nacional de Estadistica (INE) in the form of SPSS data files. One of the first steps in the data analysis effort is conversion of the SPSS data files to Stata data files.
Most of the data to be used in evaluation of the FTDA and Transportation Projects come from household surveys conducted near the beginning and end of the evaluation project. The data sets for the FTDA and Transportation surveys each contain about a dozen files. The file names assigned by INE will be used. The data sets will be stored in two Microsoft Windows folders, named DataAnalysis/FTDAHHSurvey and DataAnalysis/TranHHSurvey.
In addition to the FTDA and Transportation household surveys, there are two other sample surveys involved in this evaluation project: a traffic survey and a measurement-error survey. This Analysis Plan will focus on the FTDA and Transportation surveys. The traffic survey data will be used to support impact analysis and calibration of the GIS model used to estimate travel times for the Transportation household survey. The measurement-error survey will be used in support of analysis of the FTDA household survey data. Separate survey reports will not be prepared for the traffic and measurement-error surveys: the results of those surveys will be used directly in the analysis of the FTDA and Transportation household-survey data.
All of the analysis will be documented in Stata “Do” (command, .do) files, liberally embedded with comments to describe what analysis is being done. Each .do file will contain a header (series of comments at the beginning) that specifies the following (in English or Spanish), for example:
version 10.0
set more off
clear
capture log close
*In the following line, specify the name of the folder in which the data files are located.
global direct1 "C:\DataAnalysis\TranHHSurvey\"
log using "$direct1\Do12TranEstimation.log", replace
*Place file header following the preceding statement, so it shows up in the log file.
*File name: Do12TranEstimation.do
*Project: MCA-H Transportation Program Evaluation
*Creator: Joseph Caldwell
*Date created: 16 August 2011
*Modifier: Joseph Caldwell
*Date modified: 22 August 2011
*Purpose: Estimate impact for MCA-H Transportation program.
*Input file: Tran_MCA_HONDURAS_HOGARES_RONDA1y2.dta.
*Output files: TranEstimation.dta
*Log file: Do12TranEstimation.log
*Repeat, as comments, commands prior to turning log on:
*version 10.0
*set more off
*clear
*capture log close
*In the following line, specify the name of the folder in which the data files are located.
*global direct1 "C:\DataAnalysis\TranHHSurvey\"
*log using "$direct1\Do12TranEstimation.log", replace
Since the .do files will be stored in the same folder as the dataset, there is no real need to include the program name (FTDA or Transportation) in the file name (e.g., Do14FTDAEstimation.do or Do12TranEstimation.do). Nevertheless, to minimize the risk of confusion or mistakes, the program name will be included in the file name.
Archived (saved, backup) versions of the .do files will contain the date as a suffix to the name (prior to the extension .do), in the format yyyymmdd.
The number following “Do” in the file name (e.g., Do01…) indicates the order of executing the .do files to reproduce the complete analysis.
The purpose of creating and maintaining the .do files is (1) to establish documentation of the survey data analysis; (2) to reduce the effort involved in analyzing the data, by making it easy to re-run or modify prior analyses; (3) to minimize rework, in the case of data edits (so that the analysis can be rerun immediately, simply by replacing the data set and executing the .do file); and (4) to facilitate the analysis of the data sets by several individuals. The sequence numbers used in the .do files (e.g., Do12…) will be assigned by the individual in charge of the data analysis.
Collectively, the .do files are to include the entire analysis, so that any person having Stata (version 10.0 or later) installed on his computer can execute them and replicate the entire analysis. The complete analysis generated by a particular .do file will appear in the log file specified in the .do file header. The .do files will be “modular,” i.e., address a single aspect of the analysis (e.g., several files for preprocessing and aggregating the raw data, a file for descriptive analysis, and a file for impact estimation (model-based analysis)).
In addition to the commentary in the .do files, a “ReadMe” file will be included in each folder (e.g., ReadMeFTDARound1&2FlatFile for the file that forms a household-level table (“flat file”) for the FTDA survey). The ReadMe file will include a summary description of the analysis (presented in the .do files), and general remarks that pertain to all or subsets of the .do files. The data files and accompanying documentation, the .do files, the ReadMe file and whatever other files are generated by the .do files (data files, logs) will comprise the complete technical documentation of the survey data analysis.
The commenting presented in the various .do files should be sufficiently complete and clear that no additional documentation of the analysis is required, although some summary description of what was done may be presented in the ReadMe files and project reports. Whatever summary description is presented in reports will refer to these files for additional details.
Descriptive Summary of Sample Data
Prior to embarking on analysis of the data, a descriptive summary of the sample data will be prepared. This summary will present information on unit and item nonresponse, and describe the overall characteristics of the sample. It is not the purpose of the descriptive summary to conduct a formal statistical analysis of the data, based on a survey design model or a causal model. In general, the descriptive summary will not use survey “weights” – most tabular results will simply be unweighted sample tallies and estimates, and estimates of standard errors will not be presented. In some cases, weights may be used when comparing treatment and comparison populations.
The following is a list of the items to be accomplished in the descriptive summary of the sample data. The descriptive analysis will be done only at the household level, not at the level of individual persons, crops, income and expense components, or other items included in the household questionnaire.
1. Map of Data. Plot all sample unit locations on an ArcGIS map (along with the program roads, for the transportation program). This is done separately for the FTDA and Transportation Projects.
2. Unit nonresponse. Calculate the proportion of sample units responding (i.e., with completed interviews). Categorize the unit nonresponse (questionnaire nonresponse) by reason (e.g., could not locate, not at home, moved, refused, questionnaire lost or destroyed). Note variables that are correlated with unit nonresponse (e.g., municipality, farm size, interviewer). This is done by project, by survey round, and by treatment level.
3. Item nonresponse. Define nonresponse indicator variables for each variable (if not already done), e.g., “don’t know,” “refused to answer,” “out of legitimate range,” “not available” and “otherwise missing”. Note variables having substantial nonresponse, and note variables that are correlated with unit nonresponse. This is done by project, by survey round, and by treatment level.
4. Summaries for Continuous Variables. For interval-scale variables, calculate the mean (or proportion), median, minimum, maximum, range, quintiles, variance, standard deviation and histogram for each variable (for all responses and for valid responses, separately). Identify outliers (extreme values) and inconsistent values. This is done by project, by survey round, and by treatment level.
5. Summaries for Discrete Variables. For categorical variables, calculate the minimum, maximum, range, and histogram for each variable (for all responses and for valid responses, separately). This is done by project, by survey round, and by treatment level.
6. Classification of Variables into Response and Explanatory. Classify each variable (of the questionnaire) as a dependent (explained) variable (e.g., income, employment) or an independent (explanatory) variable (e.g., treatment for FTDA, estimated change in travel time for Transportation, age, education, gender, experience, farm size, crop type, technology type). This classification is based on anticipation of the likely structure of causal models to be used in the analysis. This is done by project, by survey round, and by treatment level.
7. Crosstabulations and Tables of Means for the FTDA Survey Data. For the FTDA survey data, construct crosstabulations (counts, proportions) and tables of means to summarize the data by treatment level (treatment and control, as defined at the aldea level and farmer level (treatment farmer or potential treatment farmer or other)) and survey round. These are unweighted tables, with no adjustment for design, without estimates of standard errors.
8. Crosstabulations and Tables of Means for the Transportation Survey Data. For the Transportation survey data, construct crosstabulations (counts, proportions) and tables of means to summarize the data by treatment level (change in travel time, categorized by quintile) and survey round. These are unweighted tables, with no adjustment for design, and without estimates of standard errors.
Outline of Reports
A separate evaluation report will be prepared for each project (the FTDA household survey and the Transportation household survey). Brief summary reports will be prepared for each of the smaller surveys done in conjunction with these surveys (i.e., the traffic survey and the measurement-error survey). The format and content of the reports will be similar to those presented in the Demographic and Health Surveys funded by the U. S. Agency for International Development (and described at the Wikipedia page http://en.wikipedia.org/wiki/Demographic_and_Health_Surveys). Examples of these reports are the Honduras 2005 Demographic and Health Survey (in Spanish)
http://www.measuredhs.com/pubs/pdf/FR189/FR189.pdf and the Ghana 2003 Demographic and Health Survey (in English) http://www.measuredhs.com/pubs/pdf/FR152/FR152.pdf. Examples of other surveys are presented at the Measure DHC Demographic and Health Surveys website, at http://www.measuredhs.com/.
Here follows a proposed outline for the evaluation reports for the FTDA and Transportation Projects.
Title Page
Preface
Table of Contents
List of Tables
List of Figures
List of Acronyms and other Abbreviations
List of Symbols
Executive Summary
Map of Honduras
Chapter 1, Introduction: Purpose of Project and This Report; Summary of Report Contents
Chapter 2, Evaluation Design and Project Implementation
Chapter 3, Summary of Household Survey
Introduction
Sample Design
Questionnaires
Training and Field Work
Data Processing
Response Rates
Chapter 4, Characteristics of Households and Respondents
Chapter 5, Estimation of Program Impact
References
Appendix A, Evaluation Design, Sample Design and Implementation
Appendix B, Quality of the Data: Nonsampling Errors
Appendix C, Impact Estimates and Estimates of Standard Errors
Appendix D, Survey Personnel
Appendix E, Questionnaires (including field instructions), bound separately.
DATA QUALITY
THE BOOK, MODEL ASSISTED SURVEY SAMPLING BY CARL-ERIC SÄRNDAL, BENGT SWENSON AND JAN WRETMAN (SPRINGER, 1992) PRESENTS INFORMATION ON DATA QUALITY.
ONE OF THE IMPORTANT PARTS OF THE SURVEY DOCUMENTATION IS THE PRODUCTION OF AN ERROR PROFILE, AS DESCRIBED IN THE FOLLOWING DOCUMENT:
Statistical Policy Working Paper 3, An Error Profile: Employment as Measured by the Current Population Survey, U. S. Department of Commerce Office of Federal Statistical Policy and Standards, 1978 (for sale by U. S. Government Printing Office)
SÄRNDAL ET AL. LIST THE FOLLOWING STAGES OF AN ERROR PROFILE:
1. Sampling design
a. Frames
b. Sample selection
c. Quality control of sampling process
2. Observational design
a. Data collection procedure
b. Questionnaire design
c. Data collection staff
d. Interviewer training
e. Quality control of field work
3. Data preparation design
a. Data input operations
b. Cleaning, editing and imputation
c. Quality control of data processing
4. Production of estimates
a. Weighting procedure,
b. Estimation procedure
c. Quality control of estimation procedure
5. Analysis and publication
SÄRNDAL ET AL. LIST THE FOLLOWING ITEMS AS THE MINIMUM REQUIRED BY THE 1982 MEETING OF THE CONFERENCE OF EUROPEAN STATISTICIANS IN SUMMARY QUALITY PRESENTATIONS:
1. Basic information on the data source and on definitions (including classifications).
2. Coverage of the data (for example, adequacy of the sample frame).
3. Short description of the selection and estimation methods.
4. Response rates (including their definition).
5. Sampling error (when applicable) and indication of how the computed standard errors and related measures should be interpreted.
6. Indication of the size and direction of the likely major errors and of their relative importance and impact on the statistics.
7. Information on significant changes in procedures and on other factors that would affect the comparability of statistics over time.
8. Information (if any) on the comparability with statistics on the same subject compiled from other sources.
9. References to the availability of more detailed technical descriptions (for example, technical reports).
SÄRNDAL ET AL DESCRIBE STATISTICS CANADA'S POLICY ON INFORMING USERS OF DATA QUALITY AND METHODOLOGY.
PRIOR TO UNDERTAKING ANY LARGE-SCALE EVALUATION, AN EVALUABILITY ASSESSMENT SHOULD BE UNDERTAKEN. THIS METHODOLOGY IS DESCRIBED IN THE FOLLOWING DOCUMENT:
Schmidt, Richard E, John W. Scanlon and James B. Bell, Evaluability Assessment: Making Public Programs Work Better, Project Share (A National Clearinghouse for Improving the Management of Human Services), Human Services Monograph Series Number 14, November 1979 (available from U. S. Department of Health and Human Services, DHEW Publication No. OS-76-130).
IT IS RECOMMENDED THAT THE RESULTS OF THE EVALUABILITY ASSESSMENT (CONDUCTED PRIOR TO THE SURVEY) BE INCLUDED AS PART OF THE SURVEY DOCUMENTATION (REFERENCED AS A TECHNICAL REPORT).
FndID(209)
FndTitle(Sample Survey Design and Analysis: A Comprehensive Three-Day Course, with Application to Monitoring and Evaluation. Day One.)
FndDescription(Sample Survey Design and Analysis: A Comprehensive Three-Day Course, with Application to Monitoring and Evaluation. Day One.)
FndKeywords(statistical methods; monitoring and evaluation; statistics course; short course; sample survey; causal inference; statistical design and analysis; sample size determination)